
相关组件
DAGScheduler 就是需求端,SchedulerBackend 就是供给端。那么中间还需要有个中介 TaskScheduler 来帮它们对接意愿、撮合交易,从而最大限度地提升资源配置的效率
1. DAGScheduler
1.1 DAG 到 Stages 的拆分过程
那就是:以 Actions 算子为起点,从后向前回溯 DAG,以 Shuffle 操作为边界去划分 Stages。
1.2 Stages的计算步骤
Spark从后向前,以递归的方式,依次提请执行所有的 Stages。如果发现了 Stage1 的计算依赖Stage0 ,就会把 Stage1 的计算动作压栈,转而去执行 Stage0。当 Stage0 执行完毕的时候,DAGScheduler 通过出栈的动作,再次执行 Stage 1。
1.3 Task的属性

1.4 DAG 的作用
根据用户代码构建 DAG,以 Shuffle 为边界切割 Stages,基于 Stages 创建 TaskSets,并将 TaskSets 提交给 TaskScheduler 请求调度。
1.5 DAGScheduler 在创建 Tasks 的过程中,是如何设置每一个任务的本地性级别?
preferredLocations。但是,它想要去的executors,可能正在忙,没有空闲cpu。
这个时候两个选择,要么,等executors忙完;要么放弃,调度到其他节点或是executors,退而求其次。locality wait默认3s,但是可以调。不过一般3s就行。除非有些io密集型,必须要node local,这个时候,可以适当调大,多等等。
2. TaskScheduler
2.1 不同 Stages 之间的调度优先级
TaskScheduler 提供了 2 种调度模式,分别是
FIFO(先到先得)
FAIR(公平调度):哪个 Stages 优先被调度,取决于配置文件 fairscheduler.xml 中的定义。
2.2 相同 Stages 内不同任务之间的调度优先级
Stages 内部的任务调度相对来说简单得多。当 TaskScheduler 接收到来自 SchedulerBackend 的 WorkerOffer 后,TaskScheduler 会优先挑选那些满足本地性级别要求的任务进行分发。众所周知,本地性级别有 4 种:Process local < Node local < Rack local < Any。从左到右分别是进程本地性、节点本地性、机架本地性和跨机架本地性。从左到右,计算任务访问所需数据的效率越来越差。
注意它这里调度的是任务,而不是数据,DAGScheduler 划分 Stages、创建分布式任务的过程中,会为 tasks 标识本地性级别,本地性级别中会记录该 Tasks 有意向的计算节点地址,甚至是 Executor 进程 ID。换句话说,任务自带调度意愿,它通过本地性级别告诉 TaskScheduler 自己更乐意被调度到哪里去。
2.3 在计算与存储分离的云计算环境中,Node local 本地性级别成立吗?你认为哪些情况下成立?哪些情况下不成立?
3. SchedulerBackend
作用:判断哪些节点的计算资源空闲,然后再把任务分发过去
如何判断不同模式下的实例对象:Spark 根据用户提供的 MasterURL,来决定实例化哪种实现类的对象。(Standalone、YARN 和 Mesos这种就是不同模式)
