- Pandas数据结构介绍
- 6
- 6
- DataFrame创建
- 删除行
- 输出结果
- 删除列
- 输出结果
- head
- 输出结果
- tail
- 输出结果
- info
- 输出结果
- Column Non-Null Count Dtype
- 排序
- 输出结果
- 对值排序
- 多列排序
- start = datetime.datetime(2020,1,1) # 开始时间
- end = datetime.date.today() # 结束时间
- AAPL_stock = wb.DataReader(“AAPL”, “yahoo”, start, end) # 参数格式: 股票名称, 财经网站, 开始时间, 结束时间
- AAPL_stock
- 获取A股 上交:股票代码.SS, 深交:股票代码.SZ
- stock = wb.DataReader(“600519.SS”, “yahoo”, start, end)
- stock.to_csv(“20201014.csv”) # 将获取到的数据保存到CSV文件中
- 读取csv文件, 绘制展示各个指标的走势情况
- 绘制展示各个指标的变化情况
- 对其进行统计了分析(数据中各项指标统计结果,保留两位小数)
- pandas+numpy结合使用,可以自定义输出的统计项
- 每一条个项指标的差异值, 后一填减去前一天的结果
- 计算其增长率, (后一填的值减去前一天的值)/前一天的值
- 计算其平均增长率,并且观察那个平均增长率最高
Pandas数据结构介绍
Series
Series介绍
Series是一种一维的数组型对象,它包含了一个值序列(values),并且包含了数据标签,称为索引(index)。
Series创建
pd.Series(data=None,index=None,dtype=None,name=None,copy=False)
- data:创建数组的数据,可为array-like(数组), dict(字典), or scalar value(向量值)
- index:指定索引
- dtype:数组数据类型
- name:数组名称
- copy:是否拷贝
例子:
import pandas as pds1 = pd.Series([1,2,3,4,5,6])s1# 输出内容# 0 1# 1 2# 2 3# 3 4# 4 5# 5 6# dtype: int64
输出之后可以发现它有两列数据,左边的是index(索引),右边的是(value)值
再来看Series的参数,它有个“index”参数,是用来指定索引的,因此就可以实现下面的这种情况
s2 = pd.Series([1,2,3,4,5,6],index=list("abcdef"))s2#输出内容# a 1# b 2# c 3# d 4# e 5# f 6# dtype: int64
从上面的输出结果可以看到,它的索引都被替换成了“abcdef”
再下来,Series的data参数是允许传入dict的,如下:
d = {"name":"connor", "age":18, "gender":"men"}s4 = pd.Series(d)s4# 输出内容# name connor# age 18# gender men# dtype: object
同样,输出结果里左边是index,右边value。
然后这里再给它传入index参数,就会出现下面的情况:
d = {"name":"connor", "age":18, "gender":"men"}index_data = ["class", "name", "gender"]s5 = pd.Series(d,index_data)s5# 输出内容# class NaN# name connor# gender men# dtype: object#
从上面的输出结果可以看到:
“class”由于在字典没有找到对应的key,所以输出的时候显示为NaN
“age”由于没有在索引中,因此会将它排除
再下来可以给data传入一个向量
import numpy as nps6 = pd.Series(np.random.randint(1,10,size=5))s6# 输出结果# 0 3# 1 8# 2 5# 3 2# 4 2# dtype: int32
另外在使用“index”参数时还需要注意的一些地方:
- 这里的索引是允许重复的,即index允许传“aabbcd”
- 索引与值的个数是必须相等的
接下来再看看dtype参数,其实在上面的输出结果里面都已经有显示了 dtype: int32,这里显示的就是它的数据类型,也可以单独使用 dtype 来查看:
s6.dtype# 输出结果# dtype('int32')
与numpy一样,它也可以更改数据类型:
s6.astype("float64")# 输出结果# 0 3.0# 1 8.0# 2 5.0# 3 2.0# 4 2.0# dtype: float64
再来看看“name”参数,这是用于给这个数据取一个名字
