总结
| 时间复杂度 | 额外空间复杂度 | 稳定性 | |
|---|---|---|---|
| 冒泡排序bubblesort | O(N^2) | O(1) | 稳定 |
| 选择排序Selectionsort | O(N^2) | O(1) | 不稳定 |
| 插入排序Insertionsort | O(N^2) | O(1) | 稳定 |
| 归并排序Mergesort | O(N*logN) | O(N) | 稳定 |
| 随机快速排序Randomquicksort | O(N*logN) | O(N*logN) | 不稳定 |
| 堆排序Heapsort | O(N*logN) | O(1) | 不稳定 |
注:
丨随机快排额外空间复杂度:
空间浪费在了断点上,有了断点才能知道你左边搞完了右边是哪个区域。
最坏的情况:断点每次打到最大或最小的元素上,这样你需要打断点n次 为O(n)
最优的情况:断点每次达到最中间的位置,需要打短点logN次, 为O(logN)
所以它的额外空间复杂度是一个长期期望 O(N*logN)
- 归并排序的额外空间复杂度可以变成O(1),但是非常难变成了一种智力游戏,不需要掌握,可以搜“归并排序 内部缓存法”
- 快速排序可以做到稳定性问题,但是非常难,不需要掌握, 可以搜“01 stable sort”论文级别
前置:
认识时间复杂度
丨常数时间的操作:一个操作如果和数据量没有关系,每次都是固定时间内完成的,叫做常数操作。
时间复杂度为一个算法流程中(最差情况下,常数操作数量的指标。常用O(读作big O)来表示。具体来说,在常数操作数量的表达式中,只要高阶项,不要低阶项,也不要高阶项的系数,剩下的部分如果记为 f (N),那么时间复杂度为O(f(N))。
评价一个算法流程的好坏,先看时间复杂度的指标,然后再分析不同数据样本下的实际运行时间(也就是常数项时间)。
例如:你的算法常数操作时间是
- A:
时间复杂度O(n
- B:
时间复杂度O(n)
不要高阶项系数:因为如果你N(数据量)非常大,几十万甚至上亿,那么它的系数已经无所谓了。 先看时间复杂度的指标:B更好一些,如果AB时间复杂度一样,就再看常数项,100n和2n,则2n更小就更好一些。
对数器
通常我们在笔试的时候或者参加编程大赛的时候,自己实现了一个算法,但是不能够判断该算法是否完全没问题,如果在比赛平台上验证,通常只会告诉你有没有错误,出了错不会告诉你哪里有问题,对于排错来说是非常坑爹的,所以对数器就横空出世了,对数器就是用一个绝对OK的方法和随机器生成的样本数据进行合体,如果你的算法是没问题的,那么和对数器的这个百分之百正确的方法一个元素一个元素的比较,也一定是equals的。如果返回false,说明你的算法有问题。 纳尼??我都能写出一个百分之百正确的对数器了,还用得着跟我自己实现的算法比较么?肯定也是对的啊,话是如此,没错,但是算法的目的是更高效、更优的处理一些问题,你的比较器的时间复杂度和空间复杂度往往是比较低的,因为这样才能保证它的准确性,而你笔试或者比赛写出的算法,复杂度往往比较高,所以可以通过低复杂度但是绝对正确的方法验证你的算法正确不正确。
1.有一个你想要测的方法a;
