- 简单的训练代码
- 主线执行逻辑分析
- 执行器 Trainer 和 DeviceWorker
- 数据流 Dataset/Datafeed
-
简单的训练代码
以一个的简单的分布式训练脚本为例子:
def ctr_wide_deep_model():def embedding_layer(input, param_attr, embedding_size):return fluid.layers.embedding(input=input,is_sparse=True,is_distributed=False,padding_idx=0,size=[g_dict_size, embedding_size],param_attr=param_attr)sparse_slots, _, one_hot_slots_to_tims, dense_slots_to_dims = parser.parse_yaml(g_yaml_path)label = fluid.layers.data(name='label', shape=[1], dtype='int64')deep_param_attr = fluid.ParamAttr(name="SparseFeatFactors_deep")sparse_deep_input_list = []sparse_wide_input_list = []sparse_input_ids = []for slot in sparse_slots:sparse_input_id = fluid.layers.data(name='sparse_slot_' + str(slot), shape=[1], lod_level=1, dtype='int64')sparse_input_ids.append(sparse_input_id)sparse_embed = embedding_layer(sparse_input_id, deep_param_attr, g_embedding_size)sparse_embed_deep_average = fluid.layers.sequence_pool(input=sparse_embed, pool_type="average")sparse_deep_input_list.append(sparse_embed_deep_average)wide_param_attr = fluid.ParamAttr(name="SparseFeatFactors_wide")sparse_lr_input_ids = fluid.layers.data(name='sparse_lr_index', shape=[1], lod_level=1, dtype='int64')sparse_lr_embed = embedding_layer(sparse_lr_input_ids, wide_param_attr, 1)sparse_wide_inputs = fluid.layers.sequence_pool(input=sparse_lr_embed, pool_type="sum")sparse_deep_inputs = fluid.layers.concat(sparse_deep_input_list, axis=1)datas = []for data in sparse_input_ids:datas.append(data)datas.append(sparse_lr_input_ids)datas.append(label)def deep_layer(concated):fc = fluid.layers.fc(input=concated, size=1024, act='relu')fc = fluid.layers.fc(input=fc, size=512, act='relu')fc = fluid.layers.fc(input=fc, size=256, act='relu')return fc# one_hot_inputs, dense_inputsdeep = deep_layer(sparse_deep_inputs)wide = fluid.layers.concat([deep, sparse_wide_inputs], axis=1)predict = fluid.layers.fc(input=wide, size=2, act='softmax')cost = fluid.layers.cross_entropy(input=predict, label=label)avg_cost = fluid.layers.mean(x=cost)accuracy = fluid.layers.accuracy(input=predict, label=label)auc_var, batch_auc_var, auc_states = fluid.layers.auc(input=predict, label=label)feed_online_var_names = []feed_online_var_names.append(sparse_deep_inputs.name)feed_online_var_names.append(sparse_wide_inputs.name)return feed_online_var_names, datas, avg_cost, auc_var, batch_auc_var, label, predictdef train():main_prog = fluid.default_main_program()start_prog = fluid.default_startup_program()main_prog.random_seed = 1start_prog.random_seed = 1feed_offline_var_names = []feed_online_var_names, datas, avg_cost, auc_var, batch_auc_var, label, predict = ctr_wide_deep_model()for data in datas:feed_offline_var_names.append(data.name)endpoints = g_pserver_endpoints.split(",")if g_training_role.upper() == "PSERVER":current_id = endpoints.index(g_current_endpoint)else:current_id = 0role = role_maker.UserDefinedRoleMaker(current_id=current_id,role=role_maker.Role.WORKERif g_training_role.upper() == "TRAINER" else role_maker.Role.SERVER,worker_num=g_trainers,server_endpoints=endpoints)exe = fluid.Executor(fluid.CPUPlace())fleet.init(role)trainer_id = g_trainer_idstrategy = DistributeTranspilerConfig()strategy.sync_mode = Falseoptimizer = fluid.optimizer.Adagrad(learning_rate=g_learn_rate)optimizer = fleet.distributed_optimizer(optimizer, strategy)optimizer.minimize(avg_cost)if fleet.is_server():info("run pserver")if g_latest_model_path != "" and len(os.listdir(g_latest_model_path)) != 0:fleet.init_server(g_latest_model_path)info("ps: {} load latest model for increment training successful!".format(current_id))else:fleet.init_server()fleet.run_server()elif fleet.is_worker():info("run trainer")fleet.init_worker()exe.run(fleet.startup_program)file_lists, date_lists = get_file_list(g_data_path)info("file_lists: {}".format(file_lists))# config datasetdataset = fluid.DatasetFactory().create_dataset()dataset.set_batch_size(g_batch_size)dataset.set_use_var(datas)pipe_command = 'python ' + g_read_pythondataset.set_pipe_command(pipe_command)dataset.set_thread(g_rd_thd_num)g_epoch_num = len(file_lists)if g_model_save_interval <= 0:g_model_save_interval = calculate_save_model_interval(g_epoch_num)info("g_model_save_interval: {}".format(g_model_save_interval))#upload = AsyncUploadModelProcess()for epoch_id in range(g_epoch_num):info("epoch {} start with file list: {}".format(epoch_id, file_lists[epoch_id]))pass_start = time.time()dataset.set_filelist(file_lists[epoch_id])fleet._executor.train_from_dataset(program=fleet.main_program,dataset=dataset,fetch_list=[avg_cost, auc_var, batch_auc_var],fetch_info=["cost", "auc", "batch_auc"],print_period=g_print_period,debug=True)pass_time = time.time() - pass_startinfo("trainer id: {} epoch {} finished, pass_time {}".format(g_trainer_id, epoch_id, pass_time))if g_trainer_id == 0:last_time = (epoch_id + 1 == g_epoch_num)# 每隔 g_model_save_interval 保存并上传模型if (epoch_id + 1) % g_model_save_interval == 0 or last_time:offline_model_dir = generate_save_model_dir(last_time, date_lists[epoch_id])fleet.save_inference_model(executor=exe, dirname=offline_model_dir, feeded_var_names=feed_offline_var_names, target_vars=[predict, auc_var, batch_auc_var])with open(offline_model_dir + "/feed_online_names", 'w+') as f:feed_str = "deep_input_name:" + feed_online_var_names[0] + "\n" + "wide_input_name:" + feed_online_var_names[1]f.write(feed_str)exe.close()info("training task is finished!")#upload.terminate_upload_process()do_exit(0)do_exit(0)if __name__ == '__main__':train()
主线执行逻辑分析
首先从上层python的调用开始
executor.py: train_from_dataset()# paddlepaddle/python/paddle/fluid/executor.pydef train_from_dataset(self,program=None,dataset=None,scope=None,thread=0,debug=False,fetch_list=None,fetch_info=None,print_period=100):# 设置读数据的 pipeline 线程if program._pipeline_opt:thread = self._adjust_pipeline_resource(program._pipeline_opt,dataset, thread)scope, trainer = self._prepare_trainer(program=program,dataset=dataset,scope=scope,thread=thread,debug=debug,fetch_list=fetch_list,fetch_info=fetch_info,print_period=print_period)trainer._gen_trainer_desc()self._dump_debug_info(program=program, trainer=trainer)# 这里调用 run_from_dataset,fetch_list/fetch_info 等信息被包装在trainer 里面了self._default_executor.run_from_dataset(program.desc, scope,dataset.dataset,trainer._desc())return None
train_from_dataset最后会调用run_from_dataset做真正的训练,在此之前,需要通过_prepare_trainer生成一个trainer对象,训练相关的信息,包括program, dataset, fetch_list, fetch_info, print_period等都保存在 trainer 对象中。def _prepare_trainer(self,program=None,dataset=None,scope=None,thread=0,debug=False,fetch_list=None,fetch_info=None,print_period=100):....trainer = TrainerFactory()._create_trainer(program._pipeline_opt)....
trainer 对象通过调用 TrainerFactory 生成,在
trainer_factory.py中可以看到默认使用的 trainer为 MultiTrainer。class TrainerFactory(object):def _create_trainer(self, opt_info=None):if opt_info == None:# default is MultiTrainer + Hogwildtrainer = MultiTrainer()device_worker = Hogwild()trainer._set_device_worker(device_worker)else:....return trainer
每一个 Trainer 会绑定一个 DeviceWorker,DeviceWorker 屏蔽了OP在不同硬件上的实现,实际的计算过程也是在 DeviceWorker 中进行的。上述默认的 DeviceWorker 是HogwildDeviceWorker。
接下来跟踪到 MultiTrainer 的实现,在multi_trainer.cc中,MultiTrainer初始化的时候会创建一个线程池threads_,每个线程会根据trainer_desc.device_worker_name() 创建一个DeviceWorker实例,MultiTrainer::Run() 实际上调用的是 DeviceWorker::TrainFiles()。void MultiTrainer::Run() {for (int thidx = 0; thidx < thread_num_; ++thidx) {...// 创建线程池,每个线程运行 DeviceWorker::TrainFilesthreads_.push_back(std::thread(&DeviceWorker::TrainFiles, workers_[thidx].get()));...}}
接下来查看
hogwild_worker.cc中HogwildWorker::TraineFiles()的具体实现,逻辑很简单,就是每次从 device_reader 中获取一个 batch 的数据,然后遍历所有的 OP,在该数据集上调用每个OP的Run实现,同时每个 batch 打印一次需要输出的值。void HogwildWorker::TrainFiles() {device_reader_->Start();int cur_batch;while ((cur_batch = device_reader_->Next()) > 0) {for (auto &op : ops_) {...op->Run(*thread_scope_, place_);...}PrintFetchVars();}}
以上就是主线执行逻辑,总结一下:
- 用户层最终会调用 train_from_dataset()
- train_from_dataset() 根据 program、dataset、fetch_list、fetch_info 等信息,生成一个 trainer 对象,其中 program 是根据用户调用上层 python API 构建的计算图,dataset 是训练数据,fetch_list 是训练最终的 output 节点,这些节点决定了 program 中的哪些OP需要被保留。
- trainer 层面会启用多线程去做训练,每个线程分配了一个 DeviceWorker 和一个 data_reader
- 每个线程中 DeviceWorker 遍历 data_reader 获取一个batch 的数据,然后运行所有的 OP,这样一个 batch 的训练就完成了。所有的线程运行一次的时候,trainer 的一个 epoch 就执行完毕了。
接下来的疑问点还有:
- dataset 是如何从用户层的API定义,将数据切分喂到 trainer 里的。
- 从 program 到具体的 OP 是如何转换的。
分布式训练过程中,参数是如何在 Pserver 和 Worker 之间传递和保存的。
执行器 Trainer 和 DeviceWorker
Trainer 的领域模型:
父类:TrainerDesc
子类:MultiTrainer、DistMultiTrainer、PipelineTrainer
工厂类:TrainerFactoryclass TrainerDesc(object):#......def _set_fetch_var_and_info(self, fetch_vars, fetch_info, print_period):for i, v in enumerate(fetch_vars):self.proto_desc.fetch_config.fetch_var_names.extend([v.name])self.proto_desc.fetch_config.fetch_var_str_format.extend([fetch_info[i]])self.proto_desc.fetch_config.print_period = print_perioddef _set_program(self, program):self._program = program#....