s7 = pd.Series(np.random.randint(1,10,size=5), name="Series_name")s7# 输出结果# 0 6# 1 4# 2 7# 3 1# 4 8# Name: Series_name, dtype: int32
除了给数组取名字,它还可以给索引取个名字
s7.index.name = "id"s7# 输出结果# id# 0 6# 1 4# 2 7# 3 1# 4 8# Name: Series_name, dtype: int32
Series的索引与值
先生成一个数组,为了方便理解,index我用“abcde”代替
s8 = pd.Series(np.random.randint(1,10,size=5), index("abcde"))s8# 输出结果# a 9# b 3# c 6# d 8# e 7# dtype: int32
查看前三条数据:
s8.head(3)# 输出结果# a 9# b 3# c 6# dtype: int32
查看后3条数据:
s8.tail(3)# 输出结果# c 6# d 8# e 7# dtype: int32
获取values:
s8.values# 输出结果# array([9, 3, 6, 8, 7])
获取index:
s8.index# 输出结果# Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
这里要区分一点,索引的数组类型是Index,数据类型是object
获取指定的值:
# array([9, 3, 6, 8, 7])# 比如获取3这个值s8[1]# 输出结果# 3
获取指定的索引值:
# Index(['a', 'b', 'c', 'd', 'e'], dtype='object')# 比如这里获取cs8.index[2]# 输出结果# 'c'
要注意的是,index是不允许修改的,例如:
s8.index[2] = "f"# 这里就会报错并提示Index does not support mutable operations,意思就是索引不可变的
如果实在要修改的话,只能重置索引 reset_index :
s8.reset_index(drop=True)# 输出结果# 0 9# 1 3# 2 6# 3 8# 4 7# dtype: int32
要注意,如果不加drop参数,这个数组将会变成“DataFrame”,如下: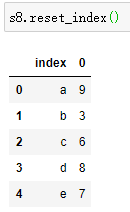
Series索引与切片
依然是用之前的数组
s8 = pd.Series(np.random.randint(1,10,size=5), index("abcde"))s8# 输出结果# a 9# b 3# c 6# d 8# e 7# dtype: int32
在这里“abcde”被我们当做为索引,但实际上他正确的名称应该叫“标签索引”,而我们平常用的索引可以叫“位置索引”。因此如果要通过索引取值,我们就有两种办法:
# 通过标签索引取值s8["c"]# 输出结果# 6# 通过位置索引取值s8[2]#输出结果# 6
可以看到这两种索引方式都能取到同一个值。
与此同时,Pandas也提供了两个方法来实现这个过程:
s8.iloc[2]
6
修改值:```python# 其实很简单s8["c"] = 10s8[2] = 10s8.loc["c"] = 10s8.iloc[2] = 10# 输出结果# a 9# b 3# c 10# d 8# e 7# dtype: int32
切片&神奇索引:
# 神奇索引
s8[[1, 3]]
s8[['b', 'd']]
# 输出结果
# b 3
# d 8
# dtype: int32
# 切片
s8[:2]
# 输出结果
# a 9
# b 3
# dtype: int32
# 布尔索引
s8>5
# 输出结果
# a True
# b False
# c True
# d True
# e True
# dtype: bool
# 取出为s8>5为True的值
s8[s8>5]
#输出结果
# a 9
# c 10
# d 8
# e 7
# dtype: int32
Series的运算
pandas与numpy一样,它会根据数组内的值自动的转换数据类型
d1 = ["a", "b", None]
pd.Series(d1)
# 0 a
# 1 b
# 2 None
# dtype: object
d2 = [1,2,3,None]
pd.Series(d2)
# 0 1.0
# 1 2.0
# 2 3.0
# 3 NaN
# dtype: float64
四则运算:
s8-1
s8+2
s8*2
s8/2
这些运算都是会计算整个数组所有的值
in运算:
要注意,in运算并非是判断value,而是判断索引
# 当前的值
# a 9
# b 3
# c 10
# d 8
# e 7
# 如果要判断9是否在数组里,使用平常的in运算
9 in s8
# False 这里返回的False,因为它判断的实际是索引
# 所以判断a是否在数组里,就会是True
"a" in s8
