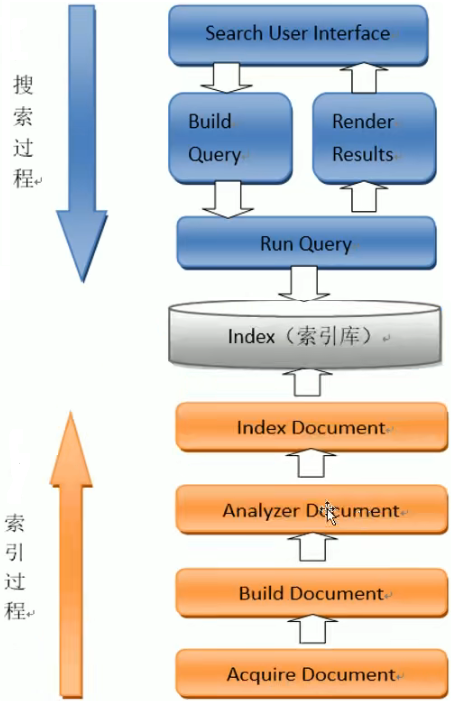
1. 索引和搜索流程
Lucene文件检索,从原始内容中搜索的内容:获取文档、创建文档、分析文档和检索文档。客户端的搜索过程:根据搜索的索引内容,创建查询,执行搜索,再渲染结果。
2. 常见概念
Field(域)
Field是文档中的域,包括Field名和Field值两部分;一个文档可以包括多个Field,Document只是Field的一个承载体,Field值既要索引的内容,又要搜索的内容!
- 是否分词: 是否将Field值进行分词,分词的目的是为了索引。
比如: 需要分词的有—商品名称、商品描述; 不需要分词的有—商品id、订单号、身份证等。
- 是否索引: 是否Field分词后的词或整个Field,并存储到索引域,索引的目的就是为了搜索。
比如: 需要索引的有—商品名称、商品描述、订单号、身份证号; 不索引的有—图片名称、文件路径等。
- 是否存储:是否将Field值存储到文档中,存储在文档域中的Field才可以从Document中获取。
| Field类 | 数据类型 | Analyzed是否分词 | Indexed是否索引 | Stored是否存储 | 说明 |
|---|---|---|---|---|---|
| StringField(FieldName, FieldValue,Store.YES) | 字符串 | 否 | 是 | Y / N | 创建一个字符串的Field,但不会进行分词。会将整个串存储在索引中,比如(订单号、身份证号等) |
| TextField(FieldName, FieldValue, Store.NO) 或 TextField(FieldName, reader) |
字符串 或 流 | 是 | 是 | Y / N | 若是Reader,lucene猜测内容会比较多,采用Unstored的策略。 |
| IntPoint(FieldName, FieldValue) | Integer类型 | 是 | 是 | 否 | 创建一个Integer数字类型的Field,进行分词和索引,不存储 |
| FloatPoint(FieldName, FieldValue) | Float型 | 是 | 是 | 否 | 创建一个Float类型的Field,进行分词和索引,不存储,比如(价格) |
| DoublePoint(FieldName, FieldValue) | Double | 是 | 是 | 否 | 创建一个Double类型的Field,进行分词和索引,不做存储。 |
| StoredField(FieldName, FieldValue) | 重载方法,支持多种类型 | 否 | 否 | 是 | 不同类型Filed,不分析、不索引,但是存储 |
索引的维护:
索引的更新,采用的方式是:先删除再添加的模式。所以当进行更新的时候,可以先查询出来,切丁更新记录存在再执行索引的更新。
/* 更新索引的操作 */public void updateIndex() throws Exception {// 1.创建分词器Analyzer analyzer = new StandardAnalyzer();// 2.创建Directory流对象Directory directory = FSDirectory.open(Paths.get("E:\\indexDir"));// 3.创建IndexWriteConfig对象,写入索引需要的配置IndexWriteConfig config = new IndexWriterConfig(analyzer);// 4.创建写入对象IndexWriter indexWriter = new IndexWriter(directory, config);// 5.创建DocumentDocument doc = new Document();doc.add(new TextField("name", "测试用的规则", Field.Store.YES));// 6.执行更新,把所有符合条件的Document删除,再添加。indexWriter.updateDocument(new Term("name", "测试规则"), doc);// 7.释放资源indexWriter.close();}
/* 删除指定的索引 */
public void deleteIndex() throws Exception() {
// 创建分词器
Analyzer analyzer = new Analyzer();
// 创建DIrectory流对象
Directory directory= FSDirectory.open(Paths.get("E:\\indexDir"));
// 创建IndexWriterConfig 和 IndexWriter
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 根据Term删除索引库,name:java
indexWriter.deleteDocumjents(new Term("name", "测试规则"));
// 释放资源
indexWriter.close();
}
/* 删除全部的索引 */