2.实现一个绝对正确但是复杂度不好的方法b;
3.实现一个随机样本产生器;
4.实现对比算法a和b的方法;
5.把方法a和方法b比对多次来验证方法a是否正确;
6.如果有一个样本使得比对出错,打印样本分析是哪个方法出错;
7.当样本数量很多时比对测试依然正确,可以确定方法a已经正确。
递归函数:
自己调自己 这是逻辑上
压栈(系统栈) 物理上
一个过程调用子过程(自身)时,会把所有信息压栈(保护现场)信息完全报错,之后子过程跑完后,会利用这些信息彻底还原当时场景,继续跑。
剖析递归行为和递归行为时间复杂度的估算
一个递归行为的例子
master公式的使用
T(N) = 
- log(b,a) > d -> 复杂度为O(N^log(b,a))
- log(b,a) = d -> 复杂度为O(N^d * logN)
- log(b,a) < d ->
数组表示二叉树
设某个节点索引值为index,则节点的
左子节点索引为 : 2index+1
右子节点索引为 : 2index+2
父节点索引为 : (index-1)/2
/* [1,2,3,4,5,6,7,8,9,10]
下标 第n个节点
1 0 1
/ \
2 3 1 2 1层 2 3
/ \ /\
4 5 6 7 3 4 5 6 2层 4 5 6 7
/ \ /
8 9 10 7 8 9 3层 8 9 10
某个数组中某个index i,对应的父节点下标是:(i+1)/2 - 1
如(3+1)/2-1 = 1 (4+1)/2-1 = 1
(8+1)/2-1 = 3 (9+1)/2-1 = 4
*/
稳定性
排序算法的稳定性,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。(在值相等的情况下,排序保持原来的顺序)
比如:
数组:arr 1 1 3 4 5 6 3 4 1
下标:index 0 1 2 3 4 5 6 7 8
有三个相同的 1 在排序后三个1的位置是: arr[0] arr[1] arr [8] , arr[0]在最前面arr[1]在中间arr[8]在最后
稳定性的意义:希望之前数据的信息能够保留下来。
举例1:现在对多个班级学生成绩排序,我们第一次点了按发生从高到低排序,之后又点击了按班级排序,那么相同班级的人的学生在一块,这个班级内部同学的成绩也是保留了之前从高到低的次序。
举例2:我们在页面有列表,第一次我们点了按身高从高到矮排序,之后又点了按年龄从小到大排序,这时候如果又俩个或多个年龄相同的人,如果排序稳定,那么这几个人年龄相同,身高的排序还保留之前从高到矮的顺序。
稳定性只对于非基础类型,对于基础类型个体间无差异,相同元素没有前后之分,比如1和1谁在前谁在后没差别
排序算法思路:
选择排序
(1)首先从原始数组中选择最小的1个数据,将其和位于第1个位置的数据交换。
(2)接着从剩下的n-1个数据中选择次小的1个元素,将其和第2个位置的数据交换
(3)然后,这样不断重复,直到最后两个数据完成交换。最后,便完成了对原始数组的从小到大的排序。
插入排序
插入排序从第二个数开始,拿出第二个数进行向前插入排序,一直到最后一个数向前做插入排序。算法稳定。
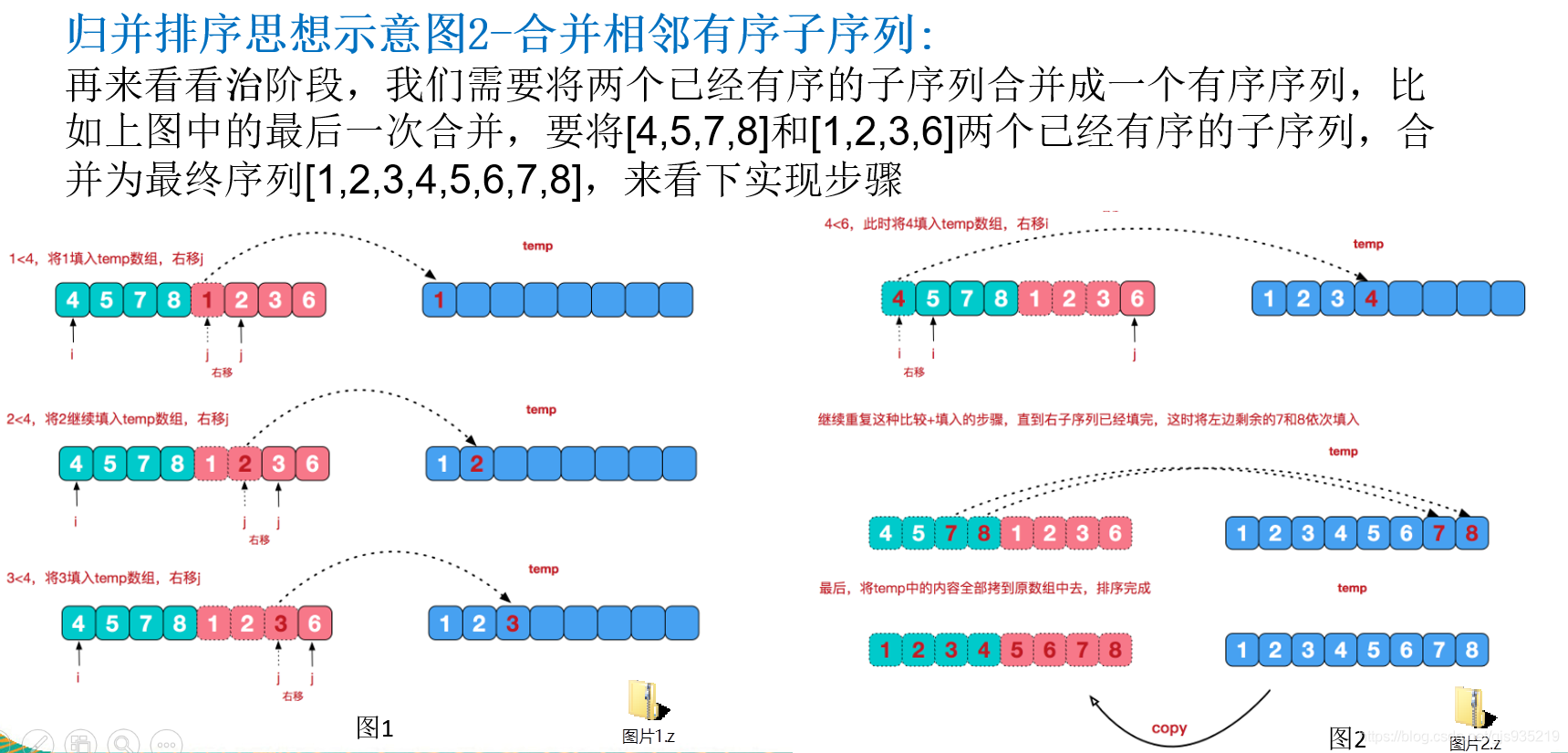
