主要步骤:
- 观察数据整体布局
- 获取数据
- 将数据可视化
- 为了机器学习的算法进行准备数据
- 选择模型并训练模型
- 微调模型
- 展示结论
- 发布、监督、维护系统
一. 数据整体
- 任务
构建模型,预测加州每个街区的房价。数据:加州的每个街区有人口、中位数收入、中位数房价等。
- Pipeline
数据处理的所有构件组成的序列。这些构件往往是同步运行。
- 描述问题
有监督还是无监督还是强化学习;分类还是回归;批量学训练还是网上训练?
- 选择评价标准
(1)RMSE-root mean square root
- 回归模型的评价标准通常是“均方根误差”(RMSE),度量了系统在预测时产生的误差的标准差。
- 公式

- m是特征数量,n是样本数量,
 是第i个样本,包含了所有的特征,是m维列向量;
是第i个样本,包含了所有的特征,是m维列向量; 是对应的真实值label;矩阵
是对应的真实值label;矩阵 是包含了所有特征的矩阵,每一行是一个样本,每一列是一个特征所有的样本;h是预测函数,也称为hypothesis,
是包含了所有特征的矩阵,每一行是一个样本,每一列是一个特征所有的样本;h是预测函数,也称为hypothesis, 。
。 - 当特征服从正态分布的时候,那么“68-95-99.7”原则:68%的样本将会落在均值的1个标准差1σ中,95%的样本将会落在均值的2个标准差2σ中,99.7%的样本将会落在3个标准差3σ中。
- 如何解释:如果RMSE=50000,意味着系统预测的68%结果将会落在真实值左右50000的范围中,95%的结果落在真实值左右10万的范围中,99.7%的结果将会落在真实值左右15万的范围中。
(2)MAE-mean absolute error
- 平方根误差(MAE)
- 公式

- MAE和RMSE都是度量了两个向量之间的距离。RMSE对应的是欧几里得距离,也称为
 距离;MAE对应的是
距离;MAE对应的是 距离,也称为曼哈顿距离。
距离,也称为曼哈顿距离。
(3) 距离
距离

- k越高,那么度量标准越集中在大数值上面、忽略小数值。因此RMSE对外部异常值更加敏感。
二. 获取数据
1. 数据描述

数据连接:https://www.kaggle.com/camnugent/california-housing-prices,可以把CSV下载到本地。
import pandas as pdimport numpy as npimport matplotlib.pyplot as plt# 读取数据housing = pd.read_csv(r'D:\下载\sklearndata\housing.csv')# 显示头5行housing.head()# 显示infohousing.info()# ocean_proximity的类型是object,是text的类型,看看有什么类别,因此需要分类。housing['ocean_proximity'].value_counts()# 通过describe()看看数值的总结housing.describe()# 通过直方图查看分布housing.hist(bins=50, figsize=(20,15))plt.show()
housing.head()的结果
housing.info的结果
<class 'pandas.core.frame.DataFrame'>RangeIndex: 20640 entries, 0 to 20639Data columns (total 10 columns):# Column Non-Null Count Dtype--- ------ -------------- -----0 longitude 20640 non-null float641 latitude 20640 non-null float642 housing_median_age 20640 non-null float643 total_rooms 20640 non-null float644 total_bedrooms 20433 non-null float645 population 20640 non-null float646 households 20640 non-null float647 median_income 20640 non-null float648 median_house_value 20640 non-null float649 ocean_proximity 20640 non-null objectdtypes: float64(9), object(1)memory usage: 1.6+ MB
