参考内容:官方API文档,下载链接:http://download.csdn.net/detail/kwgkwg001/4004500
虫师:《selenium2自动化测试实战-基于python语言》
转载来自:https://www.cnblogs.com/imyalost/p/7242747.html
一、WebDriver原理
1、关于WebDriver
设计模式:按照Server-Client的经典设计模式设计;
Server端:即Remote Server(远程服务器),可以是任意的浏览器,当脚本启动浏览器时,该浏览器就是Remote Server,它的职责是等待Client发送请求并做出响应;
Client端:简单来说就是我们的测试代码,测试代码中的一些行为是以HTTP请求的方式发送给被测试浏览器——Remote Server,Remote Server接受请求,执行相应操作,
并在Response中返回执行状态、返回值等信息;
2、WebDriver工作流程
①WebDriver启动目标浏览器,并绑定至指定端口,启动的浏览器实例将作为WebDriver的Remote Server;
②Client端通过CommandExcuter发送HTTPRequest给Remote Server的侦听端口(通信协议:the webdriver wire protocol);
③Remote Server需要依赖原生的浏览器组件(比如:chromedriver.exe)来转化浏览器的native调用;
3、WebDriver.log
python提供了logging模块给运行中的应用,提供了一个标准的信息输出接口。它提供了basicConfig方法用于基本信息的定义,开启debug模块,
就可以捕捉到Client端向Server端发送的请求,例子如下:
# coding=utf-8# 导入logging模块,捕捉Client发送的请求from selenium import webdriverimport loggingfrom selenium import webdriverfrom selenium.webdriver.support.select import Select # select类from selenium.webdriver.common.by import By #By类:定位元素logging.basicConfig(level=logging.DEBUG)driver = webdriver.Chrome("F:\安装工具\python\chromedriver.exe")driver.get("www.baidu.com")driver.find_element_by_id("kw").send_keys("selenium")driver.find_element_by_id("su").click()driver.quit()
二、WebDriver定位方法
WebDriver是基于selenium设计的操作浏览器的一套API,针对多种编程语言都实现了这套API,站在python角度来说,WebDriver是python的一个用于实现Web自动化的第三方库。
1、WebDriver定位方法
WebDriver定位方法提供了八种元素定位方法,所对应的方法、特性分别是:
2、XPath和CSS的类似功能对比

3、用By定位元素
针对前面介绍的8种定位方法,WebDriver还提供另一种方法,即:统一调用find_element()方法,通过By来声明定位方法,并且传入对应定位方法的定位参数,例子如下:
find.element()方法只用于定位元素,它需要两个参数,第一个参数是定位的类型,由By提供,第二个参数是定位的具体方式,在使用By之前需要将By类导入;