# True
# 那么如果真的要判断value,可以这样
9 in s8.values
# True
Series与Series的运算
有共同索引时:
t1 = pd.Series(range(10,20))
t2 = pd.Series(range(10,15))
print(t1)
print(t2)
# 0 10
# 1 11
# 2 12
# 3 13
# 4 14
# 5 15
# 6 16
# 7 17
# 8 18
# 9 19
# dtype: int64
# 0 10
# 1 11
# 2 12
# 3 13
# 4 14
# dtype: int64
t1+t2
# 0 20.0
# 1 22.0
# 2 24.0
# 3 26.0
# 4 28.0
# 5 NaN
# 6 NaN
# 7 NaN
# 8 NaN
# 9 NaN
# dtype: float64
从结果中可以看到,前5个都进行了相加;但是由于t2数组只有5个值,因此后面5个都会填充NaN进行相加,而NaN与任何数进行运算最终得到的依然是NaN。
不存在共同索引时:
t3 = pd.Series(range(10,20), index=range(10))
t4 = pd.Series(range(10,15), index=range(10,15))
print(t3)
print(t4)
# 0 10
# 1 11
# 2 12
# 3 13
# 4 14
# 5 15
# 6 16
# 7 17
# 8 18
# 9 19
# dtype: int64
# 10 10
# 11 11
# 12 12
# 13 13
# 14 14
# dtype: int64
t3 + t4
# 0 NaN
# 1 NaN
# 2 NaN
# 3 NaN
# 4 NaN
# 5 NaN
# 6 NaN
# 7 NaN
# 8 NaN
# 9 NaN
# 10 NaN
# 11 NaN
# 12 NaN
# 13 NaN
# 14 NaN
# dtype: float64
很明显的,相加后全部为NaN
总结
Series:
- 创建Series方法:np.Series()
- data参数传值可以传数组、dict
- index参数可以指定索引
- s.index可以获取索引,s.value可以获取值
切片与索引:
- 可以通过标签索引获取值
- 可以通过索引(位置索引)获取值
- 也提供np.loc和np.iloc分别根据标签索引和索引(位置索引)获取值
运算:
- 两个Series数组相加,标签索引要一致,否则相加后为NaN
- 可以使用布尔索引、比较索引等
DataFrame创建
DataFrame介绍
DataFrame表示的是矩阵的数据表,它包含已排序的列集合,每一列可以是不同的值类型(数值,字符串,布尔值)。在DataFrame中,数据被存储为一个以上的二维块。
在Numpy中,每列的值的类型是一样的,而Pandas则是可以不一样

DataFrame创建
pd.DataFrame(data=None,index=None,columns=None,dtype=None,copy=False)
- data:创建数组的数据,可为ndarray, dict
- index:指定索引
- dtype:数组数据类型
- copy:是否拷贝
创建DataFrame
# 创建DataFrame
df1 = pd.DataFrame(np.arange(12).reshape(3,4))
# data为ndarray时, 行索引(index)0轴, 列索引(columns)1轴
df1
# 输出结果
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
创建DataFrame时指定索引
# 创建DataFrame时指定索引
df2 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("ABCD"))
# index为行索引,columns为列索引
df2
# 输出结果
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
使用dict作为data的值
data = {
"name": ["小猫", "小狗", "小兔"],
"size": ["小", "中", "小"]
}
df3 = pd.DataFrame(data)
df3
#输出结果
name size
0 小猫 小
1 小狗 中
2 小兔 小
从结果可以看出,如果data是dict, key值将会作为列名,而由于没有指定index,所以行名则为“0、1、2”。
然后如果dict中每个key的值长度不一样时,是无法创建DataFrame,会报错“arrays must all be same length”,例如这样:
data = {
"name": ["小猫", "小狗", "小兔"],
"size": ["小", "中"]
}
# 像这样的值是无法创建DataFrame的
接下来再试试使用dict作为data的值并且指定索引**
data = {
