- 分布式训练架构
- 分布式训练 API
- 分布式 program 的构建
- 通信相关 OP
-
- save_op
分布式训练架构
分布式分为模型并行和数据并行,其中数据并行的模型有2种通信模式:RPC通信和Collective通信。RPC具体实现是gRC,Collective 使用 NCCL2。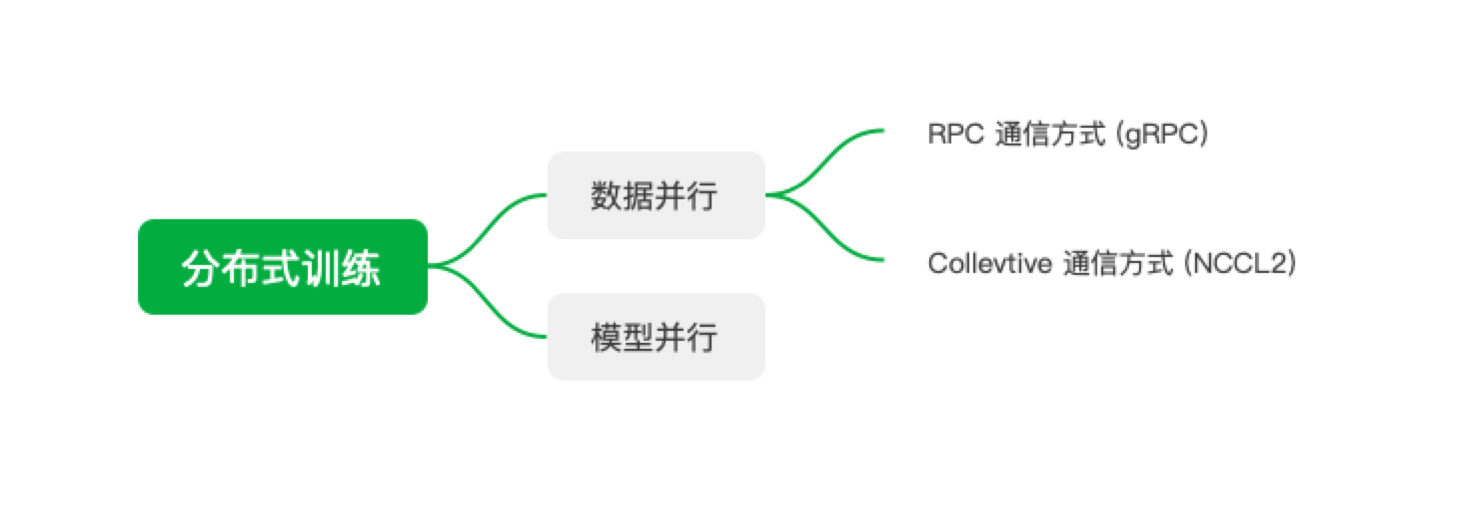
数据并行
数据并行的方式,分布式训练集群中有2个角色——Pserver和 Trainer。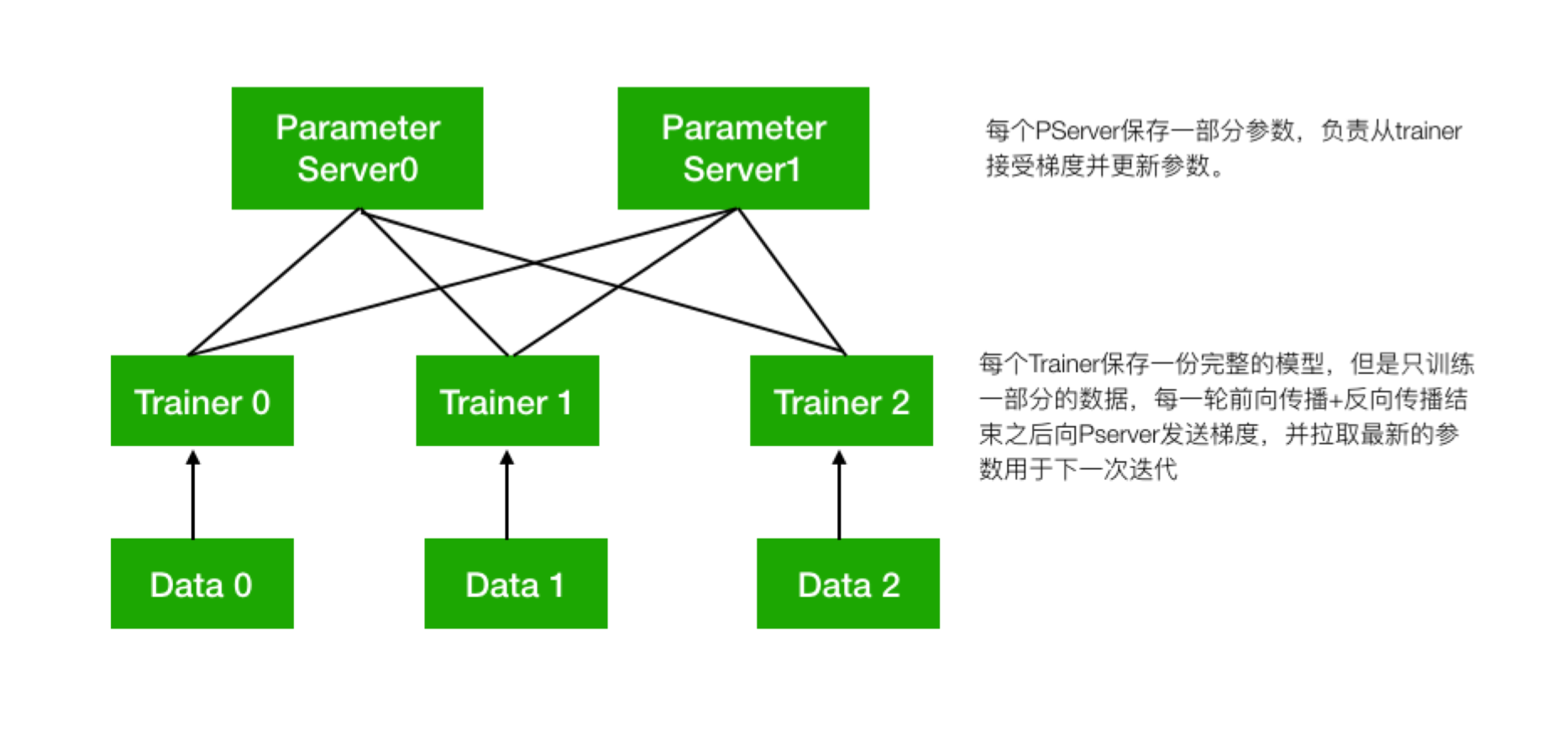
使用RPC通信方式的数据并行分布式训练,会启动多个pserver进程和多个trainer进程,每个pserver进程会保存一部分模型参数,并负责接收从trainer发送的梯度并更新这些模型参数;每个trainer进程会保存一份完整的模型,并使用一部分数据进行训练,然后向pserver发送梯度,最后从pserver拉取更新后的参数。
pserver进程可以在和trainer完全不同的计算节点上,也可以和trainer公用节点。一个分布式任务所需要的pserver进程个数通常需要根据实际情况调整,以达到最佳的性能,然而通常来说pserver的进程不会比trainer更多。
- save_op
在使用GPU训练时,pserver可以选择使用GPU或只使用CPU,如果pserver也使用GPU,则会增加一次从CPU拷贝接收到的梯度数据到GPU的开销,在某些情况下会导致整体训练性能降低。
- 在使用GPU训练时,如果每个trainer节点有多个GPU卡,则会先在每个trainer节点的多个卡之间执行NCCL2通信方式的梯度聚合,然后再通过pserver聚合多个节点的梯度。
分布式训练 API
Paddle 提供了2套API来进行分布式训练,fleet 是更高级的 API,transpile 是底层 API。
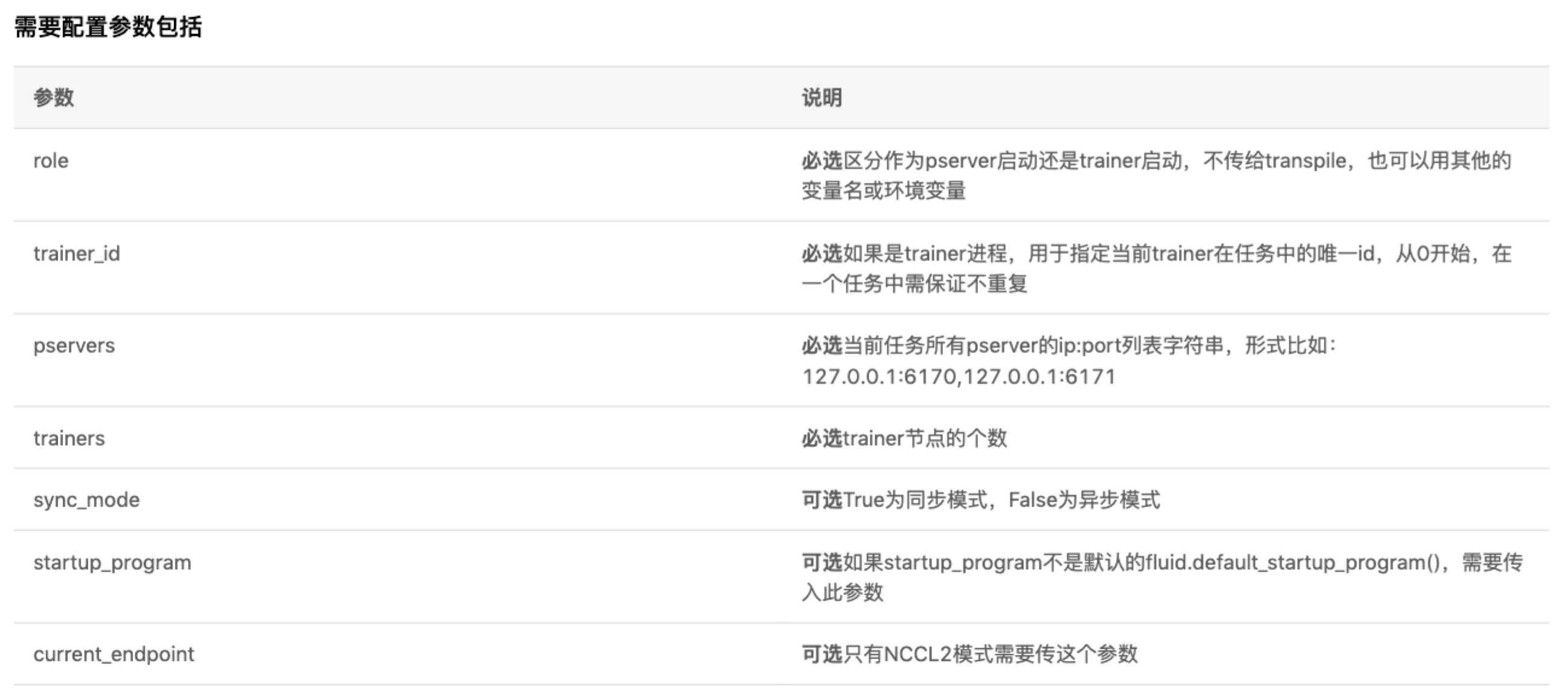
假设总共有 2个节点:192.168.1.1 和 192.168.1.2,使用端口 6170,启动 4 个 Trainer。可以如下定义:使用 transpiler API
官网说明 ```python必填,取值 PSERVER/TRAINER
role = “PSERVER”必填,标识多个TRAINER的ID,从0开始
trainer_id = 0必填,所有的PSERVER地址
pserver_endpoints = “192.168.1.1:6170,192.168.1.2:6170”必填,trainer节点的个数
trainers = 4选填,只有NCCL2模式需要传这个参数
current_endpoint = “192.168.1.1:6170” t = fluid.DistributeTranspiler() t.transpile(trainer_id = 0, pservers=pserver_endpoints, trainers=trainers, sync_mode=False)
if role == “PSERVER”: pserver_prog = t.get_pserver_program(current_endpoint) pserver_startup = t.get_startup_program(current_endpoint, pserver_prog) exe.run(pserver_startup) exe.run(pserver_prog) elif role == “TRAINER”: train_loop(t.get_trainer_program())
<a name="xxDaN"></a>### 使用 fleet API[官网说明](https://www.paddlepaddle.org.cn/documentation/docs/zh/user_guides/howto/training/fleet_api_howto_cn.html)```python# 1. 根据环境变量创建一个 rolerole = role_maker.UserDefinedRoleMaker(current_id=int(os.getenv("CURRENT_TRAIN_ID")),role=role_maker.Role.WORKER if bool(int(os.getenv("IS_WORKER"))) else role_maker.Role.SERVER,worker_num=int(os.getenv("WORKER_NUM")),server_endpoints=pserver_endpoints)# 2. 初始化 rolefleet.init(role)# 3. 将普通的单机 optimizer 改为分布式的 optimizeroptimizer = fleet.distributed_optimizer(optimizer)optimizer.minimize(cost)# 4. 