归并排序

快速排序
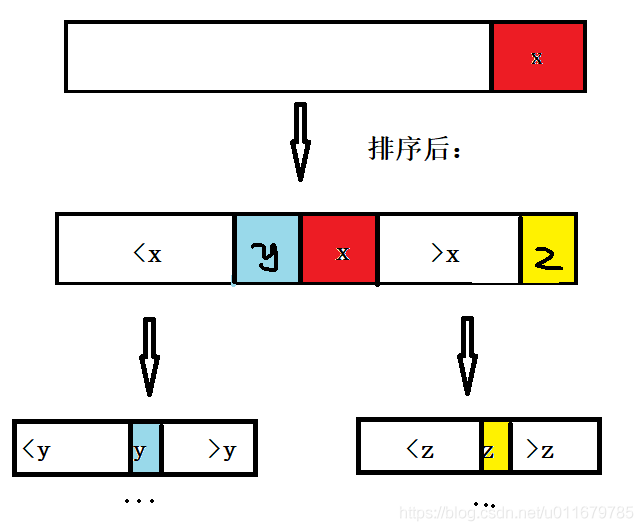
快速排序(Quicksort)是对冒泡排序的一种改进。 快速排序由C. A. R. Hoare在1960年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
- 经典快排:利用最后一个数作为分界点,小的放左边,大的放右边,可以使用荷兰国旗问题的方法优化
- 随机快排:产生一个随机位置作为分界点


/*** 快排* @param arr 排序数组* @param head 数组排序部分头部下标* @param tail 数组排序部分尾部下标*/public static void quickSort(int arr[], int head, int tail) {if (head >= tail) {return;}int key = head; //比较标志位指针int l = head; //左边小于标志位部分指针int r = tail; //右边大于标志位指针while (l < r) {while (arr[r] >= arr[key] && l < r) {r--;}while (arr[l] <= arr[key] && l < r) {l++;}if(l<r){int temp = arr[l];arr[l] = arr[r];arr[r] = temp;}}int temp = arr[key];arr[key] = arr[l];arr[l] = temp;quickSort(arr,head,l-1);quickSort(arr,r+1,tail);}
堆排序
堆排序是一种选择排序,通过实现大小堆,来取出堆顶的数据,然后和最后一个交换,然后将堆的大小减一,循环这个过程直到,只有一个数据时停止。
升序建大堆,降序建小堆。
堆排序的基本思想是:
1).将无序序列构建成一个堆,根据升序降序需求选择大顶堆或小顶堆;
2).将堆顶元素与末尾元素交换,将最大元素”沉”到数组末端;
3).重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序
综合排序算法选取
1、若你需要排序的是基本数据类型,则选择快速排序。若你需要排序的是引用数据类型,则选择归并排序。(基于稳定性考虑)
因为基本数据类型之间无差异,不需要考虑排序算法稳定性,而归并排序则可以实现算法的稳定性。
2、当你需要排序的样本数量小于60,直接选择插入排序,虽然插入排序的时间复杂度为O(N²),我们是忽略常数项得出来的O(N²),但在魔数60以内,插入排序的时间复杂度为O(N²)的劣势体现不出来,反而插入排序常数项很低,导致在小样本情况下,插入排序极快。如果一开始数组容量很大,但可以分治处理,分治后如果数组容量(L>R - 60)小于60,可以直接选择插排。当大样本下考虑情况1。
桶排序、记数排序、基数排序
1、非基于比较的排序,与被排序的样本的实际数据状况很有关系,所以实际中并不经常使用
2、时间复杂度O(N),额外空间复杂度O(N)
3、稳定的排序

若有收获,就点个赞吧
0 人点赞
