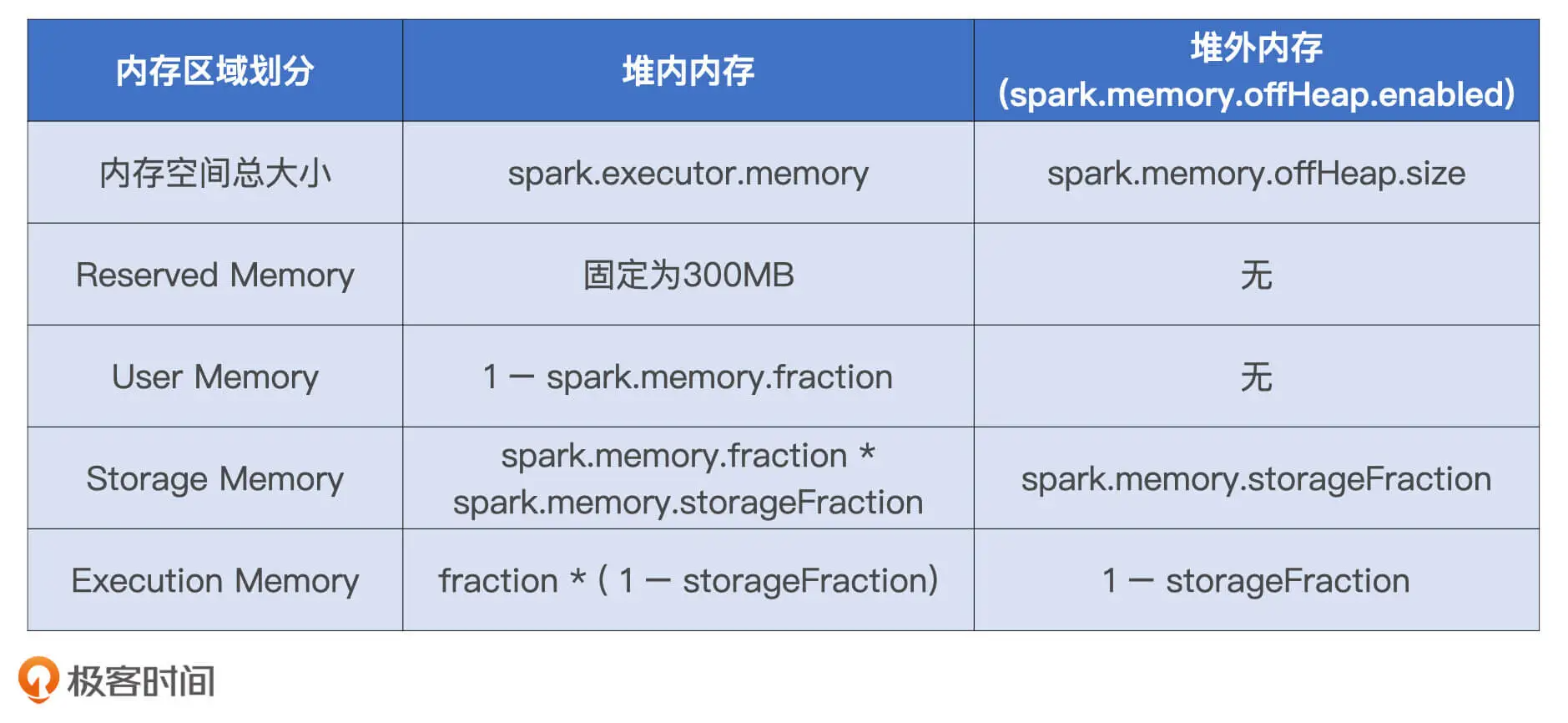
Spark 会区分堆内内存(On-heap Memory)和堆外内存(Off-heap Memory)。这里的“堆”指的是 JVM Heap,因此堆内内存实际上就是 Executor JVM 的堆内存;堆外内存指的是通过 Java Unsafe API,像 C++ 那样直接从操作系统中申请和释放内存空间。
堆外内存。Spark 把堆外内存划分为两块区域:一块用于执行分布式任务,如 Shuffle、Sort 和 Aggregate 等操作,这部分内存叫做 Execution Memory;一块用于缓存 RDD 和广播变量等数据,它被称为 Storage Memory。
堆内内存的划分方式和堆外差不多,Spark 也会划分出用于执行和缓存的两份内存空间。不仅如此,Spark 在堆内还会划分出一片叫做 User Memory 的内存空间,它用于存储开发者自定义数据结构。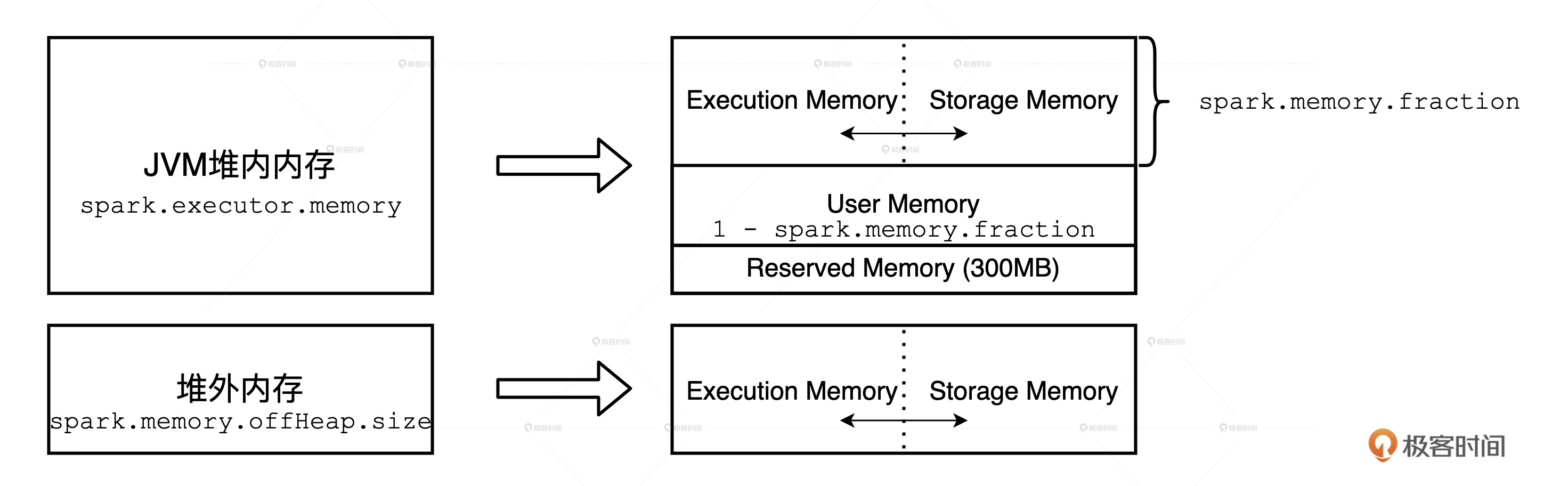
除此之外,Spark 在堆内还会预留出一小部分内存空间,叫做 Reserved Memory,它被用来存储各种 Spark 内部对象,例如存储系统中的 BlockManager、DiskBlockManager 等等。
Execution Memory:执行分布式任务
Storage Memory:缓存RDD,广播变量,shuffle中间文件(在哪?)
User Memory:用户自定义数据结构
Reserved Memory:Spark 内部对象,例如存储系统中的 BlockManager、DiskBlockManager(见存储系统篇章)