使用 fleet API 启动训练if fleet.is_server():# 4.1 初始化并启动 pserverfleet.init_server()fleet.run_server()elif fleet.is_worker():# 4.2 初始化并启动 trainerfleet.init_worker()exe = fluid.Executor(fluid.CPUPlace())exe.run(fluid.default_startup_program())step = 1001for i in range(step):'''或者fleet._executor.train_from_dataset(program=fleet.main_program,dataset=dataset,fetch_list=[cost.name],fetch_info=fetch_info)'''cost_val = exe.run(program=fluid.default_main_program(),feed=dataset,fetch_list=[cost.name])print("worker_index: %d, step%d cost = %f" %(fleet.worker_index(), i, cost_val[0]))
pserver 和 trainer 对应的环境变量如下:
# pserver1export WORKER_NUM=2export IS_WORKER=FALSEexport PSERVER_ENDPOINTS=192.168.1.1:6170,192.168.1.2:6170# pserver2export WORKER_NUM=2export IS_WORKER=FALSEexport PSERVER_ENDPOINTS=192.168.1.1:6170,192.168.1.2:6170# trainer1export CURRENT_TRAIN_ID=0export WORKER_NUM=2export IS_WORKER=TRUEexport PSERVER_ENDPOINTS=192.168.1.1:6170,192.168.1.2:6170# trainer2export CURRENT_TRAIN_ID=1export WORKER_NUM=2export IS_WORKER=TRUEexport PSERVER_ENDPOINTS=192.168.1.1:6170,192.168.1.2:6170
fleet Python层的封装
虽然 transpiler 和 fleet 都是 paddle 用于分布式训练的API,但 fleet 是更高层的API,其底层的实现仍然是 transpiler。
fleet 的实现在 python/paddle/fluid/incubate/fleet/ 里,由基础的接口类定义方法名,nccl2 和 collective 的实现由继承 base 类的子类实现。
base 接口类的定义在:fleet/base/fleet_base.py,基础的接口类有:Fleet 和 DistributedOptimizer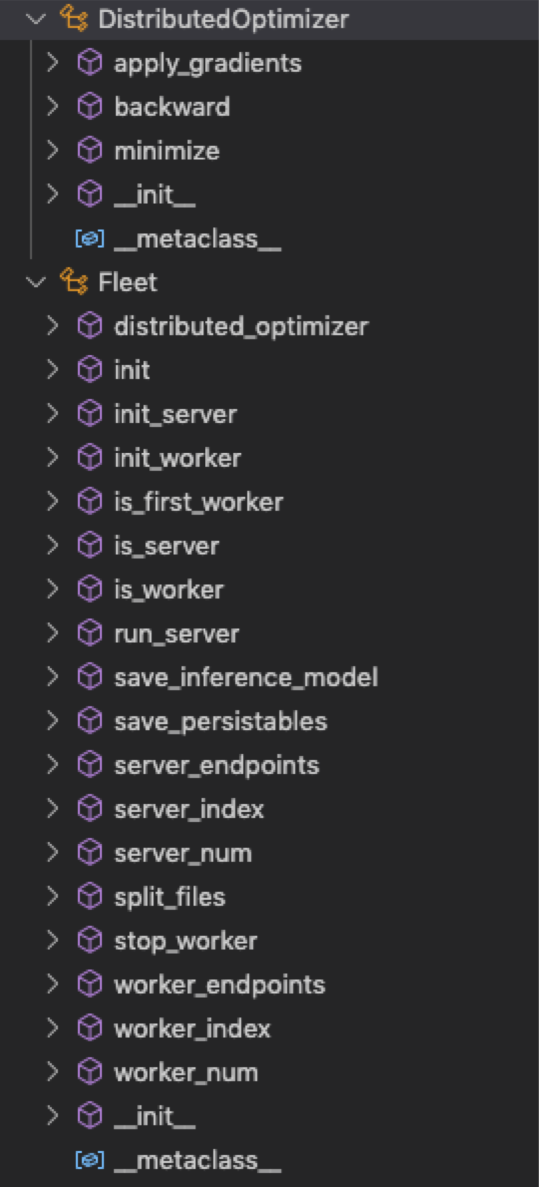
继承了上述 fleet 接口类的有:
fleet/collective/__init__.pyclass Collective(Fleet)class CollectiveOpBasedOptimizer(DistributedOptimizer)
fleet/parameter_server/distribute_transpiler/_init_.pyclass DistributedTranspiler(Fleet)class TranspilerOptimizer(DistributedOptimizer)
fleet/parameter_server/pslib/__init__.pyclass PSLib(Fleet)class DownpourOptimizer(DistributedOptimizer):
先查看用户层使用 fleet API 的调用:
strategy = DistributeTranspilerConfig()strategy.sync_mode = Falseoptimizer = fluid.optimizer.Adagrad(learning_rate=g_learn_rate)# 以下对fleet的调用实际调用的是 DistributedTranspiler.distributed_optimizer(),# 结果返回的是 TranspilerOptimizer 实例optimizer = fleet.distributed_optimizer(optimizer, strategy)# 调用的 TranspilerOptimizer.minimize(),# 而在该函数里,当配置为分布式时,又调用了 fleet._transpile()optimizer.minimize(avg_cost)
通过 fleet 下 pserver 的实现,可以看到 fleet 就是 DistributedTranspiler(Fleet) 类的实例。