可以看到
fetch_target_list保存在proto_desc.fetch_config.fetch_var_names里,fetch_info保存在proto_desc.fetch_config.fetch_var_str_format里。
MultiTrainer 的初始化:
这里的初始化包括 DeviceWorker、DataFeed、Program 的准备。dataset 里设置的线程数决定了 trainer 的线程数,也决定了这里 DeviceWorker 的实例个数void MultiTrainer::Initialize(const TrainerDesc& trainer_desc,Dataset* dataset) {....// get filelist from trainer_desc hereconst std::vector<paddle::framework::DataFeed*> readers =dataset->GetReaders();VLOG(3) << "readers num: " << readers.size();// change thread num to readers numthread_num_ = readers.size();VLOG(3) << "worker thread num: " << thread_num_;workers_.resize(thread_num_);for (int i = 0; i < thread_num_; ++i) {// 创建 DeviceWorkerworkers_[i] = DeviceWorkerFactory::CreateDeviceWorker(trainer_desc.device_worker_name());workers_[i]->Initialize(trainer_desc);workers_[i]->SetDeviceIndex(i);workers_[i]->SetDataFeed(readers[i]);}...}// call only after all resources are set in current trainervoid MultiTrainer::InitTrainerEnv(const ProgramDesc& main_program,const platform::Place& place) {for (int i = 0; i < thread_num_; ++i) {workers_[i]->SetPlace(place);workers_[i]->SetReaderPlace(place);workers_[i]->SetRootScope(root_scope_);// DeviceWorker 相关资源的初始化workers_[i]->CreateDeviceResource(main_program); // Programworkers_[i]->BindingDataFeedMemory();}}
DeviceWorker 领域模型:
父类:DeviceWorker
子类:Hogwild, DownpourSGD, Section
工厂类:DeviceWorkerFactory
上文的MultiTrainer::InitTrainerEnv()中调用了DeviceWorker::CreateDeviceResource()初始化相关的资源,而CreateThreadOperators()负责将 program 中需要运行的 op 拆解出来去运行void HogwildWorker::CreateDeviceResource(const ProgramDesc &main_prog) {CreateThreadScope(main_prog);CreateThreadOperators(main_prog);}void HogwildWorker::CreateThreadOperators(const ProgramDesc &program) {auto &block = program.Block(0);op_names_.clear();for (auto &op_desc : block.AllOps()) {std::unique_ptr<OperatorBase> local_op = OpRegistry::CreateOp(*op_desc);op_names_.push_back(op_desc->Type());OperatorBase *local_op_ptr = local_op.release();ops_.push_back(local_op_ptr);continue;}}
具体一次训练有哪些OP呢?可以在
HogwildWorker::TrainFiles()中打印出所有的 OP:I1226 07:23:55.362789 52708 hogwild_worker.cc:170] len(ops)=754I1226 07:23:55.362907 52708 hogwild_worker.cc:172] op[0]->Type(): distributed_lookup_tableI1226 07:23:55.362978 52708 hogwild_worker.cc:172] op[1]->Type(): distributed_lookup_tableI1226 07:23:55.363054 52708 hogwild_worker.cc:172] op[2]->Type(): sequence_pool...I1226 07:23:55.371731 52708 hogwild_worker.cc:172] op[233]->Type(): sequence_poolI1226 07:23:55.371770 52708 hogwild_worker.cc:172] op[234]->Type(): concatI1226 07:23:55.371798 52708 hogwild_worker.cc:172] op[235]->Type(): mulI1226 07:23:55.371837 52708 hogwild_worker.cc:172] op[236]->Type(): elementwise_addI1226 07:23:55.371866 52708 hogwild_worker.cc:172] op[237]->Type(): reluI1226 07:23:55.371903 52708 hogwild_worker.cc:172] op[238]->Type(): mulI1226 07:23:55.371932 52708 hogwild_worker.cc:172] op[239]->Type(): elementwise_addI1226 07:23:55.371973 52708 hogwild_worker.cc:172] op[240]->Type(): reluI1226 07:23:55.372014 52708 hogwild_worker.cc:172] op[241]->Type(): mulI1226 07:23:55.372056 52708 hogwild_worker.cc:172] op[242]->Type(): elementwise_addI1226 07:23:55.372084 52708 hogwild_worker.cc:172] op[243]->Type(): reluI1226 07:23:55.372123 52708 hogwild_worker.cc:172] op[244]->Type(): concatI1226 07:23:55.372151 52708 hogwild_worker.cc:172] op[245]->Type(): mulI1226 07:23:55.372193 