不使用ConcurrentHashMap,并发情况下直接使用hashmap的问题
正常情况
第一个线程先插入到数组的某个位置,同时另外一个线程也需要将entry插入到这个位置,发现这个地方本来就有entry存在,那么就进行头或尾插入
异常情况
两个线程同时插入,第一个线程判断这个地方是空的,第二个线程也认为这个地方是空的,那么就有可能会导致entry的覆盖,导致数据的丢失,那么这个问题该怎么解决呢?
解决方法
hashtable(对put方法加锁)
它在put方法加上了锁,锁的对象是this也就是它本身,哪个线程先执行谁就先获得锁,没有获得到锁的方法,需要等上一个获得到锁的方法释放后才能接着执行
欧,这不是我们正想要的吗?
但它缺点就是不管线程需要添加的下标是否相同,这些线程统一都需要等待锁释放,所以性能低下
例如:线程一通过hash算出要放在数组的1,而线程二算出放在2,如果在非线程安全的hashmap或线程安全的hashtable直接插入,数据是不会丢失的,这样没有问题,但是有一个区别就是因为hashtable加了锁,线程二是否执行还是需要等待上一个获得锁的方法释放后才能进行插入,导致锁密度过大
这个问题的解决方法就是在数组的索引上进行加锁,也称为分段锁,也就是你在数组的哪个下标插入数据,我就在哪里加锁
ConCurrentHashmap(jdk1.7)
可能你就想问了,乂,hashmap底层不就是一个entry数组吗?
答:是的,但是在ConCurrentHashMap,它是有两层数组,第一层是Segment对象数组,第二层是Segment对象内部的entry数组
然后你又想问了?为什么是要两个数组,这样不会导致内存消耗吗? 那么我们来看看Segment这个类是做什么的,你就知道了
ConCurrentHashmap有一个内部类:Segment,这个类继承了ReentrantLock,也就是说它拥有了加锁解锁的方法
而ConCurrentHashmap跟hashmap不同的是,hashmap存放数据的数组类型为Entry,而ConcurrentHashMap存放的是Segment[]类型的数组,然后Segment中含有一个entry数组,也就是说ConCurrentHashmap有两层数组
1.Segments[]数组
2.Segment对象内部的entry数组
数组的初始
在hashmap中和ConCurrentHashmap中都有一个构造函数,而且都有同一个同名形参(initialCapacity)
那么它指的是segments[]的容量还是Segment对象内部的entry数组呢?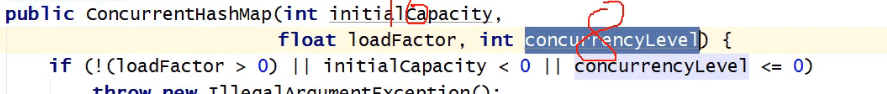