Execution Memory 和 Storage Memory
1.6版本以前是固定的,即便你没有缓存任何 RDD 或是广播变量,Storage Memory 区域的空闲内存也不能用来执行 Shuffle 中的映射、排序或聚合等操作,因此宝贵的内存资源就被这么白白地浪费掉了。
在 1.6 版本之后,Spark 推出了统一内存管理模式。统一内存管理指的是 Execution Memory 和 Storage Memory 之间可以相互转化,尽管两个区域由配置项 spark.memory.storageFraction 划定了初始大小,但在运行时,结合任务负载的实际情况,Storage Memory 区域可能被用于任务执行(如 Shuffle),Execution Memory 区域也有可能存储 RDD 缓存。
执行任务相比缓存任务,在内存抢占上有着更高的优先级。一类是 Shuffle Map 阶段的数据转换、映射、排序、聚合、归并等操作;另一类是 Shuffle Reduce 阶段的数据排序和聚合操作。它们所涉及的数据结构,都需要消耗执行内存。
Execution Memory 和 Storage Memory 之间的抢占规则,一共可以总结为 3 条:
- 如果对方的内存空间有空闲,双方就都可以抢占;
- 对于 RDD 缓存任务抢占的执行内存,当执行任务有内存需要时,RDD 缓存任务必须立即归还抢占的内存,涉及的 RDD 缓存数据要么落盘、要么清除;
- 对于分布式计算任务抢占的 Storage Memory 内存空间,即便 RDD 缓存任务有收回内存的需要,也要等到任务执行完毕才能释放。

若有收获,就点个赞吧
0 人点赞