"name": ["小猫", "小狗", "小兔"],
"size": ["小", "中", "小"],
}
df4 = pd.DataFrame(data, columns=['size', 'name']) # 指定列索引
df4
# 输出结果
size name
0 小 小猫
1 中 小狗
2 小 小兔
df4 = pd.DataFrame(data, columns=['size', 'name', 'food']) # 如果指定列索引时,有不存在的列名会就输出NaN
df4
#输出结果
size name food
0 小 小猫 NaN
1 中 小狗 NaN
2 小 小兔 NaN
df4 = pd.DataFrame(data, index=list("abc")) # 指定行索引的方式也是一样的,用index
df4
# 输出结果
name size
a 小猫 小
b 小狗 中
c 小兔 小
在上面提到,如果传入的是dict,则每个key的值的长度必须一致,那反过来如果传入的是个ndarray数组且里面嵌套了dict且每个dict的长度都不一样,这时的结果如下:
# data是个ndarray数组且里面嵌套了dict且每个dict的长度都不一样
data = [
{'name': 'connor', 'age': 20},
{'name': 'connonlly', 'age': 20, 'gender': 'man'},
{'name': 'ken', 'gender': 'man'}
]
df5 = pd.DataFrame(data)
df5
# 输出结果
name age gender
0 connor 20.0 NaN
1 connonlly 20.0 man
2 ken NaN man
# 这时它是可以创建出DataFrame的,但是缺失的指都会用NaN来表示
如果某一列原本是整数的,当这列出现了NaN时,为了兼容NaN,这一列都会数据类型都会转为浮点数。
DataFrame基本操作
df.shape # 查看数组形状,返回值为元组
df5.shape # 输出结果 (3, 3) # 意思就是一个3行3列的二维数组df.dtypes # 查看列数据类型
df5.dtypes # 输出结果 name object age float64 gender object dtype: objectdf.ndim # 数据维度,返回为整数
df5.ndim # 输出结果 2 # 意思就是当前数组是一个2维数组df.index # 行索引
df5.index # 输出结果 RangeIndex(start=0, stop=3, step=1)df.columns # 列索引
df5.columns # 输出结果 Index(['name', 'age', 'gender'], dtype='object')df.drop(index=0 | columns=[‘name’,’age’]) # 返回被删除之后的DataFrame ```python
删除行
df5.drop(index=0)
输出结果
name age gender 1 connonlly 20.0 man 2 ken NaN man
删除列
df5.drop(columns=’age’)
输出结果
name gender
0 connor NaN 1 connonlly man 2 ken man
> df.drop()方法默认是不改变原有数据的,如果要改变原有数据可以修改参数inplace=True
- **del df['name'] # 删除**
```python
# del与drop的最直观的区别在于del直接在原数据上操作,而drop默认是不修改原数据
del df5["age"]
df5
# 输出结果
name gender
0 connor NaN
1 connonlly man
2 ken man
DataFrame查询
- df.head(n) # 显示头部几行,默认前5行
- df.tail(n) # 显示末尾几行,默认后5行
- df.info() # 相关信息概述 ```python data = [ {“name”:”amy”,”age”:18,”tel”:10086}, {“name”:”bob”,”age”:18}, {“name”:”james”,”tel”:10086}, {“name”:”zs”,”tel”:10086}, {“name”:”james”,”tel”:10086}, {“name”:”ls”,”tel”:10086}, ]
df6 = pd.DataFrame(data) # 创建DataFrame
head
df6.head(3)
输出结果
name age tel
0 amy 18.0 10086.0 1 bob 18.0 NaN 2 james NaN 10086.0
tail
df6.tail(3)
输出结果
name age tel
3 zs NaN 10086.0 4 james NaN 10086.0 5 ls NaN 10086.0
info
df6.info()
输出结果