而最终fleet._transpile()的实现,只是对底层 transpiler 的封装。# fleet/parameter_server/distribute_transpiler/_init_.pyfleet = DistributedTranspiler()class DistributedTranspiler(Fleet):def distributed_optimizer(self, optimizer, strategy=None):self._optimizer = TranspilerOptimizer(optimizer, strategy)return self._optimizerdef _transpile(self, config):...class TranspilerOptimizer(DistributedOptimizer):def minimize(self,loss,scopes=None,startup_program=None,parameter_list=None,no_grad_set=None):optimize_ops, params_grads = self._optimizer.minimize(loss, startup_program, parameter_list, no_grad_set)# 封装了 transpile 中 DistributedTranspiler 的实现。fleet._transpile(config=self._strategy)return optimize_ops, params_grads
也就是最后都会调用
python/paddle/fluid/transpiler/distribute_transpiler.py里的实现。
具体 fluid 里 transpile 的实现比较复杂,是实现分布式训练的关键,我们留到下一章做重点讲解。分布式 program 的构建
这一节具体分析
fluid.transpile的实现,代码路径:python/paddle/fluid/transpiler/distribute_transpiler.py
transpile 的部分配置信息如下,可以暴露给用户自定义:class DistributeTranspilerConfig(object):# 是否要切分变量到不同的 pserver 上? 默认开启slice_var_up = True# 变量切分方式,支持 hash,RoundRobin(默认)split_method = None# 变量切分的最小参数量,当参数量小于该值时,将不会做切分min_block_size = 8192# supported modes: pserver, nccl2, collectivemode = "pserver"# 是否同步更新变量?True表示对同一个变量,pserver会等待所有的 trainer 上传梯度之后才做更新。_sync_mode = True
transpile 的过程会重构整个 program,使之可以满足在分布式环境中运行,具体有以下几点:
- 将原始的 origin_program 拆开成了 pserver_program 和 trainer_program 两部分。pserver_program 里新增 listen_and_serv OP 和 save OP;trainer_program 里新增 send OP 和 recv OP 用于发送梯度和获取参数。
- 将本地的OP替换成分布式的OP,比如
lookup_table_op换成了distributed_lookup_table_op。 - OP 的合并和优化。
- 将参数量过大的变量切分成多个变量,分配到不同的 pserver 上,为每个需要通信的变量分配指定的 pserver 地址。
变量拆分
当调用transpile()的时候会调用self._init_splited_vars()执行变量拆分。具体的拆分逻辑在slice_variable()里。
- 如果变量的参数量 < min_block_size,则不做拆分;
需要拆分的变量,按照 pserver 的个数平均拆分成 N 个block。当然前提是保证每个block的参数量依然大于 min_block_size,也就是当 pserver 个数很多的时候,参数只会分布在一部分pserver上。
def slice_variable(var_list, slice_count, min_block_size):blocks = []for var in var_list:split_count = slice_countvar_numel = reduce(lambda x, y: x * y, var.shape)max_pserver_count = int(math.floor(var_numel / float(min_block_size)))if max_pserver_count == 0:max_pserver_count = 1if max_pserver_count < slice_count:split_count = max_pserver_countblock_size = int(math.ceil(var_numel / float(split_count)))if len(var.shape) >= 2:# align by dim1(width)dim1 = reduce(lambda x, y: x * y, var.shape[1:])remains = block_size % dim1if remains != 0:block_size += dim1 - remains# update split_count after aligningsplit_count = int(math.ceil(var_numel / float(block_size)))for block_id in range(split_count):curr_block_size = min(block_size, var_numel - ((block_id) * block_size))block = VarBlock(var.name, block_id, curr_block_size)blocks.append(str(block))return blocks