public void deleteAllIndex() throws Exception() {
// 创建分词器
Analyzer analyzer = new Analyzer();
// 创建DIrectory流对象
Directory directory= FSDirectory.open(Paths.get("E:\\indexDir"));
// 创建IndexWriterConfig 和 IndexWriter
IndexWriterConfig config = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, config);
// 删除全部的索引
indexWriter.deleteAll();
// 释放资源
indexWriter.close();
}
Analyzer分词器:
输入关键字进行搜索,需要让关键字域文档域内容所包含的词进行匹配时,需要对文档域内容进行分析,需要经过Analyzer分词器处理生成词汇单元(Token);分词器分析的对象是文档中的Field域。当Field的属性tokenized(是否分词)为True,才会对Field值进行分析。
/* whitespaceAnalyzer分词器 */
public void WhitespaceAnalyzer() throws Exception {
// 1.创建分词器
Analyzer analyzer = new whitespaceANalyzer();
// 2.创建Directory对象,申明索引库的位置
Directory directory = FSDirectory.open(Paths.get("E:\\index_dir"));
// 3.创建IndexWriteConfig对象,写入索引需要的配置
IndexWriteConfig config = new IndexWriterConfig(analyzer);
// 4.创建IndexWriter 写入对象
IndexWriter indexWriter = new IndexWriter(directory, config);
// 5.写入到索引库,通过IndexWriter添加文件对象Document
Document doc = new Documnet();
doc.add(new TextField("name", "xiaomi G12", Field.Store.YES));
indexWriter.addDocument(doc);
// 6.释放资源
indexWriter.close();
}
3. 高级搜索
索引对象:
- 文本索引方式: queryParser
- 数值范围索引: IntPoint.newRangeQuery
索引的关系:
- BooleanClause.Occur.MUST 并且的关系, 相当于and
- BooleanClause.Occur.SHOULD 或者的关系,相当于or
- BooleanClause.Occur.MUST_NOT 非(取反)的关系,相当于not
/**
* TermQuery: 词条搜索(单个关键字查找)
*/
priavate void testQuery() {
...
IndexReader reader = DirectoryReader.open(FSDirectory.open(Path("E:\\index")));
IndexSearcher searcher = new IndexSearcher(reader);
// 1. 单个词条的索引:
Query query = new TermQuery(new Term("city", "厦门"));
TopDocs topDocs = searcher = searcher.search(query, 100);
System.out.println("共检索出 " + topDocs.totalHits + " 条记录");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDocs scDoc : scoreDocs) {
Document document = searcher.doc(scDoc.doc);
String name = document.get("name");
String gender = document.get("gender");
float score = scDoc.score;
System.out.println("查询到的内容:name:%s, gender:%s, 相似度:%s", name, gender, score);
}
...
// 关闭资源
reader.close();
}
/**
* 组合搜索(允许多个关键字组合搜索)
* BooleanClause.Occur.MUST:必须包含,类似于逻辑运算的与<br/>
* BooleanClause.Occur.MUST_NOT:必须不包含,类似于逻辑运算的非<br/>
* BooleanClause.Occur.SHOULD:可以包含,类似于逻辑运算的或<br/>
*/
priavate void testBooleanQuery() {
...