其实这两个形参之间是有一个乘(*)的关系
首先我们知道它有两层数组,一层是segment对象数组,每一个segment对象内部又有一个entry数组 那么这两个参数有跟两个数组有什么关系呢? 假设new ConCurrentHashmap(entry总和16,加载因子0.75,segments数组初始容量8);
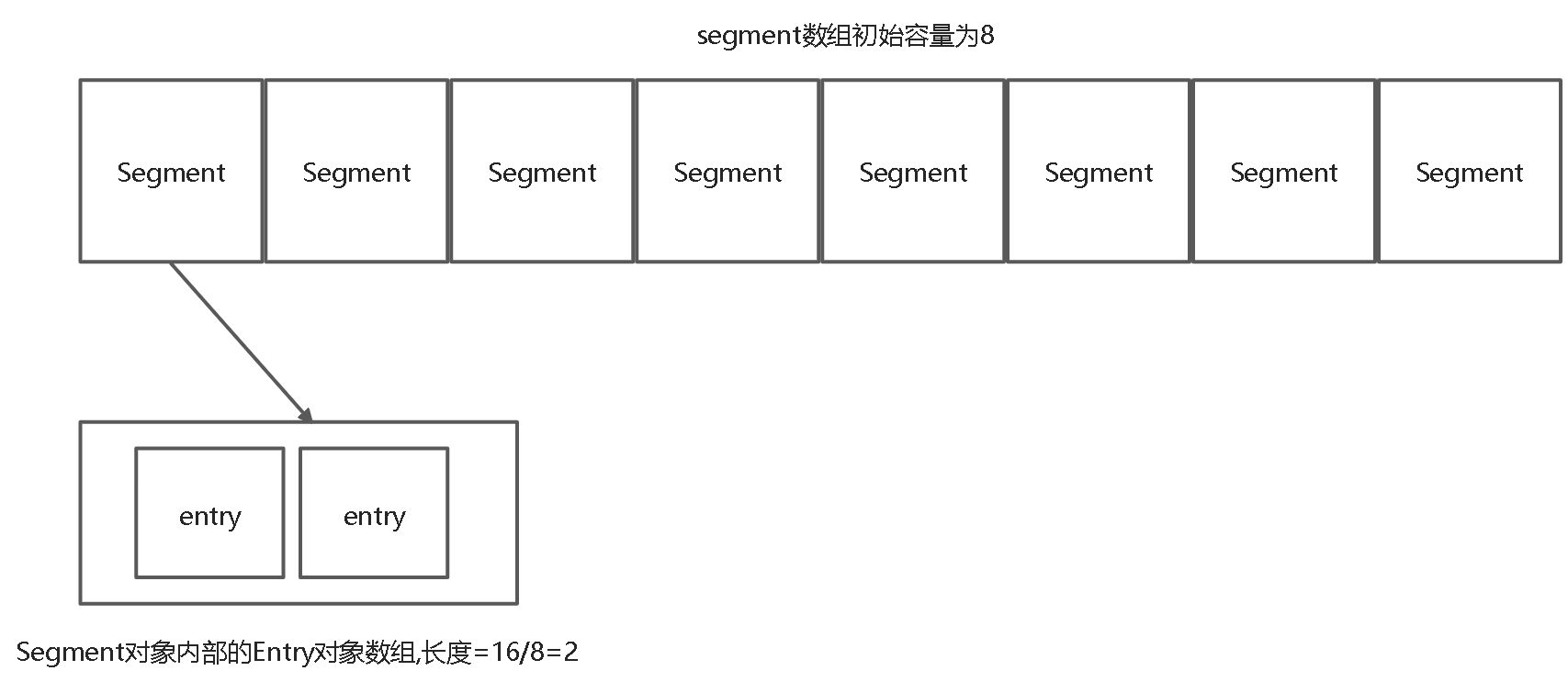
initialCapacity=segment内部entry数组长度concurrencyLevel 反之 *segment内部entry数组长度=initialCapacity/concurrencyLevel
误区
那么如果我initialCapacity/concurrencyLevel=1那么每一个segment内部entry数组长度就是1呢?
答:不是的,因为源码有一个常量
,指定entry最小的长度为2,即使initialCapacity/concurrencyLevel=1,也会判断更改为2 如果new一个无参的构造函数

那么它会将常量作为有参构造函数的参数,来创建concurrenthashmap new ConcurrentHashMap(16,0.75,16); 那么entry总量就为32,Segment长度为16,segment对象内部entry数组长度为2
为什么形参名称叫concurrentLevel?
翻译过来就是并发的级别,也就是多线程环境下同时支持多少个线程执行
那么concurrentLevel传进来多少segment数组就是多少吗?
答:不是,构造器中还进行了一些运算来确定segment数组的初始容量
它的目的就是找一个大于等于concurrentLevel的2^n的数值 假设我们传入一个9,那么就要找到2^n大于等于9的数值 22=2^2=4 <9 (不符合) 222=2^3=8 < 9 (不符合) 2222=2^4=16 >9 (符合) 结果为16
原因 concureenthashmap put()时也是通过&来判断的,就是说没有像&&一样阻断,前提条件是segment[]数组长度必须为2^n(2的n次方) 所以在构造时就根据concurrentLevel算出2^n,到了put()方法时才能用&操作计算出segment的下标
ConCurrentHashMap构造方法在初始化segment数组后,会创建一个Segment放在数组的0上
问题:为什么要在数组[0]上创建一个segment对象呢?