变量分为2种:一种是需要永久性存储的模型参数,一种是临时计算出来的梯度。这2类变量的拆分逻辑都一样。
梯度变量拆分之后会做一个 shuffle 操作,然后给每一个变量分配一个pserver的地址,分配算法有2种:hash 的方式
# 每个参数 hash 的分布在各个 pserver 上,返回一个 pserve 的列表,代表每个参数分布的地址class HashName(PSDispatcher):def _hash_block(self, block_str, total):return hash(block_str) % totaldef dispatch(self, varlist):eplist = []for var in varlist:server_id = self._hash_block(var.name(), len(self._eps))server_for_param = self._eps[server_id]eplist.append(server_for_param)return eplist
轮询的方式
# 每个参数均匀的分布在各个 pserver 上,返回一个 pserve 的列表,代表每个参数分布的地址class RoundRobin(PSDispatcher):def dispatch(self, varlist):eplist = []for var in varlist:server_for_param = self._eps[self._step]eplist.append(server_for_param)self._step += 1if self._step >= len(self._eps):self._step = 0return eplist
program 拆分
原始的 origin_program 拆开成了 pserver_program 和 trainer_program 两部分。同时插入了 send OP,recv OP 等操作,还有 OP 的合并优化等处理,逻辑很复杂,于是直接打印出前后的 program。可以看到具体的修改差异,对比如下:
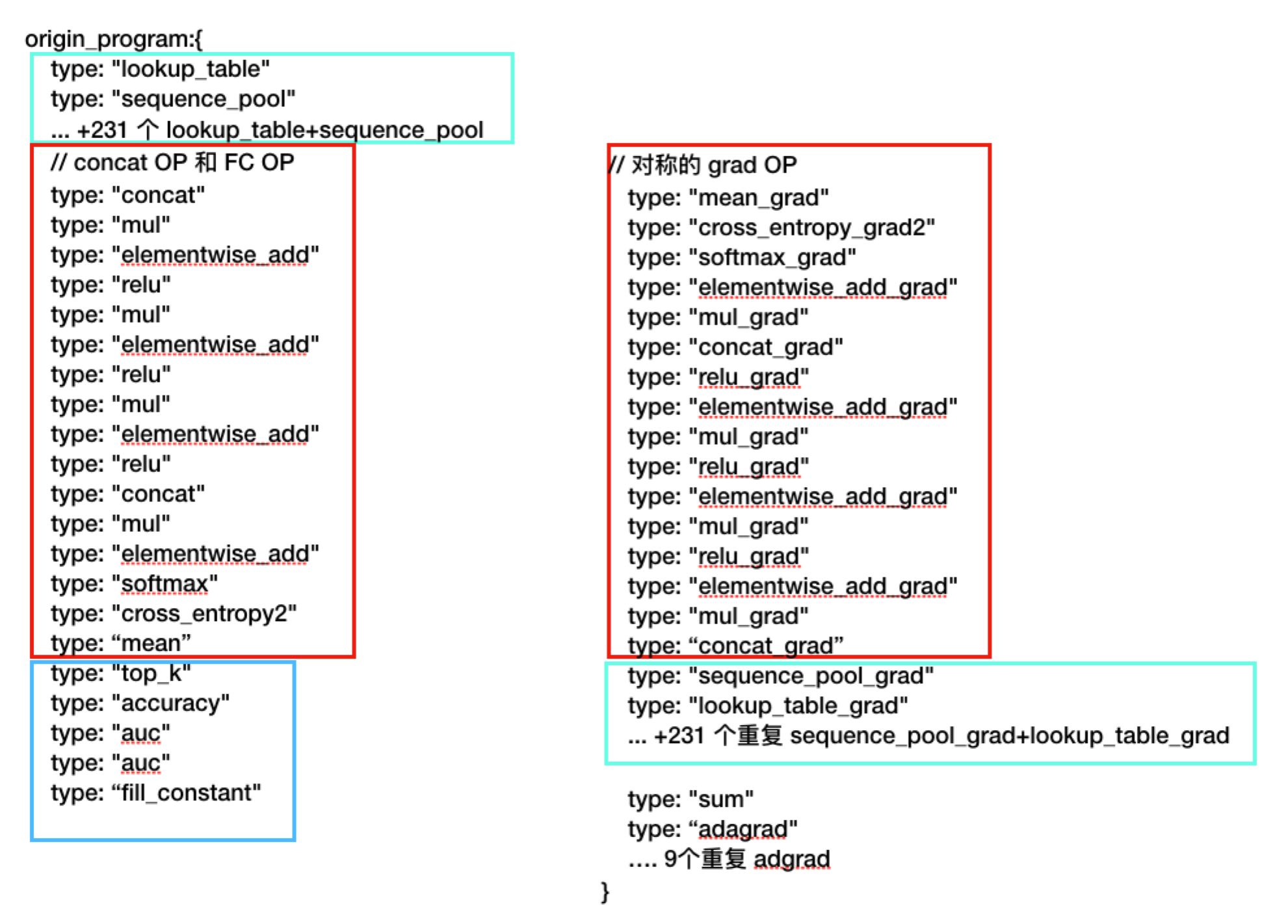
- origin_program
绿色部分是 embedding 相关的OP以及对应的梯度OP;
红色部分是 FC 相关的OP和对应的梯度 OP;
蓝色部分是 不参与反向传播的一些指标性的OP。
- trainer_program
如下图,前向计算的OP主要是lookup_table_op换成了distributed_lookup_table_op,
原来的 program 中有 232 个lookup_table_op + sequence_pool_op,现在变成了2个distributed_lookup_table_op和 232 个sequence_pool_op。也就是将原来 232 个lookup_table_op变成了 2 个distributed_lookup_table_op。
第一个distributed_lookup_table_op是查 embedding 表的,该OP将一次性查所有的 feature_id 对应的 embedding 参数,也就是将 231 个查 embedding 的lookup_table_op合并成了一个,注意这里在合并之前每个 slot 是对应一个lookup_table_op的,合并之后在input里必须要保留 slot 的信息才能做 pooling。
第二个是查 lr 的参数,因为 lr 的实现也是用的 embedding。所以这里的 OP 一样。
distributed_lookup_table_op 最终会从 pserver 上 fetch embedding 的参数,而不是从本地。除此之外,反向传播计算梯度的OP后面加了一个send OP,用于将计算出来的梯度发送到 pserver 上去。当整个反向传播也结束的时候,会有一些 recv 的操作,此时会从 pserver 上获取最新的参数。

- pserver_program
pserver_program 就比较简单了,开头新增了一个 listen_and_serv 的 OP,用于提供 GRPC 服务,处理 trainer 发起的参数更新,参数获取等请求。剩下的就是优化器 adgrad 的 OP,用于根据梯度更新参数,最后是 save OP,用于将参数保存起来。

在创建 embedding layer 的时候提供了2个参数,is_sparse 和 is_distributed,is_sparse 决定了 embedding 表的存储方式是否为稀疏存储,is_sparse=True 将使用 SelectedRows 存储,否则使用 LodTensor 存储。