IndexReader reader = DirectoryReader.open(FSDirectory.open(Path("E:\\index")));
IndexSearcher searcher = new IndexSearcher(reader);
// 创建查询对象(第一个参数,默认查询域,第二个参数使用的分词器)
// 设置搜索关键词
// 可以多个query同时存在
QueryParser parser1 = LuceneUtil.createQueryParser("name", analyzer);
Query nameQuery = parser1.parse(key);
QueryParser parser2 = LuceneUtil.createQueryParser("brand", analyzer);
Query brandQuery = parser2.parse(key);
BooleanQuery.Builder query = new BooleanQuery.Builder();
query.add(nameQuery, BooleanClause.Occur.SHOULD);
query.add(brandQuery, BooleanClause.Occur.SHOULD);
TopDocs topDocs = searcher = searcher.search(query.build, 100);
System.out.println("共检索出 " + topDocs.totalHits + " 条记录");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
...
// 关闭资源
reader.close();
}
/**
* 多短语搜索(先指定一个前缀关键字,然后其他的关键字加在此关键字之后,组成词语进行搜索)<br/>
*
*/
priavate void testBooleanQuery() {
...
IndexReader reader = DirectoryReader.open(FSDirectory.open(Path("E:\\index")));
IndexSearcher searcher = new IndexSearcher(reader);
// 查询“计张”、“计钦”组合的关键词,先指定一个前缀关键字,然后其他的关键字加在此关键字之后,组成词语进行搜索
Term term = new Term("name", "计"); // 前置关键字
Term term1 = new Term("name", "张"); // 搜索关键字
Term term2 = new Term("name", "钦"); // 搜索关键字
MultiPhraseQuery multiPhraseQuery = new MultiPhraseQuery();
multiPhraseQuery.add(term);
multiPhraseQuery.add(new Term[] { term1, term2 });
TopDocs topDocs = searcher.search(multiPhraseQuery, 1000);
System.out.println("共检索出 " + topDocs.totalHits + " 条记录");
ScoreDoc[] scoreDocs = topDocs.scoreDocs;
for(ScoreDocs scDoc : scoreDocs) {
Document document = searcher.doc(scDoc.doc);
String name = document.get("name");
String gender = document.get("gender");
float score = scDoc.score;
System.out.println("查询到的内容:name:%s, gender:%s, 相似度:%s", name, gender, score);
}
...
// 关闭资源
reader.close();
}
/**
* 数值范围的过滤器: int、long、float等类型
*/
public void numericFilter() throws Exception {
// CustomScoreQuery
// Filter filter = NumericRangeFilter.newLongRange("id", 1l, 3l, true, true);
Filter filter = NumericRangeFilter.newIntRange("age", 1, 39, true, true);
List<Person> persons = search(filter, new String[] { "name", "city" }, "厦门");
for (Person person : persons) {
System.out.println(String.format(
"id:%s, name:%s, age:%s, city:%s, birthday:%s.", person.getId(),
person.getName(), person.getAge(), person.getCity(),
DateUtils.dateToString(person.getBirthday(), Consts.FORMAT_SHORT)));
}
}
/**
* 时间范围过滤器
*/
public void dateFilter() throws Exception {
// 2008-06-12
long min = DateUtils.stringToDate("2008-06-12", Consts.FORMAT_SHORT).getTime();
// 2013-01-07
long max = DateUtils.stringToDate("2013-01-07", Consts.FORMAT_SHORT).getTime();
Filter filter = NumericRangeFilter.newLongRange("birthday", min, max,true, true);
List<Person> persons = search(filter, new String[] { "name", "city" },"厦门");
for (Person person : persons) {
System.out.println(String.format(
"id:%s, name:%s, age:%s, city:%s, birthday:%s.", person.getId(),
person.getName(), person.getAge(), person.getCity(),
DateUtils.dateToString(person.getBirthday(), Consts.FORMAT_SHORT)));
}
}

若有收获,就点个赞吧
0 人点赞
