本章使用了MNIST数据集,含有7万张手写体数字图片,每张图片都标记了相应的数字。因此,分类算法都需在手写体数字图片进行试验。
数据来源
from sklearn.datasets import fetch_openmlimport numpy as npimport matplotlibimport matplotlib.pyplot as pltmnist = fetch_openml('mnist_784')# mnist中存在手写体数据。X, y = mnist['data'], mnist['target']print(X.shape, y.shape)
通过Scikit-Learn调取的数据通常具备相似的结构字典:mnist.DESCR是数据描述,mnist.data是arrray形状的数据、每一行是一个实例、每一列是一个feature,mnist.feaure是label。
可以看到,X的形状是(70000,784),y是的形状(70000,)。784=28*28,因此每一个feature即为一个像素密度(pixel intensity),从0(白色)到255(黑色)。通过将数据reshape为(28,28)array,查看形状。
some_digit = X[0]some_digit_image = some_digit.reshape(28, 28)plt.imshow(some_digit_image, cmap = matplotlib.cm.binary, interpolation='nearest')plt.axis('off')plt.show()# 对应的labelprint(y[0])
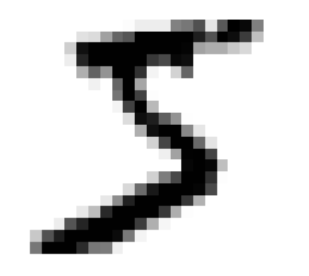
看起来是5,label也是5。
划分数据集
在仔细检测数据之前,需要创造出测试集(test)和训练集(training),并且把测试集放在一边。同时,对数据进行shuffle;增加随机性,提高网络的泛化性能,避免因为有规律的数据出现,导致权重更新时的梯度过于极端,避免最终模型过拟合或欠拟合。
# 将y从string转为int型y = y.astype(np.uint8)X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]shuffle_index = np.random.permutation(60000)X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]
训练二元分类器(Binary Classifier)
例子,现在就训练标签为9的数据,因此“5-识别器”是一个二元分类器,用于识别label=5或者≠5。
教材中一个选择了“随机梯度下降”(Stochastic Gradient Descent,SGD)分类器,该分类器能够有效地处理庞大的数据集,这是因为SGD能够在每一次独立(independently one at a time)处理训练样本,因此SGD非常适合网上训练(online learning)。
由于SGD分类器依赖于训练期间的随机性,如果想要复制结果,通过参数random_state控制。
y_train_5 = (y_train == 5) * 1y_test_5 = (y_test == 5) * 1from sklearn.linear_model import SGDClassifier# 训练sgd_clf = SGDClassifier(random_state=42)sgd_clf.fit(X_train, y_train_5)# 预测
使用Cross-validation度量准确性
K折交叉检验:将训练集拆分为K等分,每次使用K-1个部分进行训练,再把剩下的部分进行evaluation。这里使用了cross_val_score中的accuracy作为评判标准。
from sklearn.model_selection import cross_val_scorecross_val_score(sgd_clf, X_train, y_train_5, cv=10, scoring='accuracy')
结果array([0.961, 0.963, 0.964, 0.965, 0.968, 0.964, 0.959, 0.940, 0.967, 0.958])。
在每一折训练得到的结果准确率Accuracy均超过了90%?事实上,是因为标签为5的样本占据了10%,而“非5”的标签占据了90%,因此哪怕全部估计结果为0,都能够达到90%的正确率。因此,accuracy并不能够很好地评估二分器,特别是在某一类别比例过高的情况下。
混淆矩阵 Confusion Matrix(CM)
- 定义:混淆矩阵主要用来判断分类器模型的表现。
- TP:预测Yes,实际也是Yes;
- TN:预测No,实际也是No;
- FP:预测Yes,实际No;
- FN:预测No,实际Yes。

- Accuracy, Precision, Recall & F1
Accuracy是分类器总体的正确率
Recall(Sensitivity / true positive rate - TPR):true positives out of all actual positives
Precision:true positives out of all positive preds
F1值是precision & recall 的调和平均数。调和平均数更加注重较低的数值。只有当precision & recall 均很高,F1才会高。
在构建CM之前,需要一系列预测值,从而才能够和真实的值进行比较。这里使用cross_val_predict()函数进行预测,该函数是进行了K折预测。在得到了预测结果之后,构建混淆矩阵CM。
from sklearn.model_selection import cross_val_predictfrom sklearn.metrics import confusion_matrixy_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv = 3)confusion_matrix(y_train_5, y_train_pred)
混淆矩阵的结果如下:

