数据集下载:链接:https://pan.baidu.com/s/16gohErShMpG0lP4EmdYrYg 提取码:01j0
算法简介
K-Means也称为K均值,是一种聚类(Clustering)算法。聚类属于无监督式学习。它可以根据数据特征将数据集分成K个不同的簇,簇的个数K是由用户指定的。K-Means算法基于距离来度量实例间的相似程度,然后把较为相似的实例划分到同一簇。
距离的度量
K-Means算法一般采用欧式距离公式进行距离的度量,其定义为: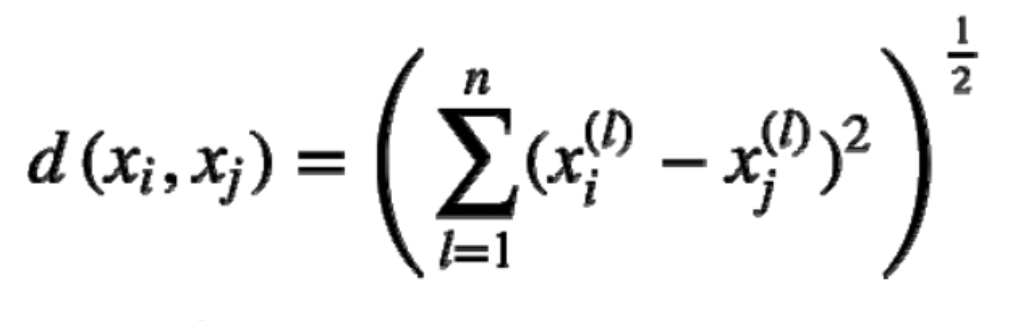
算法流程
KMeans算法先假设K个簇的质心点,然后根据就近原则将数据集中的实例划入各簇,之后每一个簇根据簇内实例重新计算当前实际质心点,如果假设的质心点与当前实际的质心点不符,则再以当前实际质心点作为假设的质心点重复上述过程,直到相符为止。K-Means算法流程如下:
(1)随机产生K个簇的质心点(可在合理范围内随机生成或在训练实例中随机抽取)。
(2)对于数据集 中的每个实例
中的每个实例 ,分别计算到各簇质心点的距离,将划分到与其距离最近的质心点所代表的簇。
,分别计算到各簇质心点的距离,将划分到与其距离最近的质心点所代表的簇。
(3)所有实例划分到各簇后,各簇使用簇内实例重新计算质心点。
(4)重复步骤(2)和(3),直到各簇质心点不再变动(或变化很小)或迭代到指定次数。需要注意的是,K-Means算法未必能收敛到全局最优解,有可能收敛于一个局部最优解。
算法实现—python
数据准备
# 将文本数据转换为csv数据,便于后面pands和numpy计算import csvpath = "C:/Users/ASUS/Desktop/aa/xigua.txt"data = []with open(path,'r') as f:data = f.read().split('\n')path2 = "C:/Users/ASUS/Desktop/aa/xigua.csv"with open(path2,'w', newline='') as fp:fp_write = csv.writer(fp)for d in data:fp_write.writerow(d.split(',')[1:3])
导入所需的第三方库
# 导入所需要的第三方库import numpy as npimport pandas as pdimport randomimport mathimport matplotlib.pyplot as plt
导入样本数据并随机选取初始的质心点
def read_data(path):dots = pd.read_csv(path)dots = np.array(dots).tolist()return dotsdef create_centers(k, dots):#centers = random.sample(dots,k) # 随机选取初始质心点centers = [[0.403,0.237],[0.343,0.099],[0.478,0.437]] # 此处先按照西瓜书上的例子固定第一次的质心点centers = np.array(centers)return centersdef Init_centers_random(path, k):dots = read_data(path)centers = create_centers(k,dots)return dots, centers # dots为样本数据、 centers为质心点
计算各个样本点到质心点的距离
def twoPointLength(dot,center):# 欧氏距离公式dot为样本点、center为质心点length = math.sqrt((dot[0]-center[0])**2 + (dot[1]-center[1])**2 )return lengthdef computeDistances(dots, centers):distances = [] # 该列表用于存储各样本点到质心点的距离,所有该列表因为二维列表for dot in dots: # 遍历质心点distance = [] # 该列表用于存储每个质心点到三个样本点的距离,为一维列表for center in centers:d = twoPointLength(dot,center)distance.append(d)distances.append(distance)return distances
把到质心点距离最小的样本分为一个类
def classify(distances, dots):labels = [] # 分类标签列表,分为几个簇,该列表中就应有几个元素(列表)for i in range(len(distances[0])):label = [] # 该列表用于存储属于同一簇的的样本点j = 0for distance in distances:if min(distance) == distance[i]: # 选出距离最小值,一次在第0,1,2,..k位置处的样本点label.append(dots[j]) # 将选出的样本点加入列表,比如 i = 0 时,一直要将0索引处距离值最小的样本点全部添加到该标签列表中j = j + 1labels.append(label)return labels