52708 hogwild_worker.cc:172] op[246]->Type(): elementwise_addI1226 07:23:55.372221 52708 hogwild_worker.cc:172] op[247]->Type(): softmaxI1226 07:23:55.372261 52708 hogwild_worker.cc:172] op[248]->Type(): cross_entropy2I1226 07:23:55.372289 52708 hogwild_worker.cc:172] op[249]->Type(): meanI1226 07:23:55.372326 52708 hogwild_worker.cc:172] op[250]->Type(): top_kI1226 07:23:55.372355 52708 hogwild_worker.cc:172] op[251]->Type(): accuracyI1226 07:23:55.372393 52708 hogwild_worker.cc:172] op[252]->Type(): aucI1226 07:23:55.372422 52708 hogwild_worker.cc:172] op[253]->Type(): aucI1226 07:23:55.372460 52708 hogwild_worker.cc:172] op[254]->Type(): fill_constantI1226 07:23:55.372489 52708 hogwild_worker.cc:172] op[255]->Type(): mean_gradI1226 07:23:55.372527 52708 hogwild_worker.cc:172] op[256]->Type(): cross_entropy_grad2I1226 07:23:55.372556 52708 hogwild_worker.cc:172] op[257]->Type(): softmax_gradI1226 07:23:55.372594 52708 hogwild_worker.cc:172] op[258]->Type(): elementwise_add_gradI1226 07:23:55.372623 52708 hogwild_worker.cc:172] op[259]->Type(): sendI1226 07:23:55.372661 52708 hogwild_worker.cc:172] op[260]->Type(): mul_gradI1226 07:23:55.372690 52708 hogwild_worker.cc:172] op[261]->Type(): sendI1226 07:23:55.372728 52708 hogwild_worker.cc:172] op[262]->Type(): concat_gradI1226 07:23:55.372757 52708 hogwild_worker.cc:172] op[263]->Type(): relu_gradI1226 07:23:55.372797 52708 hogwild_worker.cc:172] op[264]->Type(): elementwise_add_gradI1226 07:23:55.372826 52708 hogwild_worker.cc:172] op[265]->Type(): sendI1226 07:23:55.372864 52708 hogwild_worker.cc:172] op[266]->Type(): mul_gradI1226 07:23:55.372893 52708 hogwild_worker.cc:172] op[267]->Type(): sendI1226 07:23:55.372931 52708 hogwild_worker.cc:172] op[268]->Type(): relu_gradI1226 07:23:55.372961 52708 hogwild_worker.cc:172] op[269]->Type(): elementwise_add_gradI1226 07:23:55.372999 52708 hogwild_worker.cc:172] op[270]->Type(): sendI1226 07:23:55.373036 52708 hogwild_worker.cc:172] op[271]->Type(): mul_gradI1226 07:23:55.373073 52708 hogwild_worker.cc:172] op[272]->Type(): sendI1226 07:23:55.373102 52708 hogwild_worker.cc:172] op[273]->Type(): relu_gradI1226 07:23:55.373140 52708 hogwild_worker.cc:172] op[274]->Type(): elementwise_add_gradI1226 07:23:55.373169 52708 hogwild_worker.cc:172] op[275]->Type(): sendI1226 07:23:55.373208 52708 hogwild_worker.cc:172] op[276]->Type(): mul_gradI1226 07:23:55.373236 52708 hogwild_worker.cc:172] op[277]->Type(): sendI1226 07:23:55.373275 52708 hogwild_worker.cc:172] op[278]->Type(): concat_gradI1226 07:23:55.373303 52708 hogwild_worker.cc:172] op[279]->Type(): sequence_pool_gradI1226 07:23:55.373342 52708 hogwild_worker.cc:172] op[280]->Type(): lookup_table_gradI1226 07:23:55.373370 52708 hogwild_worker.cc:172] op[281]->Type(): sendI1226 07:23:55.373407 52708 hogwild_worker.cc:172] op[282]->Type(): sequence_pool_gradI1226 07:23:55.373436 52708 hogwild_worker.cc:172] op[283]->Type(): lookup_table_grad....I1226 07:23:55.385617 52708 hogwild_worker.cc:172] op[742]->Type(): sequence_pool_gradI1226 07:23:55.385648 52708 hogwild_worker.cc:172] op[743]->Type(): lookup_table_gradI1226 07:23:55.385668 52708 hogwild_worker.cc:172] op[744]->Type(): sumI1226 07:23:55.385692 52708 hogwild_worker.cc:172] op[745]->Type(): sendI1226 07:23:55.385723 52708 hogwild_worker.cc:172] op[746]->Type(): recv...I1226 07:23:55.385888 52708 hogwild_worker.cc:172] op[753]->Type(): recv