第一行是“非5”,从左到右:53779个是正确被分为“非5”(true negative - TN),800个是被错误分为“真5”(false positive - FP)。
第二行是“真5”,从左到右:1510是错误被分为“非5”(false negtive - FP),3911是正确被分为“真5”(true positive - TP)。
一个完美的分类器应该只得到“TP”和“TN”,即对角线存在数字,非对角线为0。
from sklearn.metrics import precision_score, recall_score, f1_scoreprint(precision_score(y_train_5, y_train_pred),recall_score(y_train_5, y_train_pred),f1_score(y_train_5, y_train_pred))
结果:precision=0.8302, recall=0.7215,f1=0.7720。因此,结果并没有原先那么好,只检测了79%。
尽管F1值偏好precision和recall相似的分类器,但在某些情况下,我们需要关注precision;而在另一些情况下,我们需要关注recall。例如,如果你希望分类器能够检测哪些视频对孩子是安全的(极力提高precision),会希望有一个分类器哪怕误杀好的视频(较低的recall),要只保留safe的视频(high precision)。另一方面,如果训练分类器用于检测盗窃现象(极力提高recall),尽管precision低,但是recall要高;即尽管报假警,但是所有盗窃行为都可以被抓住。
因此,precision和recall不能够同时兼得,只能够权衡。
- Precision / Recall Tradeoff

从左到右的向下箭头分别代表了精度逐渐提高(阈值上升),但是召回率逐渐下降。第一个向下箭头的右边,5都被包含进来,但是错误识别了2和6,因此precision=6/8=75%;第二个向下箭头的右边,有4个“5”被包含进来,漏了2个“5”,因此recall=4/6,但是依然错误识别了6,precision=4/5=80%;第三个向下箭头,有3个5全部正确被识别,但是漏了3个5,因此recall=3/6=50%,precision=3/3=100%。
阈值 / decision_function
如何人为改变阈值?这里通过调用分类器的decision_function,从而得到了阈值分数(or 置信分数)y_scores。
some_digit = X[0]# 调用decision_function,查看some_digit实例的置信分数。y_scores = sgd_clf.decision_function([some_digit])print(y_scores) # 结果为4135.50535978# 如果强行设定阈值为0,由于y_scores在阈值0以上,因此预测得到的y_pred为True。threshold = 0y_some_digit_pred = (y_scores > threshold)print(y_some_digit_pred) # 结果为True# 但如果设定阈值为5000,超过了y_score,将会导致真实的标签变为False。y_some_digit_pred = (y_scores > 5000)print(y_some_digit_pred) # 结果为FALSE
由于SGDClassifier分类器的阈值默认为0,当我们强行设定较高的阈值的时候,那么可能会错过正确的分类结果,降低recall,但是提高了precision。
from sklearn.model_selection import cross_val_predictfrom sklearn.metrics import precision_recall_curve# 加上method='decision_function',返回的是置信分数,而不是预测结果。y_scores = cross_val_predict(sgd_clf, X_train,y_train_5, cv=3,method='decision_function')# 得到分数之后,通过precision_recall_curve计算在所有可能阈值的前提条件下,得到的精度和召回率。precs, recls, thresholds = precision_recall_curve(y_train_5, y_scores)# 画出精度和召回率相对于阈值的函数def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):plt.plot(thresholds, precisions[:-1], "b--", label="Precision")plt.plot(thresholds, recalls[:-1], "g-", label="Recall")plt.legend()plot_precision_recall_vs_threshold(precs, recls, thresholds)plt.show()