当 is_sparse=True 且 is_distributed=False 的时候,embedding 参数将保存在 pserver 上,lookup_table_op 在 transpiler 时就会被换成 distributed_lookup_table_op ,每次会从 pserver 上 prefetch embedding 参数,而不是在本地查找 embedding。
# 用户层的调用如下fluid.layers.embedding(input=input,is_sparse=True,is_distributed=False,padding_idx=0,size=[10^9, 32],param_attr=fluid.ParamAttr(name="SparseFeatFactors_deep"))# 实际的API如下def embedding(input...):....helper.append_op(type='lookup_table',inputs={'Ids': input,'W': w},outputs={'Out': tmp},attrs={'is_sparse': is_sparse,'is_distributed': is_distributed,'remote_prefetch': remote_prefetch,'padding_idx': padding_idx,'is_test': is_test})return tmp
可以看到 OP 的 inputs 是 Ids 的名称,也就是用户层定义的 sparse_slot_xxx,另外一个 inputs 是 W ,也叫 SparseFeatFactors_deep,这个 W 就是 embedding 表,Out 就是查表后的结果。
在建立网络结构的时候,这里的 slots 是预先在 yaml 文件里定义好的,所以每个 slot 对应一个 lookup_table_op。而所有的 lookup_table_op 是共用的同一个 embedding 表,其属性名为 SparseFeatFactors_deep。
由于输入的样本文件是 feature:slot,所以同一个 slot 的feature 会被分配到同一个 lookup_table_op 上去运行,最终同一个lookup_table_op 的查找结果可以做一个pooling 的操作。
下面是一个 lookup_table_op 的详情:
inputs {parameter: "Ids"arguments: "sparse_slot_705"}inputs {parameter: "W"arguments: "SparseFeatFactors_deep"}outputs {parameter: "Out"arguments: "embedding_230.tmp_0"}type: "lookup_table"attrs {name: "op_role_var"type: STRINGS}attrs {name: "padding_idx"type: LONGl: 0}attrs {name: "epmap"type: STRINGS}attrs {name: "is_distributed"type: BOOLEANb: false}attrs {name: "op_namescope"type: STRINGs: "/"}attrs {name: "op_callstack"type: STRINGSstrings: "..."}attrs {name: "is_sparse"type: BOOLEANb: true}attrs {name: "op_role"type: INTi: 0}attrs {name: "remote_prefetch"type: BOOLEANb: true}attrs {name: "is_test"type: BOOLEANb: false}attrs {name: "grad_inplace"type: BOOLEANb: false}attrs {name: "table_names"type: STRINGS}attrs {name: "height_sections"type: LONGS}attrs {name: "trainer_id"type: INTi: 0}
通信相关 OP
分布式训练中通信相关的 OP主要有 listen_and_serv_op、distributed_lookup_table_op、send_op、recv_op。涉及参数的获取和更新。
listen_and_serv_op
listen_and_serv_op 是在 pserver_program 中的。主要是启动 gRPC 服务器,监听 trainer 的请求并进行参数更新等操作。
源文件:listen_and_serv_op.cc
类 ListenAndServOp 继承了 framework::OperatorBase,并重写了父类的 RunImpl() 函数,在OP运行的时候,就会调用 RunImpl()。
看看 RunImpl() 的整体流程:
- RegisterRPC(): 注册请求的handler
- 初始化一个 Executor,做program相关的预处理,准备好请求的context
- 绑定每个handler的context,FillRequestCtx()
- 新建一个线程启动服务,StartServer();
- 保存监听的端口到文件中