housing[‘ocean_proximity’].value_counts()的结果
<1H OCEAN 9136INLAND 6551NEAR OCEAN 2658NEAR BAY 2290ISLAND 5Name: ocean_proximity, dtype: int64
housing.describe()的结果:看到total_bedrooms存在缺失值;看到housing_median_age的25%的值低于18年,50%的值低于29年,75%的值低于37年。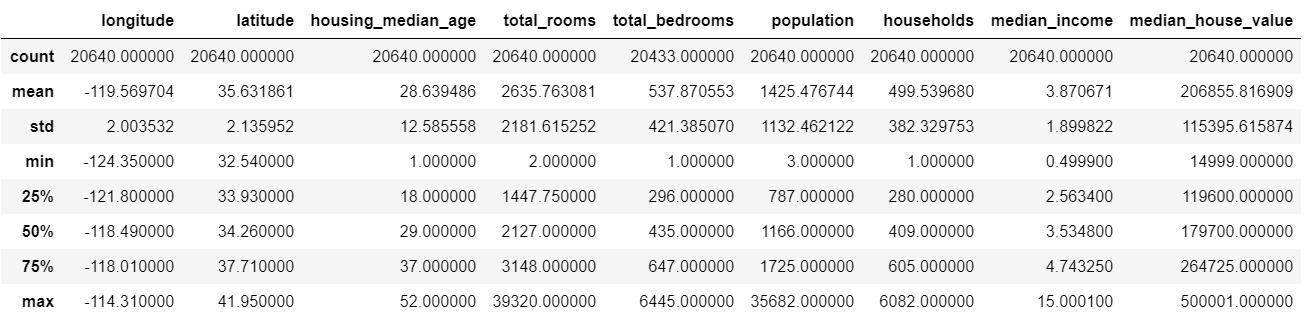
频率直方图:①median incomde的单位并不是USD,事实上已经被预处理过,上限为15;②median age和median value也被预处理,上限已经被确定为50和50万,因此在预测value时,预测值不应该超过50;③这些特征的刻度大小各不相同,需要进行缩放;④很多直方图存在厚尾现象:右边过于延展。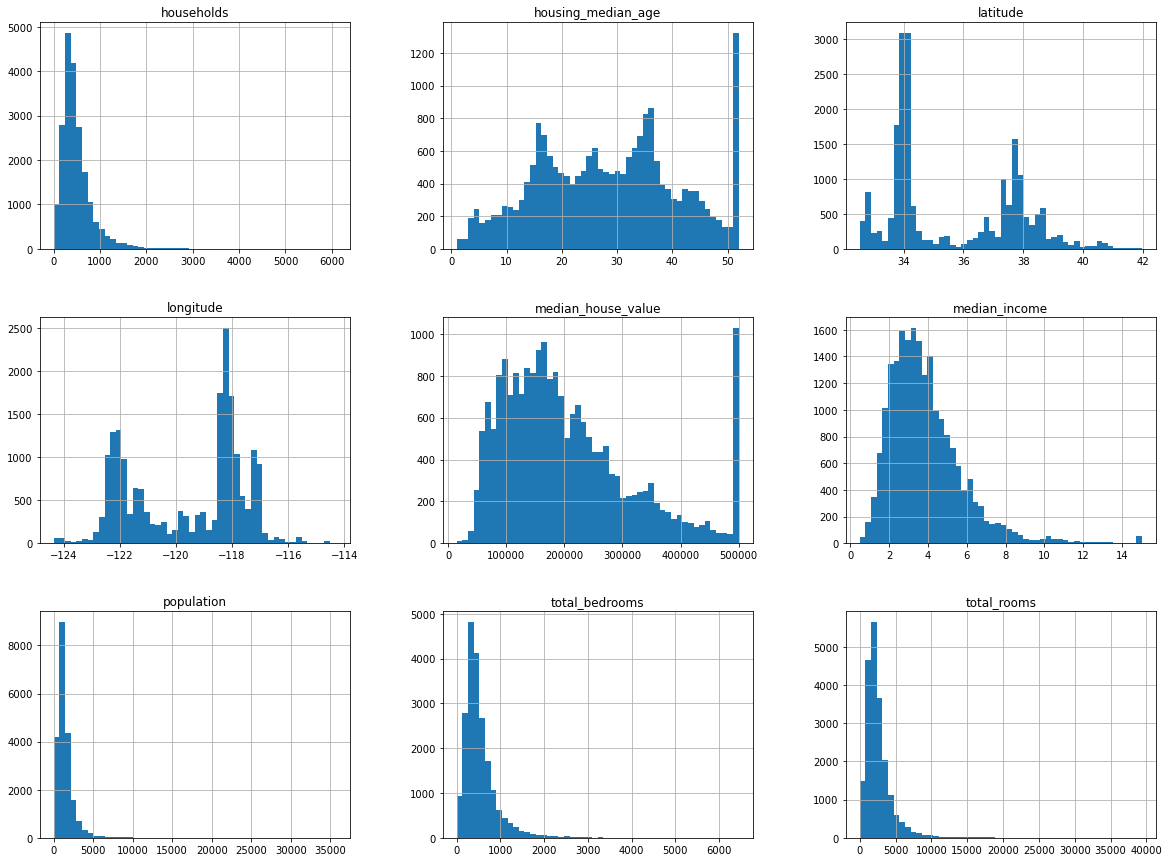
2. 创造测试集
问题①:防止每次拆分都拆除不一样的数据,需要固定随机种子(train_test_split);
问题②:需要保证拆开的子样本的分布能够代表整体分布(StratifiedShuffleSplit)。
例如,median_income的分布大部分集中在2~5万,少部分在6万以上,因此测试集也需要有这样的分布;否则数据结构会出现偏差。做法:产生新的变量“income_cat”(收入类型),将median_income除以1.5,限制收入类型的总数,将结果向上取整(np.ceil),然后将大于5的数值都取为5。
from sklearn.model_selection import train_test_split, StratifiedShuffleSplit# 这里是将median_income进行了缩放(除以1.5),然后将工资进行切分(向上取整)成5份,超过5的全部归类到5中。housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)# 通过随机抽样的结果:80%是训练数据,20%是测试数据,同时通过ransom_state=42(宇宙终极答案),那么能够保证每次拆分的样本一样。train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)# 再拆一次_, test_set2 = train_test_split(housing, test_size=0.2, random_state=42)# 判断:一致test_set == test_set2# 通过分层拆分样本的结果split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)for train_index, test_index in split.split(housing, housing["income_cat"]):strat_train_set = housing.loc[train_index]strat_test_set = housing.loc[test_index]# 统计整体中income_cat的分类total = pd.DataFrame(housing['income_cat'].value_counts() / len(housing)).sort_index()# 统计普通拆分的测试集中income_cat的分类normal = pd.DataFrame(test_set['income_cat'].value_counts() / len(test_set)).sort_index())# 统计分层拆分的测试集中income_cat的分类strat = pd.DataFrame(strat_test_set['income_cat'].value_counts() / len(strat_test_set)).sort_index()cat = pd.concat([total, normal, strat], axis=1)cat.columns = ['Overall', 'Random', 'Stratified']# 最后将income_cat剔除strat_train_set = strat_train_set.drop('income_cat', axis=1)strat_test_set = strat_test_set.drop('income_cat', axis=1)housing = housing.drop('income_cat', axis=1)