从上述日志中,可以看到前向传播和反向梯度下降的OP都是已经生成好的,前向和反向的OP大致都是对称的。包括参数更新相关的操作 send、recv 也是作为一个OP去运行的,具体重要的OP稍后分析。
数据流 Dataset/Datafeed
在
DeviceWorker::TrainFiles()里,会将数据读进来,数据的遍历通过以下2个函数:device_reader_->Start()和device_reader_->Next()void HogwildWorker::TrainFiles() { device_reader_->Start(); int cur_batch; while ((cur_batch = device_reader_->Next()) > 0) { ... } }这里的成员变量 devicereader 是在上层 MultiTrainer 初始化的时候设置的。先从上层的 dataset 中获取多个 readers。然后每个线程分配了一个 reader。
void MultiTrainer::Initialize(const TrainerDesc& trainer_desc, Dataset* dataset) { ... SetDataset(dataset); // get filelist from trainer_desc here const std::vector<paddle::framework::DataFeed*> readers = dataset->GetReaders(); // change thread num to readers num thread_num_ = readers.size(); VLOG(3) << "worker thread num: " << thread_num_; workers_.resize(thread_num_); for (int i = 0; i < thread_num_; ++i) { workers_[i]->SetDataFeed(readers[i]); }我们回到 python 层面的调用查看 dataset 的设置:
dataset = fluid.DatasetFactory().create_dataset() dataset.set_batch_size(g_batch_size) dataset.set_use_var(datas) dataset.set_pipe_command('python ' + g_read_python) dataset.set_thread(g_rd_thd_num) g_epoch_num = len(file_lists) for epoch_id in range(g_epoch_num): dataset.set_filelist(file_lists[epoch_id])Dataset 领域模型:
父类:DatasetBase
子类:QueueDataset、InMemoryDataset、FileInstantDataset。
工厂类:DatasetFactory
同样是通过工厂类 DatasetFactory()创建了一个dataset,里面指定了默认的 dataset 为 QueueDataset。class DatasetFactory(object): def create_dataset(self, datafeed_class="QueueDataset"): """ Create "QueueDataset" or "InMemoryDataset", or "FileInstantDataset", the default is "QueueDataset". """ try: dataset = globals()[datafeed_class]() return dataset ...继承了 DatasetBase 的子类会绑定 DataFeed 和 DataSet 的具体实现,而 QueueDataset() 的实现如下,通过这里父子类的初始化操作,我们可以知道,QueueDataset 的 datafeed 为 MultiSlotDataFeed,dataset 为 MultiSlotDataset
class DatasetBase(object): def __init__(self): self.dataset = core.Dataset("MultiSlotDataset") class QueueDataset(DatasetBase): def __init__(self): super(QueueDataset, self).__init__() self.proto_desc.name = "MultiSlotDataFeed"在 executor.py 里 train_from_dataset() 时,
def train_from_dataset(self, program=None, dataset=None, scope=None, thread=0, debug=False, fetch_list=None, fetch_info=None, print_period=100): // 准备数据 dataset._prepare_to_run() // 准备trainer scope, trainer = self._prepare_trainer( program=program, dataset=dataset, scope=scope, thread=thread, debug=debug, fetch_list=fetch_list, fetch_info=fetch_info, print_period=print_period) //这里传入的 dataset.dataset,也就是 QueueDataset.MultiSlotDataset self._default_executor.run_from_dataset(program.desc, scope, dataset.dataset, trainer._desc()) return NoneQueueDataset在
_prepare_to_run中又做了什么呢?主要是设置 MultiSlotDataset 的相关属性设置线程数: 1~len(self.filelist);
- 设置文件列表;
- 设置 datafeed 的类型;
创建 reader;
class QueueDataset(DatasetBase): def __init__(self): super(QueueDataset, self).__init__() self.proto_desc.name = "MultiSlotDataFeed" def _prepare_to_run(self): if self.thread_num > len(self.filelist): self.thread_num = len(self.filelist) if self.thread_num == 0: self.thread_num = 1 self.dataset.set_thread_num(self.thread_num) self.dataset.set_filelist(self.filelist) self.dataset.set_data_feed_desc(self.desc()) self.dataset.create_readers()上述对 MultiSlotDataset 的操作都包含在
data_set_py.cc文件中,这个文件相当于一个 pywrapper,将c++的实现封装好提供给python调用,所以直接查看data_set.cc的 c++ 实现即可。
c++层Dataset的领域模型:
接口类:Dataset
父类:DatasetImpl
子类:MultiSlotDataset