- 初始化参数更新的 recorder SparseParamUpdateRecorder::Init()
在 listen_and_serv_op.cc 中注册需要监听的 RPC 实现:
constexpr char kRequestSend[] = "RequestSend";constexpr char kRequestGet[] = "RequestGet";constexpr char kRequestPrefetch[] = "RequestPrefetch";rpc_service_->RegisterRPC(distributed::kRequestSend,request_send_handler_.get(),FLAGS_rpc_send_thread_num);rpc_service_->RegisterRPC(distributed::kRequestGet,request_get_handler_.get(),FLAGS_rpc_get_thread_num);rpc_service_->RegisterRPC(distributed::kRequestPrefetch,request_prefetch_handler_.get(),FLAGS_rpc_prefetch_thread_num);
request_handler.cc
用于实现不同的请求的处理的 handler类
父类:class RequestHandler()
子类:
class RequestSendHandler
class RequestGetHandler
class RequestGetNoBarrierHandler
class RequestPrefetchHandler
class RequestCheckpointHandler
class RequestNotifyHandler
然后 StartServer():
grpc_server.cc 里有 RequestBase 和 继承了 RPCServer 的 AsyncGRPCServer 两个类:
- RequestBase 持有 RequestHandler* 对象,代表一个 Request
父类:class RequestBase
子类:
class RequestSend final : public RequestBase
class RequestGet final : public RequestBase
class RequestPrefetch final : public RequestBase - AsyncGRPCServer 是 RPCServer 的子类,
父类:class RPCServer 定义在 rpcserve.cc 中:
定义了RegisterRPC、StartServer、Stop等实现。
RegisterRPC()操作将RPC的名字和handler 保存在 rpc_call_map 中。
AsyncGRPCServer 重载了 StartServer() 的实现,会将 rpccall_map 中的rpc请求再重新注册一遍,而对于的注册对象变成了 RequestBase 的子类,也就是 RequestSend、RequestGet、RequestPrefetch 等。
```cpp for (auto& t : rpccall_map) { auto& rpc_name = t.first; for (int i = 0; i < kRequestBufSize; i++) { VLOG(6) << “TryToRegisterNewOne on RPC NAME: “ << rpc_name << “ I: “ << i; TryToRegisterNewOne(rpc_name, i); } }
void AsyncGRPCServer::TryToRegisterNewOne(const std::string& rpcname, int req_id) { if (rpc_name == kRequestSend) { b = new RequestSend(&service, cq.get(), handler, reqid); } else if (rpc_name == kRequestGet) { b = new RequestGet(&service, cq.get(), handler, reqid); } else if (rpc_name == kRequestPrefetch) { b = new RequestPrefetch(&service, cq.get(), handler, req_id); } }
<a name="yOfUc"></a>
### distributed_lookup_table_op
Trainer 端运行 DistributedLookupTable OP 发起 PrefetchRequest。
```cpp
template <typename T>
class DistributedLookupTableKernel : public framework::OpKernel<T> {
public:
void Compute(const framework::ExecutionContext &context) const override {
// 获取各个属性
....