可以看到,随机抽样的结果并不是很贴近总体的分布,而分层抽样很贴近总体分布。因此,接下来我们使用的应该是strat_train_set和strat_test_set的数据进行训练和测试。
三. 数据可视化
1. 对训练集进行可视化
# 对训练样本进行可视化housing = strat_train_set.copy()# 画出经纬度的散点图,alpha能够显示出哪一块区域的密度更大——Bay area更加密plt.rcParams.update({'figure.figsize':(5,5), 'figure.dpi':128, 'font.size':10, 'axes.unicode_minus':False, 'font.sans-serif': ['Times New Roman']})housing.plot(kind='scatter', x='longitude', y='latitude', alpha=0.1)plt.show()# 房价图:每个圆圈的半径表示街区的人口(s),颜色表示价格(c),需要颜色图(cmap)从蓝色(低价)到红色(高价)housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,s=housing["population"]/100, label="population",c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,)plt.legend()plt.show()


房价彩色图告诉我们:房子越靠近海洋或者人口密度越高,那么房价越高。
2. 寻找相关性
- 因为数据集不大,因此能够计算Pearson相关系数。
考察和房价相关性最强的变量。
corr_mtx = housing.corr()corr_mtx['median_house_value'].sort_values(ascending=False)
结果:可以看到,收入和房价正相关,纬度和房价负相关。
median_house_value 1.000000median_income 0.688075total_rooms 0.134153housing_median_age 0.105623households 0.065843total_bedrooms 0.049686population -0.024650longitude -0.045967latitude -0.144160
因为和房价最相关的变量是“median income”,因此这里可以画出他们的相关性散点图。
- 正相关性确实很强;
- 房价上限设为50万,因此y轴截取到了50万;但是在35万也出现了模糊的横线;因此这种横线需要剔除。
housing.plot(kind='scatter', x='median_income', y='median_house_value',alpha=0.1)plt.show()

3. 将特征进行组合
- 某些特征看似对价格没有影响,例如房间数量;但是如果把房间数量除以一家人口数,得到每户人家的平均房间数量,也许会有用。
```python
每户人家平均房价数量
housing[‘rooms_per_household’] = housing[‘total_rooms’]/housing[‘households’]总卧室数量/总房间数量
housing[‘bedrooms_per_room’] = housing[‘total_bedrooms’]/housing[‘total_rooms’]每户人家的平均人口数
housing[‘population_per_household’]=housing[‘population’]/housing[‘households’]
corr_matrix = housing.corr() corr_matrix[‘median_house_value’].sort_values(ascending=False)
结果:bedrooms_per_room、rooms_per_household成为了新的相关变量。