大部分的逻辑都在父类 DatasetImpl 中实现,我们跟踪 CreateReaders() 的实现:
threadnum 是用户层指定的读线程数,在调用时已经保证了读线程数的范围为 1~len(self.filelist),
根据读线程数,创建了相应个数的 readers,在这里会将所有的训练文件分给这些读线程,每个 reader 持有同一个互斥锁,用于分配训练文件时互斥访问。每一个 reader 就是一个 datafeed 的实例,这里对应的实现是 MultiSlotDataFeed。
除了上述 id、互斥锁、文件list 之外,每个reader对应一个 inputchannel、output_channel 和 consume_channel。
每个 dataset 持有一个 input_channel,多个 output_channel 和 consume_channel,后2者的个数相同,由 channel_num 决定,而 channelnum 的值由上层 python APIset_queue_num()设置。如果没有显示设置,则 channel_num 默认是1。// 构造函数 template <typename T> DatasetImpl<T>::DatasetImpl() { VLOG(3) << "DatasetImpl<T>::DatasetImpl() constructor"; thread_num_ = 1; trainer_num_ = 1; channel_num_ = 1; // channel 个数默认为1 file_idx_ = 0; cur_channel_ = 0; fleet_send_batch_size_ = 1024; fleet_send_sleep_seconds_ = 0; merge_by_insid_ = false; erase_duplicate_feas_ = true; keep_unmerged_ins_ = true; min_merge_size_ = 2; parse_ins_id_ = false; parse_content_ = false; preload_thread_num_ = 0; global_index_ = 0; } template <typename T> void DatasetImpl<T>::CreateChannel() { if (input_channel_ == nullptr) { input_channel_ = paddle::framework::MakeChannel<T>(); } if (multi_output_channel_.size() == 0) { multi_output_channel_.reserve(channel_num_); for (int i = 0; i < channel_num_; ++i) { multi_output_channel_.push_back(paddle::framework::MakeChannel<T>()); } } if (multi_consume_channel_.size() == 0) { multi_consume_channel_.reserve(channel_num_); for (int i = 0; i < channel_num_; ++i) { multi_consume_channel_.push_back(paddle::framework::MakeChannel<T>()); } } }多个 output_channel 和 consume_channel的意义在于多个 reader 可以从这些 channel 中并行的取数据。每个channel 可以被多个reader消费,但是每个reader只能消费一个 channel,因此channel 的个数应该要小于等于 reader 的个数。
I0103 03:22:54.418354 522012 data_set.cc:487] Calling CreateReaders() I0103 03:22:54.418373 522012 data_set.cc:488] thread num in Dataset: 1 I0103 03:22:54.418382 522012 data_set.cc:489] Filelist size in Dataset: 800 I0103 03:22:54.418391 522012 data_set.cc:490] channel num in Dataset: 1 I0103 03:22:54.418401 522012 data_set.cc:494] readers size: 0 I0103 03:22:54.418408 522012 data_set.cc:500] data feed class name: MultiSlotDataFeed I0103 03:22:54.418583 522012 data_set.cc:527] readers size: 1这里展示了 reader 被创建的过程。
template <typename T> void DatasetImpl<T>::CreateReaders() { int channel_idx = 0; for (int i = 0; i < thread_num_; ++i) { // 创建 MultiSlotDataFeed readers_.push_back(DataFeedFactory::CreateDataFeed(data_feed_desc_.name())); readers_[i]->Init(data_feed_desc_); readers_[i]->SetThreadId(i); readers_[i]->SetThreadNum(thread_num_); readers_[i]->SetFileListMutex(&mutex_for_pick_file_); readers_[i]->SetFileListIndex(&file_idx_); readers_[i]->SetFileList(filelist_); readers_[i]->SetParseInsId(parse_ins_id_); readers_[i]->SetParseContent(parse_content_); if (input_channel_ != nullptr) { readers_[i]->SetInputChannel(input_channel_.get()); } if (cur_channel_ == 0 && channel_idx < multi_output_channel_.size()) { readers_[i]->SetOutputChannel(multi_output_channel_[channel_idx].get()); readers_[i]->SetConsumeChannel(multi_consume_channel_[channel_idx].get()); } else if (channel_idx < multi_output_channel_.size()) { readers_[i]->SetOutputChannel(multi_consume_channel_[channel_idx].get()); readers_[i]->SetConsumeChannel(multi_output_channel_[channel_idx].get()); } ++channel_idx; if (channel_idx >= channel_num_) { channel_idx = 0; } } VLOG(3) << "readers size: " << readers_.size(); }因此 dataset 和 datafeed 的关系是?