# 导入By类的包from selenium.webdriver.common.by import Byfind.element(by.id,"kw")find.element(by.name,"wd")find.element(by.class_name,"s_ipt")find.element(by.tag_name,"input")find.element(by.link_text,"新闻")find.element(by.partial_link_text,"新")find.element(by.xpath,"//*[@class='bg s_btn'")find.element(by.css_selector,"span.bg s_btn_wr>input#su")
4、定位一组元素
上面提到的8种定位方法,都是针对单个元素定位的,webdriver还提供了与之对应的8种用于定位一组元素的方法。其一般应用于以下场景:
①批量操作元素,例如勾选页面上所有的复选框;
②先获取一组元素,再从这组元素中过滤出需要操作的元素;
定位一组元素的方法与定位单个元素的用法相似,唯一的区别是在element后面多一个s表示复数,具体如下:
# webdriver提供的定位一组元素方法id find_elements_by_id()Name find_elements_by_name()class_name find_elements_by_class_name()tag Name find_elements_by_tag_name()link text find_elements_by_link_text()partial link text find_elements_by_partial_link_text()xpath find_elements_by_xpath()css selector find_elements_by_css_selector()
获取一组元素中某个元素的几个方法:
len():用来计算元素的个数,通过print()打印出计算的结果;
pos()或pop(-1):默认获取一组元素的最后一个元素,并返回该元素的值;
pop(0):默认获取一组元素的第一个元素,并返回该元素的值;
pop(1):默认获取一组元素的第二个元素,并返回该元素的值;
……
三、WebElement接口常用方法
通常需要与页面交互的方法都由WebElement接口提供,包括上面提到的8种定位方法,下面介绍常用的几种方法:
submit():用于提交表单,例如搜索框输入关键字之后的“回车”操作,例如:
# 提交表单from select import webdriverdriver = webdriver.Chrome("安装工具\python\chromedriver.exe")driver.get("http://www.baidu.com")driver.find_element_by_id("kw").send_keys("imyalost")# 提交输入框中的内容driver.find_element_by_id("imyalost").submit()driver.quit()
注意:有时候submit()方法和click()方法可以互用,但submit()的应用范围不及click()广泛;
clear():清除文本;
send_keys(*value):模拟按键输入;
click():单击元素;
size:返回元素的尺寸;
text:获取元素的文本;
get.attribute(name):获得属性值;
is_displayed():设置该元素是否用户可见;
# webelement接口常用方法from selenium import webdriverdriver = webdriver.Chrome("安装工具\python\chromedriver.exe")driver.get("http://www.baidu.com")# 获得输入尺寸size = driver.find_element_by_id("kw").sizeprint("size")# 返回百度页面底部备案信息text = driver.find_element_by_id("cp").textprint("text")# 返回元素的属性值,可以是id、name、type或其他属性attribute = driver.find_element_by_id("kw").get_attribute("type")print("attribute")# 返回元素结果是否可见,返回结果为True或Flaseresult = driver.find_element_by_id("kw").is_displayed()print("result")
PS:上面的例子取自百度首页,关于UI自动化,建议系统的了解学习一下前端相关的基础知识,可以去W3C看看。。。