median_house_value 1.000000 median_income 0.688075 rooms_per_household 0.151948 total_rooms 0.134153 housing_median_age 0.105623 households 0.065843 total_bedrooms 0.049686 population_per_household -0.023737 population -0.024650 longitude -0.045967 latitude -0.144160 bedrooms_per_room -0.255880
<a name="ANZRL"></a>## 四. 为了机器学习的算法进行准备数据<a name="e1xfQ"></a>### 1. 通过函数清洗数据- 方便日后重复利用。- 对strat_train_set处理,将Y变量(median_house_value)抽出来,剩下的作为x label。```pythonhousing = strat_train_set.drop(['median_house_value'], axis=1)housing_labels = strat_train_set['median_house_value'].copy()
2. Data Cleaning
- 缺失值处理
- 剔除相关记录;housing.dropna(subset=[‘total_bedrooms’])
- 剔除整个特征;housing.drop([‘total_bedrooms’], axis=1)
- 填充;housing[‘total_bedrooms’].fillna(housing[‘total_bedrooms’].median())
- SimpleImputer:sklearn中的填充函数。
- 设定填充值是中位数;
- 同时只有数值型才能够填充中位数,因此把ocean_proximity这种字符型剔除,剩下的特征是数值型特征。 ```python from sklearn.impute import SimpleImputer
指定填充方法是median
imputer = SimpleImputer(strategy=’median’)
保留数值型特征
housing_num = housing.drop(‘ocean_proximity’, axis=1)
拟合之后转换
imputer.fit(housing_num)
print(imputer.statistics_)
X = imputer.transform(housing_num) housing_tr = pd.DataFrame(X, columns=housing_num.columns)
<a name="diV1U"></a>### 3. 处理文本数据<a name="3HJdL"></a>#### 3.1 将文本转化为数字——LabelEncoder```pythonfrom sklearn.preprocessing import LabelEncoderencoder = LabelEncoder()housing_cat = housing['ocean_proximity']housing_cat_encoded = encoder.fit_transform(housing_cat)print(encoder.classes_)
<1H OCEAN=0,INLAND=1,ISLAND=2,NEAR BAY=3,NEAR OCEAN=4。
- 问题是,算法会认为靠近的数字具有更多相似性;但实际上,<1H OCEAN和NEAR OCEAN的相似性更高,尽管他们的数字距离最远。
3.2 将数字转化为OneHot——OneHotEncoder
- 在LabelEncoder的基础上,再使用OneHotEncoder,从而避免数值型尴尬。 ```python from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder() housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
housing_cat_1hot.toarray()
housing_cat_1hot该结果是一个SciPy sparse matrix;只有对应的列是1,其他是0。
array([[1., 0., 0., 0., 0.], [1., 0., 0., 0., 0.], [0., 0., 0., 0., 1.], …, [0., 1., 0., 0., 0.], [1., 0., 0., 0., 0.], [0., 0., 0., 1., 0.]])