可用的计算资源会用一个叫做 ExecutorDataMap 的数据结构,来记录每一个计算节点中 Executors 的资源状态。
ExecutorDataMap 是一种 HashMap
Key —-> 标识不同的Executor
Value —-> 数据结构为 ExecutorData 用于封装 Executor 的资源状态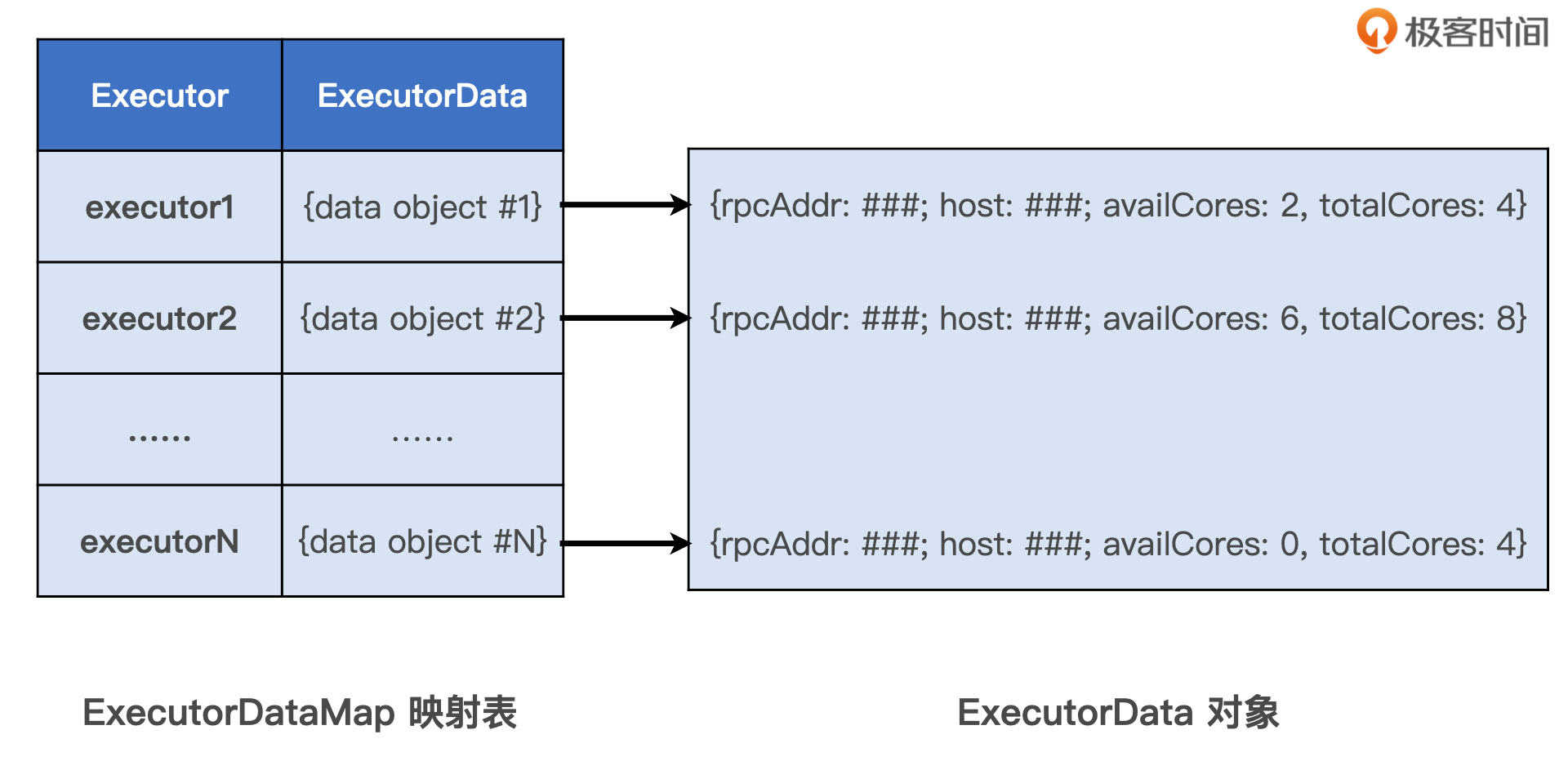
WorkerOffer —-> 提供计算资源的单位(封装了 Executor ID、主机地址和 CPU 核数),用来表示一份可用于调度任务的空闲资源。SchedulerBackend 可以同时提供多个 WorkerOffer 用于分布式任务调度。
调度系统的五个步骤
- 将 DAG 拆分为不同的运行阶段 Stages(DAGScheduler)
- 创建分布式任务 Tasks 和任务组 TaskSet(DAGScheduler)
- 获取集群内可用的硬件资源情况(SchedulerBackend)
- 按照调度规则决定优先调度哪些任务 / 组(TaskScheduler)
- 依序将分布式任务分发到执行器 Executor(TaskScheduler)
Spark 调度系统的原则是尽可能地让数据呆在原地、保持不动,同时尽可能地把承载计算任务的代码分发到离数据最近的地方,从而最大限度地降低分布式系统中的网络开销
TaskScheduler 根据本地性级别选出待计算任务之后,先对这些任务进行序列化。然后,交给 SchedulerBackend,SchedulerBackend 根据 ExecutorData 中记录的 RPC 地址和主机地址,再将序列化的任务通过网络分发到目的主机的 Executor 中去。最后,Executor 接收到任务之后,把任务交由内置的线程池,线程池中的多线程则并发地在不同数据分片之上执行任务中封装的数据处理函数,从而实现分布式计算。
注意事项(评论区才是精华)
一、资源调度和任务调度
Spark任务调度之前实则已经完成了资源调度,启动 Spark 任务的时候已经通过配置项指定了 Executor 的资源,SchedulerBackend的调度器是需要这些信息的。
资源调度使用的是 ExecutorDataMap 对 Executor 做资源画像,对外提供 WorkerOffer(是谁来接受这些offer?TaskScheduler吗?)
ExecutorData 并没有存储内存相关的信息,TaskScheduler要达到任务分配的目的,只需知道CPU就可以了。
再来说Free Memory,每个Executors的可用内存都会随着GC的执行而动态变化,因此,ExecutorData记录的Free Memory,永远都是过时的信息。所以一是Spark对于内存的预估不准,二来确实没用,因为TaskScheduler拿不到数据分片大小这样的信息,TaskScheduler在Driver端,而数据分片是在目标Executors,所以TaskScheduler拿到Free Memory也没啥用,因为它也不能判断说:task要处理的数据分片,是不是超过了目标Executors的可用内存。
二、Spark的高阶函数
例子中看起来好像就是第一个是输入参数后再开始构建字典,然后去比对,第二个是先构建好了字典,直接去比对
应该其实就是把构建字典的操作放到了Driver端

若有收获,就点个赞吧
0 人点赞