一个 DataSet 持有多个 datafeed 作为 readers。遍历 dataset 就是并发的遍历每个 datafeed。而 datafeed 遍历使用 datafeed.Start(),datafeed.Next()。
接下来看 datafeed 的具体实现:
DataFeed 的领域模型:
接口:DataFeed
父类:PrivateQueueDataFeed、InMemoryDataFeed、PrivateInstantDataFeed
子类1:MultiSlotDataFeed (继承自 PrivateQueueDataFeed)、
子类2:MultiSlotInMemoryDataFeed (继承自InMemoryDataFeed)、
子类3:MultiSlotFileInstantDataFeed (继承自PrivateInstantDataFeed)
工厂类:DataFeedFactory
上文DataFeedFactory::CreateDataFeed()最终将通过DataFeedFactory调用new MultiSlotDataFeed()新建一个 datafeed 的实例。
这里跟踪 MultiSlotDataFeed 和 PrivateQueueDataFeed 的实现,看下MultiSlotDataFeed::Init()操作,设置了 batch_size 和 queue_size 的大小void MultiSlotDataFeed::Init( const paddle::framework::DataFeedDesc& data_feed_desc) { // 设置 batch_size SetBatchSize(data_feed_desc.batch_size()); // 设置 queue_size temporarily set queue size = batch size * 100 SetQueueSize(data_feed_desc.batch_size() * 100); ... }由前文我们知道,数据的读取是通过的 datafeed.Start() 和 datafeed.Next() 两个API进行的。
这2个函数的实现都在 PrivateQueueDataFeed 中,Start() 最终通过启动一个后台线程(启动之后detach)执行 ReadThread() 而结束:template <typename T> bool PrivateQueueDataFeed<T>::Start() { CheckSetFileList(); read_thread_ = std::thread(&PrivateQueueDataFeed::ReadThread, this); read_thread_.detach(); finish_start_ = true; return true; }重点查看 ReadThread() 逻辑:
每次随机选一个文件 PickOneFile(),一直到文件选取失败,也就是没有文件可选为止
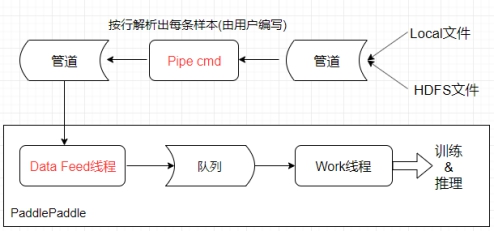
- 调用 fs_open_read 打开文件,其背后的实现支持本地文件读取和远程的hdfs文件读取,实际是通过管道传输的
调用子类重载的方法 ParseOneInstanceFromPipe,不断的从文件描述符中解析样本放入队列 queue,直到文件解析完毕。这里的 queue 就是上面的 dataset 提到的 Channel
template <typename T> void PrivateQueueDataFeed<T>::ReadThread() { std::string filename; while (PickOneFile(&filename)) { int err_no = 0; fp_ = fs_open_read(filename, &err_no, pipe_command_); __fsetlocking(&*fp_, FSETLOCKING_BYCALLER); T instance; while (ParseOneInstanceFromPipe(&instance)) { queue_->Put(instance); } } queue_->Close(); }再看看 Next() 的逻辑:
每次从 queue 中读取一个 batch 的数据,并将 instance 放入 vec 中
template <typename T> int PrivateQueueDataFeed<T>::Next() { CheckStart(); int index = 0; T ins_vec; while (index < default_batch_size_) { T instance; if (!queue_->Get(instance)) { break; } AddInstanceToInsVec(&ins_vec, instance, index++); } batch_size_ = index; if (batch_size_ != 0) { PutToFeedVec(ins_vec); } return batch_size_; }ReadThread() 和 Next() 的关系就构成了一个生产者消费者的模型。队列满,则 queue->Put() 操作就会阻塞;队列空,则 queue->Get() 就会阻塞。因此这里的队列性能和生产者消费者的速率有很大关系。
读取训练数据的逻辑理清了,还需要知道数据和训练网络的变量是如何结合起来的,在 python 层调用了dataset.set_use_var(datas)def set_use_var(self, var_list): multi_slot = self.proto_desc.multi_slot_desc for var in var_list: slot_var = multi_slot.slots.add() slot_var.is_used = True slot_var.name = var.name if var.lod_level == 0: slot_var.is_dense = True slot_var.shape.extend(var.shape) if var.dtype == core.VarDesc.VarType.FP32: slot_var.type = "float" elif var.dtype == core.VarDesc.VarType.INT64: slot_var.type = "uint64" else: raise ValueError( "Currently, fluid.dataset only supports dtype=float32 and dtype=int64" )data_feed.proto
message Slot { required string name = 1; required string type = 2; optional bool is_dense = 3 [ default = false ]; optional bool is_used = 4 [ default = false ]; repeated int32 shape = 5; // we can define N-D Tensor } message MultiSlotDesc { repeated Slot slots = 1; } message DataFeedDesc { optional string name = 1; optional int32 batch_size = 2 [ default = 32 ]; optional MultiSlotDesc multi_slot_desc = 3; optional string pipe_command = 4; optional int32 thread_num = 5; }DataFeed 的 data_feed.proto 定义
message Slot { required string name = 1; required string type = 2; optional bool is_dense = 3 [ default = false ]; optional bool is_used = 4 [ default = false ]; repeated int32 shape = 5; // we can define N-D Tensor } message MultiSlotDesc { repeated Slot slots = 1; } message DataFeedDesc { optional string name = 1; optional int32 batch_size = 2 [ default = 32 ]; optional MultiSlotDesc multi_slot_desc = 3; optional string pipe_command = 4; optional int32 thread_num = 5; }每个 datafeed 有多个slot,这里将所有变量都放在slot里。再看 datafeed 的初始化过程,遍历所有 slot 的定义,初始化 allslots,allslots_type,useslots_index 等属性信息。