<a name="D1T5p"></a>#### 3.3 将文本直接转化为OneHot——LabelBinarizer```pythonfrom sklearn.preprocessing import LabelBinarizerencoder = LabelBinarizer()housing_cat_1hot = encoder.fit_transform(housing_cat)housing_cat_1hot
结果即为3.2的结果。
PS:如果需要得到SciPy sparse matrix
encoder = LabelBinarizer(sparse_output=True)# 得到的结果即为SciPy sparse matrix,需要将其转化为toarray。housing_cat_1hot = encoder.fit_transform(housing_cat)housing_cat_1hot.toarray()
4. 定制转换器
- 定义一个类,增加三种方法:fit()——return self,transform(),和fit_transform()。
- TransformerMixin是能够使用fit_transform的类,BaseEstimator是能够使用get_params和set_params的类。 ```python from sklearn.base import BaseEstimator, TransformerMixin
room_ix, bedroom_ix, population_ix, household_ix = 3,4,5,6
class CombinedAttributesAdder(BaseEstimator, TransformerMixin): def init(self, addbedrooms_per_room = True): self.add_bedrooms_per_room = add_bedrooms_per_room def fit(self, X, y=None): return self def transform(self, X, y=None): rooms_per_household = X[:, room_ix] / X[:, household_ix] population_per_household = X[:, population_ix] / X[:, household_ix] if self.add_bedrooms_per_room: bedrooms_per_room = X[:, bedroom_ix] / X[:, room_ix] return np.c[X, roomsper_household, population_per_household, bedrooms_per_room] else: return np.c[X, rooms_per_household, population_per_household]
attr_adder = CombinedAttributesAdder(add_bedrooms_per_room=False) housing_extra_attribs = attr_adder.transform(housing.values)
在本例中,只有一个参数,add_bedrooms_per_room。- 例如,可以定制其他的选择变量的函数```pythonclass DataFrameSelector(BaseEstimator, TransformerMixin):def __init__(self, attribute_names):self.attribute_names = attribute_namesdef fit(self, X, y=None):return selfdef transform(self, X):return X[self.attribute_names].values
- 因此可以看到,自己定义transformer,存在固定的模板
class TransName(BaseEstimator, TransformerMixin):def __init__(self, var):self.var=vardef fit(self, X, y=None):return selfdef transform(self, X):对X的var做一些处理,return X[var]...