selenium自动化操作
转载来自:https://zhuanlan.zhihu.com/p/149718642?from_voters_page=true
1.selenium是什么
如果大家有做过web的自动化测试,相信对于selenium一定不陌生,测试人员经常使用它来进行自动化测试。
selenium最初是一个自动化web测试工具,通过代码模拟人使用浏览器自动访问目标站点并操作,比如跳转、输入、点击、下拉等。由于开发者的不断完善,目前的功能越来越强大,基本支持各种交互操作。同时,不止支持有界浏览,还支持无界浏览。
2.selenium有什么用
正如我们前面讲过的,爬虫的本质过程就是模拟人对浏览器的操作过程。在爬虫中使用,selenium主要是为了解决requests无法执行javaScript代码的问题。
本质上是通过驱动浏览器,完全模拟浏览的操作,比如跳转、输入、点击、下拉等…进而进行跳转。
当然,它也有坏处,主要的坏处就是它的速度比较慢。原因是selenium在操作时,需要等浏览器对页面的元素渲染好之后才能操作。而我们知道,由于页面渲染过程需要加载各种资源,响应速度与网络带宽要求非常高。通常情况,它比静态页面的响应至少慢一个数量级。
3.如何使用selenium
在知道selenium是什么以及有什么用之后,我们来具体学习如何操作这个工具。
由于selenium本质是模拟人对浏览器进行输入、选择、点击等操作,因此对于目标标签的定位非常重要。
在前面的章节,我们对于如何定位目标标签有过详细的介绍,这里就不再赘述。selenium对于目标标签定位的方式本质与静态的页面一样,只不过因为使用的包不同,因此在beautifulSoup中使用的是find和findAll,而在selenium中使用的接口有所变化。
下图中已对各种定位方式进行了归纳总结:
 在找到目标标签之后,最重要的是对这些标签进行模拟操作。Selenium库下webdriver模块常用方法主要分类两类:一类是模拟浏览器、键盘操作,另一类是模拟鼠标操作。
在找到目标标签之后,最重要的是对这些标签进行模拟操作。Selenium库下webdriver模块常用方法主要分类两类:一类是模拟浏览器、键盘操作,另一类是模拟鼠标操作。
2.1模拟浏览器、键盘操作

2.2 模拟鼠标操作

4.示例演示
在介绍了selenium相关的使用方法之后,我们来进行操作。这里介绍两个例子:第一个例子是模拟百度搜索,第二个例子是模拟自动登录网易163邮箱发送邮件。
在开始示例之前我们需要安装selinum插件包,同时还需要下载webdriver。在我们的示例中,需要是使用chrome浏览器进行操作,需要使用浏览器的驱动webdriver。
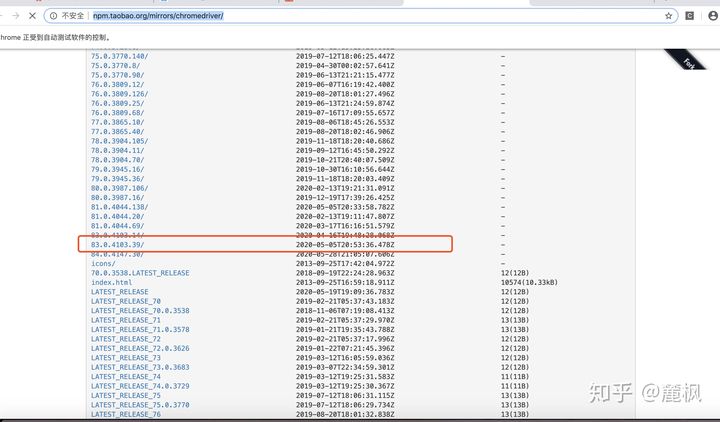
关于下载什么版本的webdriver,可以在浏览器的属性中查看,并在http://npm.taobao.org/mirrors/chromedriver/下载对应的版本就好,如果是其他的浏览器,则需要下载对应的浏览器驱动程序,这种不再做进一步介绍。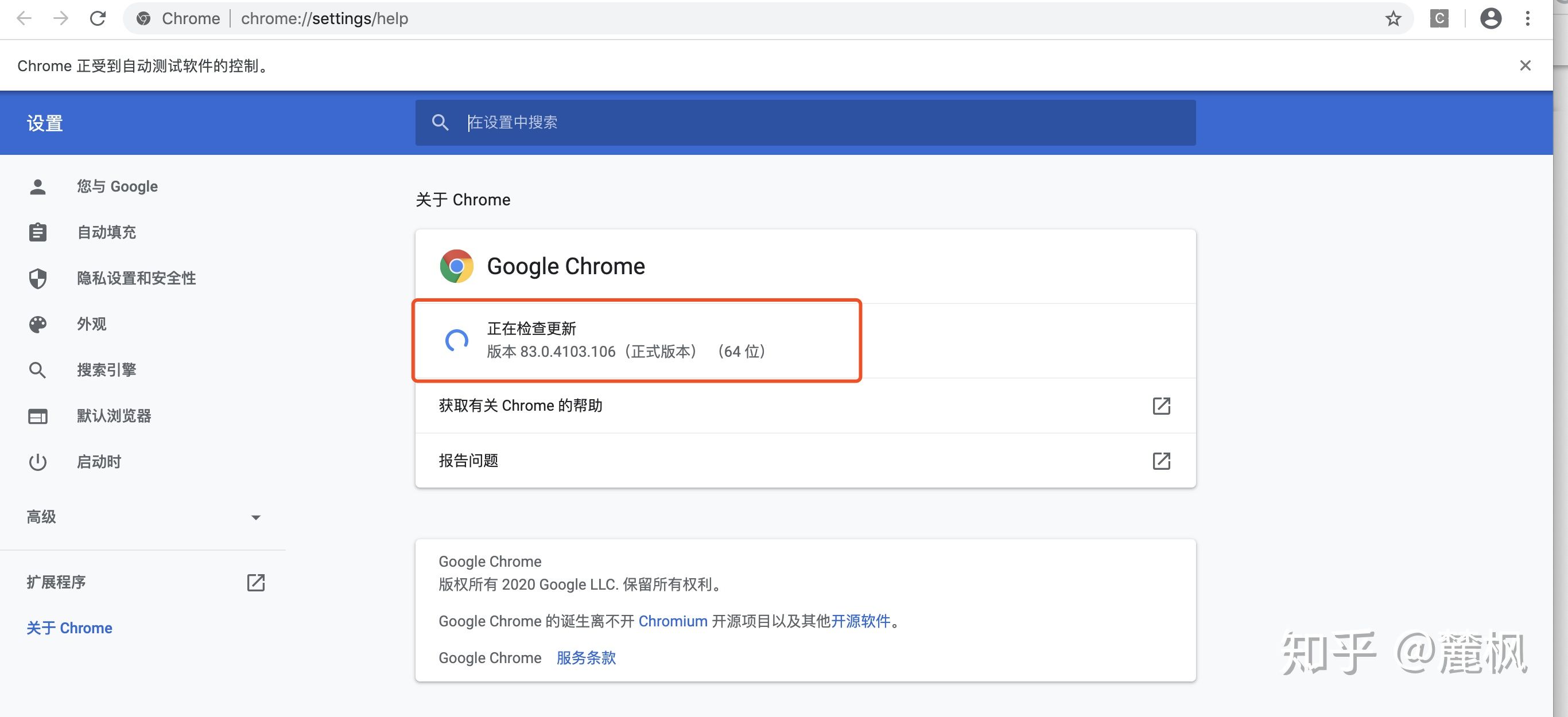
4.1模拟百度搜索
第一步还是需要打开目标的地址“w w w.baidu.com”,分析目标网页中目标元素的特点,如下图所示:
通过分析,我们很容易就找到搜索框的id为kw,点击按钮的id为su,余下的就是使用方法进行模拟。
实现的代码如下所示:
from selenium import webdriver#get 方法 打开指定网址driver=webdriver.Chrome()driver.get('http://www.baidu.com')#选择网页元素element_keyword = driver.find_element_by_id('kw')#输入字符element_keyword.send_keys('python 爬虫')#找到搜索按钮element_search_button = driver.find_element_by_id('su')element_search_button.click()driver.close()

4.2模拟自动登录网易163邮箱发送邮件
操作过程跟上面相似,第一步也是分析目标网页http://mail.163.com。如下图所示:
找到了目标标签然后就是模拟登录。实现代码如下:
# coding:UTF-8import timefrom selenium.webdriver.common.keys import Keysfrom selenium import webdriverdriver = webdriver.Chrome()driver.implicitly_wait(5)driver.get('http://mail.163.com/')driver.switch_to_frame(driver.find_element_by_tag_name('iframe'))# driver.switch_to_frame('x-URS-iframe')driver.find_element_by_name('email').clear()driver.find_element_by_name('email').send_keys('邮箱地址')driver.find_element_by_name('password').send_keys('邮箱密码', Keys.ENTER)# 跳转页面时,强制等待6stime.sleep(6)# 点击写信按钮driver.find_element_by_xpath("//div[@id='dvNavTop']/ul/li[2]/span[2]").click()time.sleep(2)# 收件人driver.find_element_by_class_name('nui-editableAddr-ipt').send_keys('目标的邮箱')driver.find_element_by_xpath("//input[@class='nui-ipt-input' and @type='text' and @maxlength='256']").send_keys(u'测试') # 主题xpath = driver.find_element_by_xpath("//div[@class='APP-editor-edtr']/iframe")# 文本内容在iframe中driver.switch_to_frame(xpath)driver.find_element_by_xpath("//body[@class='nui-scroll' and @contenteditable='true']").send_keys(u'这是一个自动化测试邮件')# 发送按钮在iframe外,所以需要跳出driver.switch_to_default_content()# 发送driver.find_element_by_xpath("//div[@class='nui-toolbar-item']/div/span[2]").click()driver.close()
 当然,在实际过程中,可能往往还有验证码的验证。因为现在的验证码难度越来越大,形式也多种多样,使用常规的方法很难解决,必须借助机器学习或者第三方接口进行实现,将在后续单独列一个章节进行介绍如何破解验证码。
当然,在实际过程中,可能往往还有验证码的验证。因为现在的验证码难度越来越大,形式也多种多样,使用常规的方法很难解决,必须借助机器学习或者第三方接口进行实现,将在后续单独列一个章节进行介绍如何破解验证码。

若有收获,就点个赞吧
0 人点赞