void MultiSlotInMemoryDataFeed::Init( const paddle::framework::DataFeedDesc& data_feed_desc) { }datafeed 的领域模型
class DataFeed { protected: // the alias of used slots, and its order is determined by // data_feed_desc(proto object) std::vector<std::string> use_slots_; std::vector<bool> use_slots_is_dense_; // 所有的 slots 的别名, 和 proto 中传进来的顺序一致 std::vector<std::string> all_slots_; // 所有的 slots 类型 std::vector<std::string> all_slots_type_; // 使用了的 slot 的 shape std::vector<std::vector<int>> use_slots_shape_; std::vector<int> inductive_shape_index_; std::vector<int> total_dims_without_inductive_; // For the inductive shape passed within data std::vector<std::vector<int>> multi_inductive_shape_index_; // 正在使用的 slot 的index,如果没有使用则为-1,否则为 use_slots_ 的 index std::vector<int> use_slots_index_; // -1: not used; >=0: the index of use_slots_ // The data read by DataFeed will be stored here std::vector<LoDTensor*> feed_vec_; };datafeed 的值最终会读取到 feedvec
瞅瞅读数据做了啥,经过一系列的解析,最终输入的 hdfs 路径将会被转化为path="hdfs fs -cat /path/to/your/remote/data | pip_command_ "传入 fs_open_internal 函数中,其中会启动一个shell子进程去执行这个命令,并将结果通过管道传输到父进程,然后父进程,也就是训练进程通过读取管道的数据,逐行的传递给 ParseOneInstanceFromPipe,该函数的输入是样本文件经过ctr_dense_reader.py解析后的数据。void MultiSlotDataFeed::ReadThread() { std::string filename; while (PickOneFile(&filename)) { int err_no = 0; fp_ = fs_open_read(filename, &err_no, pipe_command_); std::vector<MultiSlotType> instance; int ins_num = 0; while (ParseOneInstanceFromPipe(&instance)) { ins_num++; queue_->Put(instance); } } queue_->Close(); }再瞅瞅 ctr_dense_reader.py 的实现:
class DatasetCtrReader(data_generator.MultiSlotDataGenerator): def __init__(self): super(DatasetCtrReader, self).__init__() self.sparse_slots, self.sparse_lr_slots, self.one_hot_slots_to_dims, self.dense_slots_to_dims = parser.parse_yaml(conf) def generate_sample(self, line): def iter(): # 1. parse slots ..... # 2. put slots to ret_result for slot in slots: ret_result.append(("dense_slot_" + str(slot), temp_dense)) # 3. put label to ret_result ret_result.append(("label", [1] if get_int(sent[0]) == 1 else [0])) yield tuple(ret_result) return iter if __name__ == "__main__": pairwise_reader = DatasetCtrReader() pairwise_reader.run_from_stdin()ctr_dense_reader.py 实现了一个迭代器,每一次迭代过程,接收一条样本数据,然后返回解析后的数据。
这里的数据格式和训练脚本中的 data 保持一致。
将 instances 存到 feed_vec 中void MultiSlotDataFeed::PutToFeedVec( const std::vector<MultiSlotType>& ins_vec) { #ifdef _LINUX for (size_t i = 0; i < use_slots_.size(); ++i) { if (feed_vec_[i] == nullptr) { continue; } const auto& type = ins_vec[i].GetType(); const auto& offset = ins_vec[i].GetOffset(); int total_instance = static_cast<int>(offset.back()); if (type[0] == 'f') { // float const auto& feasign = ins_vec[i].GetFloatData(); float* tensor_ptr = feed_vec_[i]->mutable_data<float>({total_instance, 1}, this->place_); CopyToFeedTensor(tensor_ptr, &feasign[0], total_instance * sizeof(float)); } else if (type[0] == 'u') { // uint64 // no uint64_t type in paddlepaddle const auto& feasign = ins_vec[i].GetUint64Data(); int64_t* tensor_ptr = feed_vec_[i]->mutable_data<int64_t>( {total_instance, 1}, this->place_); CopyToFeedTensor(tensor_ptr, &feasign[0], total_instance * sizeof(int64_t)); } LoD data_lod{offset}; feed_vec_[i]->set_lod(data_lod); if (use_slots_is_dense_[i]) { if (inductive_shape_index_[i] != -1) { use_slots_shape_[i][inductive_shape_index_[i]] = total_instance / total_dims_without_inductive_[i]; } feed_vec_[i]->Resize(framework::make_ddim(use_slots_shape_[i])); } } #endif }OP 的注册和运行
在 trainer 里循环调用 op_[i]->Run()
void OperatorBase::Run(const Scope& scope, const platform::Place& place) { ... RunImpl(scope, place); }OperatorBase 由 OperatorWithKernel 继承
class OperatorWithKernel : public OperatorBase
通过 REGISTER_OP_CPU_KERNEL() 将 OP_KERNEL 注册到OperatorWithKernel里,所有 OP_KERNEL 存在时一个map里,调用 OperatorBase::RunImpl 的时候,就是调用 OperatorWithKernel::RunImpl(),里面会调用 OpKernel::Compute()
OP_KERNEL 的实现class OpKernelBase class OpKernel : public OpKernelBase class AttentionLSTMKernel : public framework::OpKernel<T> Scope* OperatorWithKernel::PrepareData

若有收获,就点个赞吧
0 人点赞