4. 特征缩放
- 如果特征存在不同的刻度,那么算法表现不会好。
- 两种方法:min-max(normalization)缩放到0-1范围内、容易受到极端值的影响,standardization缩放到正态分布。
5. Transformation Pipelines
- 数据处理存在很多步,我们需要按照流程执行,这里使用Pipeline能将转换流程排成序列。
- Pipeline构造器 ```python from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([ (‘imputer’, SimpleImputer(strategy=’median’)), (‘std_scaler’, StandardScaler()), ])
housing_num_tr = num_pipeline.fit_transform(housing_num)
- 这里可以一步到位解决数值型预处理和字符型预处理~- 通过FeatureUnion将数值型预处理和字符型预处理串起来。```pythonfrom sklearn.pipeline import FeatureUnion# 首先,我们需要修改LabelBinarizer函数。# 原始的LabelBinarizer.fit_transform()只有一个参数位fit_transform(self, x)# 这里我们添加了新的参数位,变成fit_transform(self, x, y)class LabelBinarizerNew(TransformerMixin):def __init__(self, *args, **kwargs):self.encoder = LabelBinarizer(*args, **kwargs)def fit(self, X, y=None):self.encoder.fit(X)return selfdef transform(self, X):return self.encoder.transform(X)# num_attribs一共有8个变量,cat_attribs是一个变量。num_attribs = list(housing_num)cat_attribs = ['ocean_proximity']num_pipeline = Pipeline([('selector', DataFrameSelector(num_attribs)),('imputer', SimpleImputer(strategy='median')),('attribs_adder', CombinedAttributesAdder()),('std_scaler', StandardScaler()),])cat_pipeline = Pipeline([('selector', DataFrameSelector(cat_attribs)),('label_binarizer', LabelBinarizerNew()),])full_pipeline = FeatureUnion(transformer_list=[('num_pipeline', num_pipeline),('cat_pipeline', cat_pipeline),])housing_prepare = full_pipeline.fit_transform(housing)# 原始的8个数值型,通过CombinedAttributesAdder增加了3个变量,文本型5个One-hot变量。一共16个变量housing_prepare.shape
五. 选择并训练模型
1. 训练并评估测试集
1.1 线性回归模型
# 模型构建from sklearn.linear_model import LinearRegressionlin_reg = LinearRegression()lin_reg.fit(housing_prepare, housing_labels)# 尝试预测前5个数some_data = housing.iloc[:5]some_labels = housing_labels.iloc[:5]some_data_prepared = full_pipeline.transform(some_data)predictions = lin_reg.predict(some_data_prepared)predictions = [np.round(x, 1) for x in predictions]print('Predictions : \t', predictions)print('Labels : \t', list(some_labels))# 评价全部预测值的RMSEfrom sklearn.metrics import mean_squared_errorpredictions = lin_reg.predict(housing_prepare)lin_mse = mean_squared_error(housing_labels, predictions)lin_rmse = np.sqrt(lin_mse)print(lin_rmse)
RMSE=68628.19819848923。比较不太好。
1.2 决策树模型
# 构建树模型from sklearn.tree import DecisionTreeRegressortree_reg = DecisionTreeRegressor()tree_reg.fit(housing_prepare, housing_labels)# 预测predictions = tree_reg.predict(housing_prepare)# 评估tree_mse = mean_squared_error(housing_labels, predictions)tree_rmse = np.sqrt(tree_mse)print(tree_rmse)
结果为0。是因为过拟合了。
2. Cross-Validation 进行评估
- 将训练集拆分为更小的训练集合以及验证集合,然后通过更小的训练集进行训练、并且根据更小的验证集合进行评估。
- sklearn中的cross-validation能够进行k-折交叉验证:随机将训练集拆分为k份不重叠(每个子样本称为折fold),然后训练并且评估决策树模型k次,每次选择一个不同的评估集、训练其他9个集合。结果是包含了10次评估分数的array。
- sklearn中的CV使用的是效用函数,因此值越大越好,因此这里取负数之后、越小越好。
2.1 决策树交叉检验
```python from sklearn.model_selection import cross_val_score
10折交叉检验
scores = cross_val_score(tree_reg, housing_prepare, housing_labels, scoring=’neg_mean_squared_error’, cv=10) rmse_scores = np.sqrt(-scores)
显示结果
def display_scores(scores): print(‘Scores : ‘, scores) print(‘Mean : ‘, scores.mean()) print(‘Standard deviation : ‘, scores.std())
因此树模型并没有看起来的那么好,存在过拟合。
