3.1 Standalone 模式
3.1.1 安装
解压缩 flink - 1.7.2 - bin - hadoop27 - scala_2.11.tgz ,进入 conf 目录中。
(1) 修改 flink/conf/flink - conf.yaml 文件
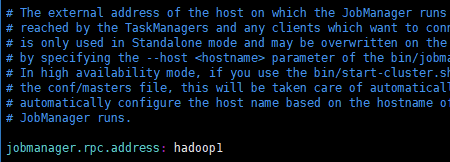
(2) 修改 /conf/slave 文件

(3) 分发给另外两台机子

(4) 启动
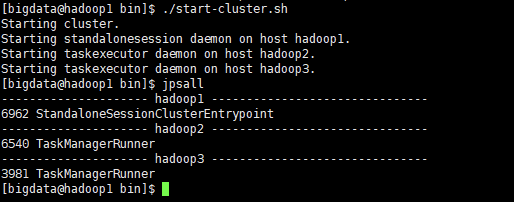
访问 http://localhost:8081 可以对 flink 集群和任务进行监控管理。
3.1.2 提交任务
(1) 准备数据文件
(2) 把含数据文件的文件夹, 分发到 taskmanage 机器中

由于读取数据是从本地磁盘读取, 实际任务会被分发到 taskmanage 的机器中, 所以要把目标文件分发。
(3) 执行程序
$ ./flink run -c com.atguigu.flink.app.BatchWcApp /ext/flinkTest-1.0-SNAPSHOT.jar --input /applog/flink/input.txt --output /applog/flink/output.csv
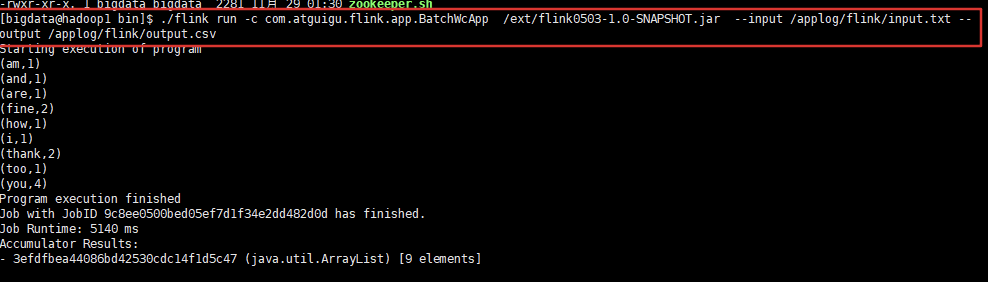
(4) 到目标文件夹中查看计算结果注意:计算结果根据会保存到 taskmanage 的机器下, 不会在 jobmanage 下
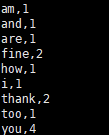
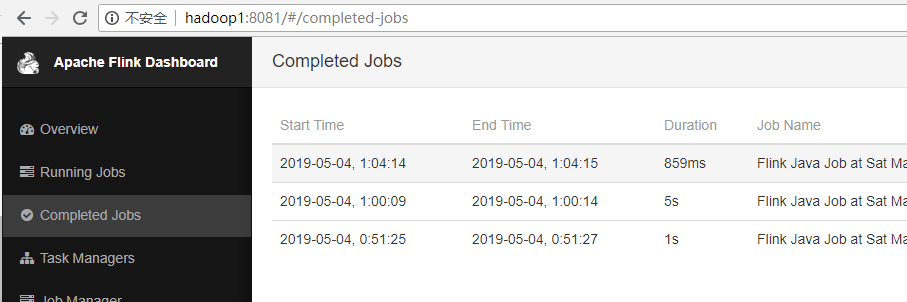
(5) 在 webui 控制台查看计算过程
3.2 Yarn 模式
以 Yarn 模式部署 Flink 任务时, 要求 Flink 是有 Hadoop 支持的版本, Hadoop 环境需要保证版本在 2.2 以上, 并且集群中安装有 HDFS 服务。
(1) 启动 hadoop 集群 (略)
(2) 启动 yarn - session
$ ./yarn-session.sh -n 2 -s 2 -jm 1024 -tm 1024 -nm test -d
其中:
- - n( — container) : TaskManager 的数量。
- - s( — slots) : 每个 TaskManager 的 slot 数量, 默认一个 slot 一个 core ,默认每个 taskmanager 的 slot 的个数为 1 ,有时可以多一些 taskmanager,做冗余。
- - jm:JobManager 的内存(单位 MB) 。
- - tm:每个 taskmanager 的内存(单位 MB) 。
- - nm:yarn 的 appName( 现在 yarn 的 ui 上的名字 ) 。
- - d:后台执行。
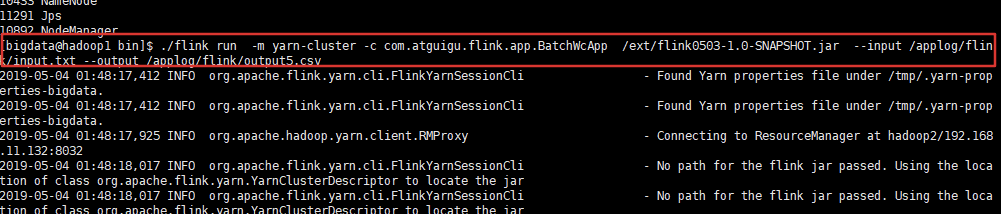
(3) 执行任务
$ ./flink run -m yarn-cluster -c /ext/flink0503-1.0-SNAPSHOT.jar --input /applog/flink/output5.csv com.atguigu.flink.app.BatchWcApp /applog/flink/input.txt --output
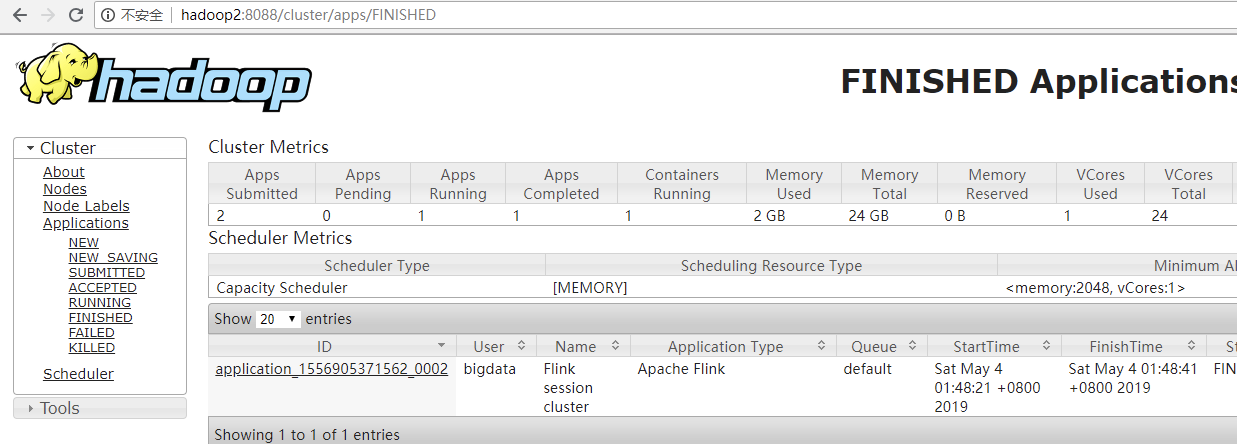
(4) 去 yarn 控制台查看任务状态

若有收获,就点个赞吧
0 人点赞