答:因为put的时候,由于是多线程,假设两个线程需要在同一个位置put,而put前会先判断segment是否为null,如果为null,就进入一个ensureSegment(index)方法创建,那么这个创建的不可能是第一个线程创建了segment对象,第二个线程也要创建一个segment对象,而是第一个线程先创建,创建完后返回,第二个线程再进条件表达式进行判断,这时第二个线程就会发现该下标已经有了segment对象,那么直接返回就可以了
你可能会说所以为什么要在初始化的时候就在数组[0]创建一个segment对象呢,跟这有什么关系呢? 其实就是在第一个线程创建的时候创建segment对象时能有一个模板,而数组[0]上的这个对象就是作为这个模板,因为它在初始化的时候,数值已经都被计算好了,为了减少重新计算带来的性能开销,put创建时直接用数组[0]segment的结构信息就行了 那么如何避免两个线程刚好同时来创建segment对象呢? 首先我得知道—>CAS:操作系统中的原子性指令,两个线程被操作系统调度的时候,一定是一个先执行,一个后执行
由图所示: UNSAFE.compareAndSwapObject();方法即CAS ss:segment数组 u:下标位置 null:前提条件 seg=s:创建的segment对象 连起来解释就是指创建的segment对象要放在ss中的下标为u的存储空间里,但是前提是这个存储空间必须为null
那么segment类的构造函数都需要哪些参数呢?
loadFactor:加载因子 cap:容量 HashEntry[]:Entry数组
那么你又想问了为什么这里的cap为啥不直接使用initialCapacity/concurrencyLevel来作为entry数组的容量呢? 原因 我们知道ConCurrentHashMap是双层数组,segment put()方法时,需要&来计算,条件时2^n,那么难道entry数组就不用put了吗?所以这样一想,这个就是原因,entry这个数组创建创建时也将容量计算好,put()执行时也才能通过& 2^n计算出下标,就是需要算两次下标的,一次是segment数组的,一个是entry数组的
加锁与解锁
当我们获得到了segment对象后,那就是调用segment对象的put方法向entry数组中添加entry,所以在这前会获得一个锁,那接下来我们看看它是如何加锁的
tryLock()与lock()区别
tryLock():非阻塞加锁
lock():阻塞加锁
//自旋锁-- 乐观锁while(!tryLock()){//其他操作}
优点:能够在阻塞时做其他的事情 缺点:消耗性能,在没有获得锁前一直循环,
而concurrenthashmap的segment的put方法中就用到了这个方案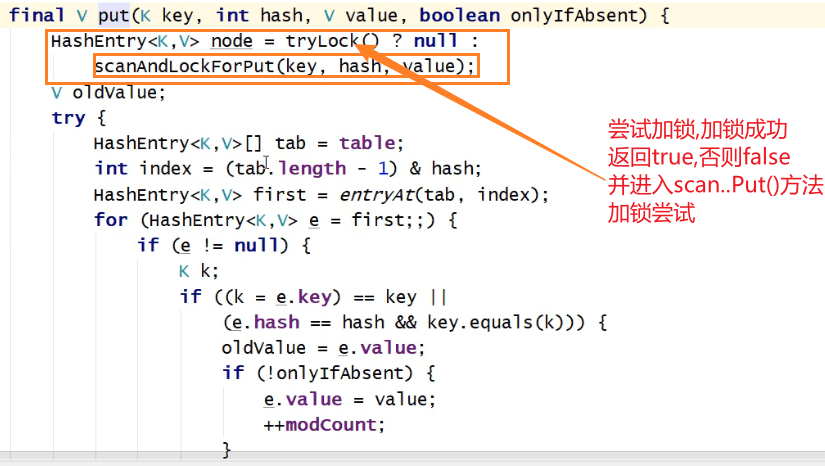


如果核心数大于1,那么重试次数就为64次(多核情况下)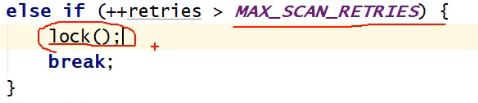
直到获得到锁为止,如果重试64次还没获得到锁,那么就将该线程阻塞并获得到锁
这个判断主要是在64次重试的时候发现链表发生了改变,那么就需要重新遍历链表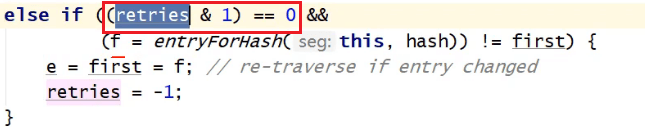
前面这个判断是因为如果每次都去获取链表首个元素判断链表是否发生了改变,重试64次每次都去内存拿就会导致效能极低,在遍历期间,可能别的线程就会抢到锁,导致失去获取锁的机会,所以前面这个判断就是在重试次数为偶数的时候才会判断链表是否发生改变
Put方法
- 先根据key算出对应的Segment数组的下表,index
- 拿到index位置上的锁,segments[index].lock();
- segments[index].put(key,value);qA3WFV2
- 释放index位置上的锁,segment[index].unlock

若有收获,就点个赞吧
0 人点赞