Scores : [70069.41781111 66820.09476806 70114.19356466 68381.24594867 69839.86330545 74818.36453138 70852.62050555 70487.09211607 76354.41657818 69144.40626798] Mean : 70688.17153971366 Standard deviation : 2707.9765867217143
<a name="RsB9k"></a>#### 2.2 线性回归模型交叉检验```pythonlin_scores = cross_val_score(lin_reg, housing_prepare, housing_labels,scoring='neg_mean_squared_error', cv=10)rmse_scores = np.sqrt(-lin_scores)display_scores(rmse_scores)
因此,树模型过拟合很严重,相比之下,线性回归模型更好。
Scores : [66782.73843989 66960.118071 70347.95244419 74739.5705255268031.13388938 71193.84183426 64969.63056405 68281.6113799771552.91566558 67665.10082067]Mean : 69052.46136345083Standard deviation : 2731.674001798349
2.3 随机森林交叉检验
from sklearn.ensemble import RandomForestRegressorforest_reg = RandomForestRegressor()forest_scores = cross_val_score(forest_reg, housing_prepare, housing_labels,scoring='neg_mean_squared_error', cv=10)rmse_scores = np.sqrt(-forest_scores)display_scores(rmse_scores)
结果好很多。
Scores : [49549.2252193 47566.40185805 50171.93159465 52181.9631975949531.06714469 53439.61825431 48458.99823718 47775.3111799852740.77624839 50630.7771539 ]Mean : 50204.607008803694Standard deviation : 1943.759609789292
六. 微调模型
1. 引言
2. 网格点搜索
from sklearn.model_selection import GridSearchCVparam_grid = [{'n_estimators':[3, 10, 30], 'max_features':[2,4,6,8]},{'bootstrap':[False], 'n_estimators':[3,10], 'max_features':[2,3,4]}]forest_reg = RandomForestRegressor()grid_search = GridSearchCV(forest_reg, param_grid, cv=5,scoring='neg_mean_squared_error')grid_search.fit(housing_prepare, housing_labels)print(grid_search.best_params_)
结果为{‘max_features’: 8, ‘n_estimators’: 30}
3. 分析最好的模型以及它们的误差
feature_importances = grid_search.best_estimator_.feature_importances_# 将额外的特征标注extra_attribs = ['room_per_hold', 'population_per_hold', 'bedroom_per_room']# 如果直接使用了pipeline一步到位处理了数据,这里需要把encoder重新标注出来。# 将One-Hot特征标注housing_cat = housing['ocean_proximity']encoder = LabelBinarizer(sparse_output=True)_ = encoder.fit_transform(housing_cat)cat_one_hot_attribs = list(encoder.classes_)# 将所有特征合并attributes = num_attribs + extra_attribs + cat_one_hot_attribssorted(zip(feature_importances, attributes), reverse=True)
各个变量结果如下:可以把不重要的变量剔除。
[(0.38712710809680523, 'median_income'),(0.15137133061774638, 'INLAND'),(0.11233858010948929, 'population_per_hold'),(0.07151224505535729, 'longitude'),(0.06308479129272432, 'latitude'),(0.0622346641170907, 'bedroom_per_room'),(0.04408271861224502, 'housing_median_age'),(0.03946371216590984, 'room_per_hold'),(0.015257218730126785, 'population'),(0.015124789281932172, 'total_rooms'),(0.014151941557599046, 'total_bedrooms'),(0.01412672539194633, 'households'),(0.005456875311235287, '<1H OCEAN'),(0.0029802250441129303, 'NEAR OCEAN'),(0.0016442477143533106, 'NEAR BAY'),(4.2826901326012144e-05, 'ISLAND')]
4. 在测试集评估模型
# 最后的模型final_model = grid_search.best_estimator_# 拆分X和yX_test = strat_test_set.drop('median_house_value', axis=1)y_test = strat_test_set['median_house_value'].copy()# X进行预处理X_test_prepare = full_pipeline.transform(X_test)final_predict = final_model.predict(X_test_prepare)# 评估模型final_mse = mean_squared_error(y_test, final_predict)final_rmse = np.sqrt(final_mse)print(final_rmse)
结果为47597.046404291556。
以上~

若有收获,就点个赞吧
0 人点赞