以上是recall和precision相对于置信分数的折线图。实际上,我们也能够直接画出recall-precision的折线图。
plt.plot(recls[:-1], precs[:-1], 'b-')plt.xlabel('recall')plt.ylabel('precision')plt.show()
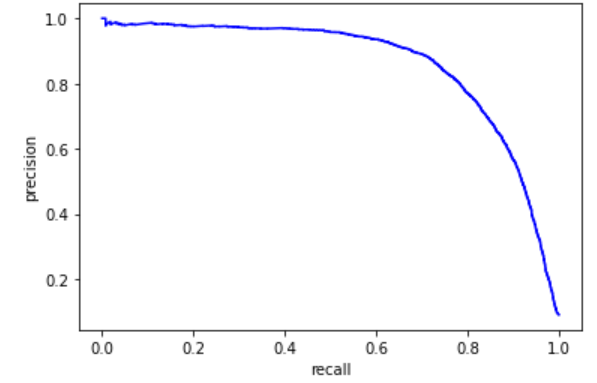
当我们强制precision高于90%的时候,找到对应的threshold的值(通过索引函数np.argmax找到)。然后将训练的预测值重新得到标签,最后计算对应的precision和recall。
threshold_90_precision = thresholds[np.argmax(precs >= 0.90)]y_train_pred_90 = (y_scores >= threshold_90_precision)print(precision_score(y_train_5, y_train_pred_90))# 90%print(recall_score(y_train_5, y_train_pred_90))# 67.90%
ROC曲线(Receiver Operating Characteristic)
经常和二元分类器(only!!!)一起使用的工具,称为受试者工作特征曲线(ROC)。和精度/召回率非常相似,但是绘制的图形不是精度和召回率,而是真正类率(true positive rate,TPR)和假正类率(false positive rate,FPR)。
- 真-正类率(TPR,Recall,sensitivity)= 本身为正,也被模型判定为正。
- 真-负类率(TNR,or 特异度 specificity)= 本身为负,也被模型判定为负。
- 假-正类率(FPR)= 本身为负,但是被模型判定为正 = 1 - TNR = 1 - specificity
- 假-负类率(FNR)= 本身为正,但是被模型判定为负 = 1 - TPR。
ROC绘制了 TPR 和 FPR(1 - specificity)之间的关系。
使用sklearn中的roc_curve函数,计算不同阈值下的TPR和FPR。同样这里存在Tradeoff——TPR(召回率)越高,FPR也就越多。虚线表示的是纯随机分类器的ROC曲线。那么一个优质的分类器应该越向左上角集中越好。
- roc_curve(真实的二分标签, y_score)函数中,
- 第1个参数传入的是真实的二分标签(例如{-1, 1} or {0, 1}),这里是y_train_5;
- 第2个标签是y_score,要么是predict_proba函数返回的正例的概率估计值,要么是decision_function返回的正例阈值。 ```python from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train_5, y_scores)
画图
def plot_roc_curve(fpr, tpr, label=None): plt.plot(fpr, tpr, linewidth=2, label=label) plt.plot([0, 1], [0, 1], ‘k—‘) # Dashed diagonal plt.ylabel(‘TPR / Sensitivity / Recall’) plt.xlabel(‘FPR = 1 - Specificity’) plt.legend()
plot_roc_curve(fpr, tpr) plt.show()
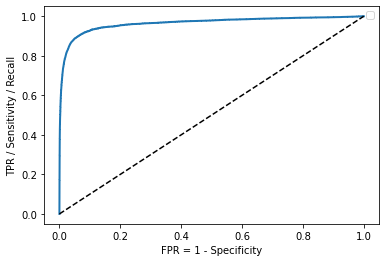<br />上图绘制了所有可能的阈值下,FPR和TPR的关系。同样,可以通过计算曲线下面的面积(AUC,area under the curve),判断分类器是否完美。完美的分类器ROC 的 AUC 应该为1,纯随机的ROC AUC 为 0.5。```pythonfrom sklearn.metrics import roc_auc_scoreroc_auc_score(y_train_5, y_scores)# 0.964253900779017
ROC 和 precision-recall曲线非常类似。如何选择?当正类很少,或者更加关注假正类、而不是假负类,那么应该使用PR曲线,反之则为ROC曲线。
cross_val_predict VS cross_val_score
- 当使用cross_val_score的时候,我们得到的是输出结果的“均值”,因此会受到fold数量的影响,且当fold数量越高,那么误差能够被显著摊低;
- 当使用cross_val_predict的时候,增大fold仅仅是增加了每一折测试元素之前的训练数据量,结果并没有受到影响;且增加fold,将会导致每一折训练对训练数据产生过拟合,从而cross_val_predict的预测标签的表现并不会随着fold数量上升而得到改善。
尝试random forest分类器
尝试训练RandomForest分类器,比较和SGDClassifier的分类器的ROC曲线和ROC AUC分数。
由于RandomForest分类器没有decision_function,但是有dict_proba方法——返回的是数组,每行代表一个实例,每列代表一个类别,意思是某个给定实例属于某个给定类别的概率。
一般scikit-learn分类器都会有decision_function或者dict_probs。
from sklearn.ensemble import RandomForestClassifierforest_clf = RandomForestClassifier(random_state=42)y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv = 3, method='predict_proba')
y_probas_forest形状如下:第一列是标签为0的负例预测结果,第二列是标签为1的正例预测结果。
由于roc_curve函数需要的是标签和分数,这里通过正类的概率 y_scores_forest 作为分数。
# 挑出正例的概率,即为score。y_scores_forest = y_probas_forest[:, 1]fpr_forest, tpr_forest, threshold_forest = roc_curve(y_train_5, y_scores_forest)# 画出ROC曲线plt.plot(fpr, tpr, "b:", label="SGD")plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")plt.legend(loc="lower right")plt.show()# 得到ROC AUCroc_auc_score(y_train_5, y_scores_forest)# 0.9983270680218316
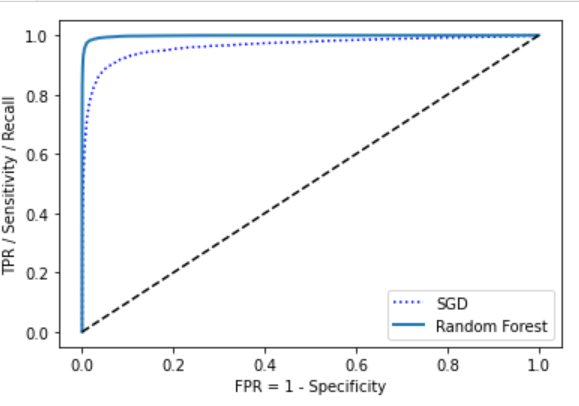
这里看到,随机森林的ROC曲线更好,且ROC_AUC更高。

若有收获,就点个赞吧
0 人点赞