Column Non-Null Count Dtype
0 name 6 non-null object 1 age 2 non-null float64 2 tel 5 non-null float64 dtypes: float64(2), object(1) memory usage: 272.0+ bytes
<a name="kZog8"></a>
#### DataFrame索引
| 类型 | 描述 |
| --- | --- |
| df[:位置索引]或df[:"标签索引"] | 表示对行操作 |
| df["列索引"]或 df[["列索引","列索引"]] | 表示对列进行操作 |
```python
data = [
{"name":"amy","age":18,"tel":10086},
{"name":"bob","age":18},
{"name":"james","tel":10086},
{"name":"zs","tel":10086},
{"name":"james","tel":10086},
{"name":"ls","tel":10086},
]
df7 = pd.DataFrame(data, index=list("abcdef"))
# 行索引
# 取前两行数据
df7[:2] # 通过位置索引
df7[:"b"] # 使用标签索引,标签索引是双闭合的,所以只取前两行就要写“c”
# 输出结果
name age tel
a amy 18.0 10086.0
b bob 18.0 NaN
# 但是要注意,不能直接指定索引值,会报错
# df7[0]
# df7["a"]
# 以上两种方式都是会报错的
# 列索引
df7["name"] # 传入列名
# 输出结果
a amy
b bob
c james
d zs
e james
f ls
Name: name, dtype: object
# 这种取单列的,实际取出来的就是一个Series
df7[["name","age"]] # 取多列,要用神奇索引,两个[[]]
name age
a amy 18.0
b bob 18.0
c james NaN
d zs NaN
e james NaN
f ls NaN
# 布尔索引
# 取出不为James的数据
df7[df7["name"] != "james"] # 原理就是先判断df6哪些不等于James,然后再将为True的输出
# 输出结果
name age tel
0 amy 18.0 10086.0
1 bob 18.0 NaN
3 zs NaN 10086.0
5 ls NaN 10086.0
# 当数据全部为数值时,使用布尔索引可以直接将整个数组进行判断
df8 = pd.DataFrame(np.arange(16).reshape(4,4), columns=list("abcd"))
df8>5
# 输出结果
a b c d
0 False False False False
1 False False True True
2 True True True True
3 True True True True
# 但是如果此时直接输出,为False的都会填充为NaN
df8[df8>5]
# 输出结果
a b c d
0 NaN NaN NaN NaN
1 NaN NaN 6.0 7.0
2 8.0 9.0 10.0 11.0
3 12.0 13.0 14.0 15.0
Pandas字符串的常用方法
| 方法 | 描述 |
|---|---|
| df.str.contains() | 返回表示各字符串是否含有指定模式的布尔型数组 |
| df.str.len() | 返回各字符串的长度 |
| df.str.lower(),df.str.upper() | 将各字符串全转为小写或大写 |
| df.str.slice() | 对series中的各个字符串进行子串截取 |
| df.str.split() | 根据分隔符或正则表达式对字符串进行拆分 |
练习
1、使用Pandas读取文件
# 读取CSV文件
data = pd.read_csv("filename")
# 读取前两行数据
#data.head(2)
data[:2] # 两个方法是同样的效果
# 取出某一列
data["columns"]
# 取出某一列的前两行
data[:2]["cloumns"] # 意思是先取出整个文档的前两行,然后再取指定的列
2、找到值大于指定数值的行
data[data["columns"] > 800] # 布尔索引
3、在第二列找到值大于指定数值的行并且其第一列的字符串的长度>4
# 首先找出大于指定的数据
data[data["columns_2"] > 700]
# 然后找出字符串长度>4的数据
data[data["columns_1"].str.len() > 4]
# 然后将上面两个条件组合起来
data[(data["cloumns_2"] > 700) & (data["columns_1"].str.len() > 4)] # 在这里如果组合两个条件不能用and,要用&符,最好前后两个条件都加个括号