// 执行 prefetch
operators::distributed::prefetchs(
id_names, out_names, embedding_name, false, lookup_tables, endpoints,
height_sections, context, context.scope());
}
};
Input是所有的Ids, output 是所有的embedding 参数,前提是知道哪些参数分布在哪些 Pserver 上。
先看看其中的2个属性 table_names 和 endpoints。这2个是一一对应的关系,显示了同一个embedding参数被分成多个block之后,存储在哪个pserver 上。height_sections就是每个block的大小。
attrs {
name: "table_names"
type: STRINGS
strings: "SparseFeatFactors_deep.block0"
strings: "SparseFeatFactors_deep.block1"
}
attrs {
name: "height_sections"
type: LONGS
longs: 50000000
longs: 50000000
}
attrs {
name: "endpoints"
type: STRINGS
strings: "127.0.0.1:6170"
strings: "127.0.0.1:6171"
}
parameter_prefetch.cc
void prefetch_core(
const std::vector<int64_t>& ids, const TableAndEndpoints& tables,
const std::vector<int64_t>& height_sections,
const framework::ExecutionContext& context, const framework::Scope& scope,
std::unordered_map<int64_t, std::vector<float>>* recved_vec_map) {
platform::DeviceContextPool& pool = platform::DeviceContextPool::Instance();
auto& actual_ctx = *pool.Get(context.GetPlace());
// 创建一个临时的 local_scope 来保存 input_var 和 output_var 的数据。
std::unique_ptr<framework::Scope> local_scope = scope.NewTmpScope();
// 给每个table 新建两个变量
// in_var_names=[prefetch_send@127.0.0.1:6170, prefetch_send@127.0.0.1:6171]
// out_var_names=[prefetch_recv@127.0.0.1:6170, prefetch_recv@127.0.0.1:6171]
std::vector<std::string> in_var_names;
std::vector<std::string> out_var_names;
for (size_t i = 0; i < tables.size(); ++i) {
in_var_names.push_back("prefetch_send@" + tables[i].second);
out_var_names.push_back("prefetch_recv@" + tables[i].second);
}
// 如果 ids 数组太大,就分割,并将 ids 的值存在 local_scope 中
auto splited_ids = SplitIds(ids, height_sections);
SplitIdsIntoMultipleVarsBySection(in_var_names, height_sections, splited_ids,
local_scope.get());
// 在 local_scope 中创建 LoDTensor 类型的 output_var
for (auto& name : out_var_names) {
local_scope->Var(name)->GetMutable<framework::LoDTensor>();
}
distributed::RPCClient* rpc_client =
distributed::RPCClient::GetInstance<RPCCLIENT_T>(
context.Attr<int>("trainer_id"));
// 异步发送请求
std::vector<distributed::VarHandlePtr> rets;
for (size_t i = 0; i < in_var_names.size(); i++) {
if (NeedSend(*local_scope.get(), in_var_names[i])) {
VLOG(3) << "sending " << in_var_names[i] << " to " << tables[i].second
<< " to get " << out_var_names[i] << " back";
// AsyncPrefetchVar 入参:
// endpoint,连接上下文,local_scope,输入的变量名,输出的变量名,表名
rets.push_back(rpc_client->AsyncPrefetchVar(
tables[i].second, actual_ctx, *local_scope.get(), in_var_names[i],
out_var_names[i], tables[i].first));
} else {
VLOG(3) << "don't send no-initialied variable: " << out_var_names[i];
}
}
// 等待回包
for (size_t i = 0; i < rets.size(); i++) {
PADDLE_ENFORCE(rets[i]->Wait(), "internal error in RPCClient");
}
// 处理收到的数据
for (size_t section_idx = 0; section_idx < out_var_names.size();
++section_idx) {
.....
}
}
由于输入是一个 int64 数组,现在需要切分成多个section,大小和 endpoints 相同,从而去相应的 pserver 上去查。采用 id%pservers 取余的方式去切分的。
首先这里的 ids 已经是取余之后的 ids,也就是在 ctr_reader.py 里的输出的已经是对 dict_size 取余之后的。
切分是根据 embedding 的 shape 做的切分。也就是根据[dict_size, embedding_size] 切分。
- SplitIds()
先将 ids 去重,然后根据 height_sections,用取余的方式切分成多组 SplitIds。 - SplitIdsIntoMultipleVarsBySection()
将 SplitIds 变成 Var 类型放进 in_var_names 里。
也就是变量
所以 transpile 的时候用 RoundRobin/Hash 将 embedding 切分在多个 pserver 上,而在 lookup_table 的时候通过 id%pserver 的方式去查询,这样保证同一个参数是分布在同一个的vars { "name": prefetch_send@127.0.0.1:6170 "value": SplitIds[0] } vars { "name": prefetch_send@127.0.0.1:6171 "value": SplitIds[1] }
AsyncPrefetchVar() 细节:
trainer Request 过程的 log 如下:VarHandlePtr GRPCClient::AsyncPrefetchVar(const std::string& ep...) { const platform::DeviceContext* p_ctx = &ctx; const std::string ep_val = ep; const std::string in_var_name_val = in_var_name; const std::string out_var_name_val = out_var_name; const std::string table_name_val = table_name; const framework::Scope* p_scope = &scope; // 根据 ep 地址获取一个 channel const auto ch = GetChannel(ep_val); const std::string method = kPrefetchRPC; int retry_times_ = 0; // 具体的通信发包 while (true) { GetProcessor* s = new GetProcessor(ch); VarHandlePtr h(new VarHandle(ep, method, out_var_name_val, p_ctx, p_scope)); s->Prepare(h, time_out); framework::AsyncIO([in_var_name_val, out_var_name_val, ep_val, p_scope, p_ctx, s, method, h, table_name_val, this] { auto* var = p_scope->FindVar(in_var_name_val); ::grpc::ByteBuffer req; SerializeToByteBuffer(in_var_name_val, var, *p_ctx, &req, out_var_name_val, 0, table_name_val); VLOG(3) << s->GetVarHandlePtr()->String() << " begin"; // stub context s->response_call_back_ = ProcGetResponse; platform::RecordRPCEvent record_event(method); auto call = s->stub_g_.PrepareUnaryCall( s->context_.get(), "/sendrecv.SendRecvService/PrefetchVariable", req, &cq_); call->StartCall(); call->Finish(&s->reply_, &s->status_, static_cast<void*>(s)); if (UNLIKELY(platform::IsProfileEnabled())) { h->Wait(); } }); req_count_++; // 重试逻辑 return h; } }