迭代分类
def step2(dots, centers):distances = computeDistances(dots,centers)labels = classify(distances,dots)return labelsdef newCenters(labels):centers = []for label in labels:label = np.array(label) # 将列表转换为数组便于计算# print(label)centers.append(label.mean(axis=0)) # 新的样本点通过求各个簇内(标签列表内)所有样本点的均值得到# [[1 2][3 4] [5 6] ... [2n-1, 2n]]# axis = 0, 按列求均值: 新样本带点的第一个参数: (1 + 3 + 5 +...+2n-1) / n , 新样本点的第二个参数同理可得。return centers
数据显示
def drawDots(labels, centers):for j in range(len(centers)): # 簇的个数plt.plot([x[0] for x in labels[j]], [y[1] for y in labels[j]], '*') # 绘制样本点plt.plot(centers[j][0],centers[j][1], '^') # 绘制质心点plt.xlabel("density") # 密度plt.ylabel("sugercontent") # 含糖率plt.title("K-Means Cluster")plt.show()
函数调用
def k_means(k,path,max_iter):dots, centers = Init_centers_random(path,k)labels = step2(dots, centers)drawDots(labels, centers)while max_iter > 0:centers = newCenters(labels)labels = step2(dots, centers)max_iter= max_iter - 1drawDots(labels, centers)k = 3max_iter = 1000path = 'C:/Users/ASUS/Desktop/aa/xigua.csv'k_means(k,path,max_iter)
实验结果
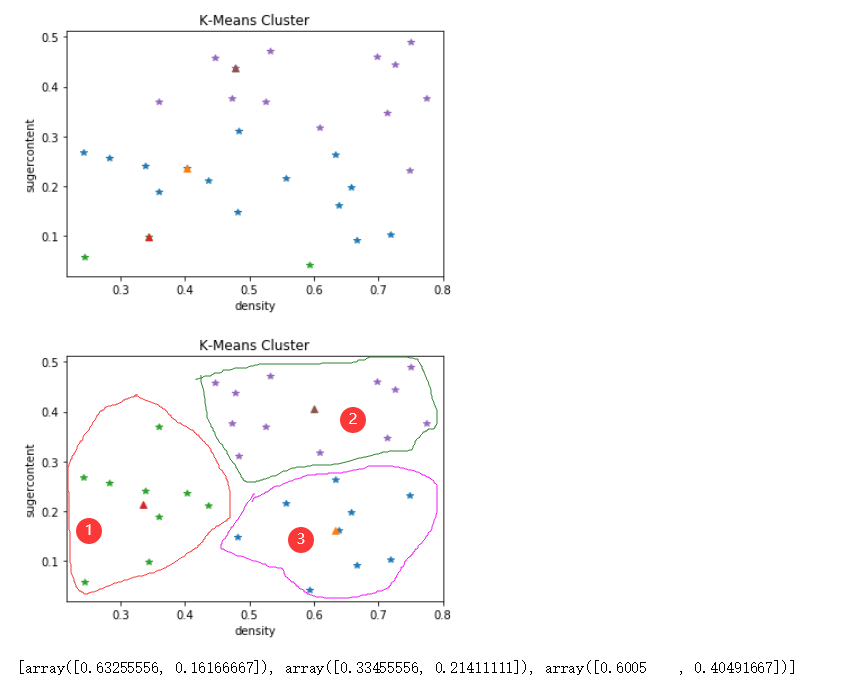
算法实现—sklearn
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.cluster import KMeansxigua = pd.read_csv('C:/Users/ASUS/Desktop/aa/xigua.csv')estimator = KMeans(n_clusters=3, max_iter=4,)#计算每个样本的聚类中心并预测聚类索引。a1=xigua.values# print(a1[:,0:3])res = estimator.fit_predict(a1[:,0:3])#每个点的标签lable_pred = estimator.labels_#每个点的聚类中心centroids = estimator.cluster_centers_#样本距其最近的聚类中心的平方距离之和。inertia = estimator.inertia_# print (lable_pred)# print (centroids)# print (inertia)for i in range(len(a1)):if int(lable_pred[i]) == 0:plt.scatter(a1[i][0], a1[i][1], color='red')plt.scatter(centroids[0][0],centroids[0][1], color='green')if int(lable_pred[i]) == 1:plt.scatter(a1[i][0], a1[i][1], color='black')plt.scatter(centroids[1][0],centroids[1][1], color='green')if int(lable_pred[i]) == 2:plt.scatter(a1[i][0], a1[i][1], color='yellow')plt.scatter(centroids[2][0],centroids[2][1], color='green')plt.show()
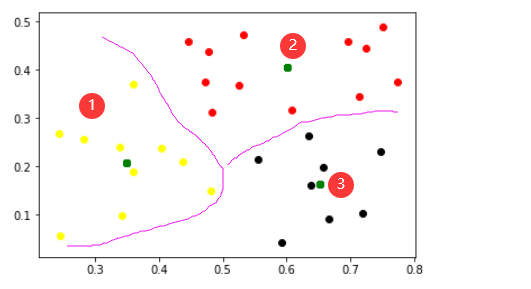
参考内容:
1 . Python机器学习算法:原理、实现与案例/刘硕著.—北京:清华大学出版社,2019
2 . 机器学习/周志华著. —北京: 清华大学出版社,2016(2018.8重印)
3 . https://baijiahao.baidu.com/s?id=1643526033545278510&wfr=spider&for=pc
4 . https://www.cnblogs.com/dudu1992/p/8954020.html

若有收获,就点个赞吧
0 人点赞