使用loc及iloc选择数据
- df.loc[] 通过轴标签选择数据
- df.iloc[] 通过整数(位置)标签选择数据
具体使用如下
| 类型 | 描述 |
|---|---|
| df.loc[val] | 根据标签索引选择DataFrame的单行或多行 |
| df.loc[:,val] | 根据标签索引选择DataFrame的单列或多列 |
| df.loc[val1,val2] | 同时选择行和列中的一部分 |
| df.iloc[where] | 根据位置索引选择DataFrame的单行或多行 |
| df.iloc[:,where] | 根据位置索引选择DataFrame的单列或多列 |
| df.iloc[where_i,where_j] | 根据位置索引选择行和列 |
**
# 创建数组
df1 = pd.DataFrame(np.arange(16).reshape(4,4), index=("php", "java", "python", "go"), columns=["one", "tow", "three", "four"])
df1
# 输出结果
one tow three four
php 0 1 2 3
java 4 5 6 7
python 8 9 10 11
go 12 13 14 15
"""
df.loc[] 用在标签索引
注意: 要记住标签索引是双闭合的
"""
# 取python行的数据
df1.loc["python",:] # 逗号左边是行,右边是列; ":"是取全部列的意思
# 取three列
df1.loc[:, "three"]
# 取不连续的两行数据,要用到神奇索引
df1.loc[["php","go"], :]
# 取不连续的两列数据,要用到神奇索引
df1.loc[:, ["one", "four"]]
# 取连续的两行
df1.loc["java": "python", :] # 注意: 要记住标签索引是双闭合的
# 取连续的两列
df1.loc[:, "tow":"three"]
"""
df.iloc[] 使用位置索引
注意: 位置索引是左闭右开的
"""
# 取python行
df1.iloc[2, :]
# 取three列
df1.iloc[:, 2]
# 取不连续的两行数据,要用到神奇索引
df1.iloc[[1,3], :]
# 取不连续的两列数据,要用到神奇索引
df1.iloc[:, [1, 3]]
# 取连续的两行
df1.iloc[1:3, :] # 注意: 位置索引是左闭右开的
# 取连续的两列
df1.iloc[:, 1:3]
# 结合布尔索引,取出one、tow、three 3列数据且tow列>3的
df1.iloc[:, :3][df1.tow>3]
注意
Pandas中可以直接赋值np.nan,且赋值当前列数据会自动转为浮点类型。而不是整个数组都转,这主要是因为Pandas数据可以是异质性。
DataFrame算术
实际上,通过 + - * / // ** 等符号可以直接对DataFrame与DataFrame之间或者DataFrame以及Series之间进行运算。但秉承的原则就是对应索引运算,存在索引不同时,返回结果为索引对的并集。
但是实际操作会发现,当存在索引不同时,返回的值自动填充NaN。**
# 创建两个数组
df2 = pd.DataFrame(np.ones((2,2)), columns=list("AB"))
df3 = pd.DataFrame(np.ones((3,3)), columns=list("ABC"))
df2
# 输出结果
A B
0 1.0 1.0
1 1.0 1.0
df3
# 输出结果
A B C
0 1.0 1.0 1.0
1 1.0 1.0 1.0
2 1.0 1.0 1.0
df2+df3
#输出结果
A B C
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
# 结构相同的时候
ds = df3.iloc[0]
ds
#输出结果
A 1.0
B 1.0
C 1.0
Name: 0, dtype: float64
ds+df3 # 这里用到了广播机制,即每一行都参与了计算
# 输出结果
A B C
0 2.0 2.0 2.0
1 2.0 2.0 2.0
2 2.0 2.0 2.0
# Series与DataFrame的计算
ds1 = pd.Series(range(5), index=range(5))
ds1
#输出结果
0 0
1 1
2 2
3 3
4 4
dtype: int64
ds1 + df2
# 输出结果,Series数组会拼接到列索引上且所属数据都变成了NaN
A B 0 1 2 3 4
0 NaN NaN NaN NaN NaN NaN NaN
1 NaN NaN NaN NaN NaN NaN NaN
使用填充值的算术方法
| 方法 | 描述 |
|---|---|
| add | 加法(+) |
| sub | 减法(-) |
| div | 除法(/) |
| floordiv | 整除(//) |