接着是 pserver 的 response 过程:I0108 09:09:58.494256 9344 hogwild_worker.cc:135] Going to run op distributed_lookup_table I0108 09:09:58.497203 9344 operator.cc:165] CPUPlace Op(distributed_lookup_table), inputs:{Ids[sparse_slot_1:int64_t[32, 1]({{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32}}), sparse_slot_2:...} I0108 09:09:58.497671 9344 operator.cc:988] expected_kernel_key:data_type[float]:data_layout[ANY_LAYOUT]:place[CPUPlace]:library_type[PLAIN] I0108 09:09:58.503204 9344 scope.cc:164] Create variable prefetch_send@127.0.0.1:6170 I0108 09:09:58.503458 9344 scope.cc:164] Create variable prefetch_recv@127.0.0.1:6170 I0108 09:09:58.503598 9344 parameter_prefetch.cc:119] sending prefetch_send@127.0.0.1:6170 to 127.0.0.1:6170 to get prefetch_recv@127.0.0.1:6170 back I0108 09:09:58.503856 9148 grpc_client.cc:273] PrefetchRPC name:[prefetch_recv@127.0.0.1:6170], ep:[127.0.0.1:6170], status:[-1] begin I0108 09:09:58.568178 9139 grpc_client.cc:457] PrefetchRPC name:[prefetch_recv@127.0.0.1:6170], ep:[127.0.0.1:6170], status:[-1] process I0108 09:09:58.568346 9139 grpc_client.cc:127] ProcGetResponse I0108 09:09:58.579715 9344 operator.cc:185] CPUPlace Op(distributed_lookup_table), inputs:{Ids[sparse_slot_1:int64_t[32, 1]({{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32}}), sparse_slot_2:...} I0108 09:09:58.580394 9344 hogwild_worker.cc:139] Op distributed_lookup_table Finished
由 RequestPrefetchHandler() 处理上述请求,最终是新建一个 LookupSparseTableOp 去做查找的。由于 embedding Table 使用 SelectedRow 实现,最后的查找在 selected_rows.cc 里实现。
LookupSparseTableOp::RunImpl() 实现细节:
日志:class LookupSparseTableOp : public framework::OperatorBase { public: using framework::OperatorBase::OperatorBase; private: void RunImpl(const framework::Scope &scope, const platform::Place &dev_place) const override { auto out_var = scope.FindVar(Output("Out")); auto w_var = scope.FindVar(Input("W")); auto ids_var = scope.FindVar(Input("Ids")); auto is_test = Attr<bool>("is_test"); auto &ids_t = ids_var->Get<framework::LoDTensor>(); auto out_t = out_var->GetMutable<framework::LoDTensor>(); // w_t 是 framework::SelectedRows 实例 auto w_t = w_var->GetMutable<framework::SelectedRows>(); platform::CPUPlace cpu; auto out_shape = w_t->value().dims(); out_shape[0] = ids_t.numel(); out_t->Resize(out_shape); out_t->mutable_data(cpu, w_t->value().type()); // w_t->Get() 即调用 SelectedRows::Get(),具体的查找过程在 SelectedRows 里实现的 w_t->Get(ids_t, out_t, true, is_test, true, true); out_t->set_lod(ids_t.lod()); } };I0108 09:09:58.505403 9012 scope.cc:164] Create variable prefetch_send@127.0.0.1:6170 I0108 09:09:58.505606 9012 grpc_server.cc:556] HandleRequest RequestPrefetch, req_id:0 get next I0108 09:09:58.505641 9012 grpc_server.cc:567] RequestPrefetch name:[prefetch_send@127.0.0.1:6170], ep:[ipv4:127.0.0.1:10724] Process using req_id:0 I0108 09:09:58.505651 9012 grpc_server.cc:337] RequestPrefetch, in_var_name: prefetch_send@127.0.0.1:6170 out_var_name: prefetch_recv@127.0.0.1:6170 I0108 09:09:58.505666 9012 scope.cc:164] Create variable prefetch_recv@127.0.0.1:6170 I0108 09:09:58.505677 9012 request_handler_impl.cc:211] RequestPrefetchHandler prefetch_send@127.0.0.1:6170 I0108 09:09:58.505686 9012 request_handler_impl.cc:222] RequestPrefetchHandler: table name is SparseFeatFactors_deep I0108 09:09:58.505705 9012 op_registry.cc:49] CreateOp directly from OpDesc is deprecated. It should only beused in unit tests. Use CreateOp(const OpDesc& op_desc) instead. I0108 09:09:58.505780 9012 operator.cc:165] CPUPlace Op(lookup_sparse_table), inputs:{Ids[prefetch_send@127.0.0.1:6170:int64_t[4025, 1]({})], W[SparseFeatFactors_deep[row_size=0]:float[100000000, 8]({{}})]}, outputs:{Out[prefetch_recv@127.0.0.1:6170:[0]({{}})]}. I0108 09:09:58.567589 9012 operator.cc:185] CPUPlace Op(lookup_sparse_table), inputs:{Ids[prefetch_send@127.0.0.1:6170:int64_t[4025, 1]({})], W[SparseFeatFactors_deep[row_size=0]:float[100000000, 8]({{}})]}, outputs:{Out[prefetch_recv@127.0.0.1:6170:float[4025, 8]({})]}. I0108 09:09:58.567870 9012 grpc_server.cc:549] HandleRequest RequestPrefetch wait next I0108 09:09:58.567914 9017 grpc_server.cc:556] HandleRequest RequestPrefetch, req_id:0 get next I0108 09:09:58.567983 9017 grpc_server.cc:567] RequestPrefetch name:[prefetch_send@127.0.0.1:6170], ep:[ipv4:127.0.0.1:10724] Finish using req_id:0send_op
send op 是发送梯度信息到
send op log:I0108 09:09:58.968538 9344 hogwild_worker.cc:135] Going to run op send I0108 09:09:58.968704 9344 operator.cc:165] CPUPlace Op(send), inputs:{X[fc_3.b_0@GRAD:float[2]({})]}, outputs:{Out[__control_var@0.436815957363:[0]({{}})]}. I0108 09:09:58.968796 9344 communicator.cc:253] communicator send fc_3.b_0@GRAD I0108 09:09:58.968989 9344 tensor_util.cc:28] TensorCopy 2 from CPUPlace to CPUPlace I0108 09:09:58.969172 9344 communicator.cc:268] send fc_3.b_0@GRAD queue size 0 I0108 09:09:58.969363 9344 operator.cc:185] CPUPlace Op(send), inputs:{X[fc_3.b_0@GRAD:float[2]({})]}, outputs:{Out[__control_var@0.436815957363:[0]({{}})]}. I0108 09:09:58.969411 9344 hogwild_worker.cc:139] Op send Finishedrecv_op
参数保存
save_op

若有收获,就点个赞吧
0 人点赞