| mul | 乘法(*) |
| pow | 幂次方(**) |
**
# add的使用
df2.add(df3)
# 输出结果, 就这样输出的话,其实和直接用+号是一样的
A B C
0 2.0 2.0 NaN
1 2.0 2.0 NaN
2 NaN NaN NaN
# 自动填充值
df2.add(df3, fill_value=0) # fill_value 填充值填充在确实数组上再作运算
# 输出结果
A B C
0 2.0 2.0 1.0
1 2.0 2.0 1.0
2 1.0 1.0 1.0
注意**
- Series使用算术方法,不支持指定填充值
DataFrame排序
- df.sort_index(axis=0,ascending=True) # 索引排序
df3.sort_index(ascending=False, axis=1) # 指定列索引的排序
- **df.sort_values(by) ** # 值排序
- by指定一列或多列作为排序键
对值排序
df3.sort_values(by=0) # 方便理解可以参考EXCEL的排序规则
多列排序
df3.sort_values(by=[0,1])
**注意**
- by = [col1,col2] 是先给col1排序 当col1有相同值时,col2中按排序顺序再排序
<br />
<a name="TPG9U"></a>
#### 描述性统计的概述和计算
| 方法 | 描述 |
| --- | --- |
| count | 非NA值的个数 |
| min,max | 最小值,最大值 |
| argmin,argmax | 最小值,最大值的索引位置(整数索引) |
| idxmin,idxmax | 最小值,最大值的标签索引 |
| sum | 求和 |
| mean | 平均值 |
| median | 中位数 |
| var | 方差 |
| std | 标准差 |
| cumsum | 累计值 |
| pct_change | 百分比 |
| describe | 描述信息,显示统计、标准差、平均值等各种信息 |
**注意**
- 统计计算中,如果数组中有NaN,那计算时会跳过这个NaN
<a name="YsrIt"></a>
#### 练习
使用pandas_datareader接口库获取股票数据,并按要求进行统计, 题目如下:<br />1.读取苹果公司股票数据,保存为csv文件。<br />2.读取该csv文件,绘制展示各个指标的走势情况。<br />3.对其进行统计量分析(数据中各项指标统计结果,保留两位小数)。<br />4.数据变化情况统计
- 每一天各项指标的差异值
- 计算其增长率
- 计算其平均增长率,并且观察哪个平均增长率最高
import numpy as np import pandas as pd from pandas_datareader import data as wb import datetime
start = datetime.datetime(2020,1,1) # 开始时间
end = datetime.date.today() # 结束时间
AAPL_stock = wb.DataReader(“AAPL”, “yahoo”, start, end) # 参数格式: 股票名称, 财经网站, 开始时间, 结束时间
AAPL_stock
获取A股 上交:股票代码.SS, 深交:股票代码.SZ
stock = wb.DataReader(“600519.SS”, “yahoo”, start, end)
stock.to_csv(“20201014.csv”) # 将获取到的数据保存到CSV文件中
读取csv文件, 绘制展示各个指标的走势情况
APL_data = pd.read_csv(“20201014.csv”, index_col=0, parse_dates=True) # index_col指定第0列为行索引,parse_dates将时间转为标准格式 APL_data.head() # 只读取前5条数据
绘制展示各个指标的变化情况
APL_data.plot(figsize=(14,8), subplots=True) #subplots=True将每个图形绘制在子图中
对其进行统计了分析(数据中各项指标统计结果,保留两位小数)
APL_data.describe()
pandas+numpy结合使用,可以自定义输出的统计项
APL_data.aggregate([np.mean, np.std, np.median, min, max])
每一条个项指标的差异值, 后一填减去前一天的结果
APL_data.diff().head()
计算其增长率, (后一填的值减去前一天的值)/前一天的值
APL_data.pct_change().head()
计算其平均增长率,并且观察那个平均增长率最高
APL_data.pct_change().mean().plot(kind=”bar”, figsize=(14,8)) # 使用图形展示 ```

若有收获,就点个赞吧
0 人点赞
