数据合并
数据合并也就是说将多个数据集拼接在一起,但是合并的方式主要分为:pandas.merge,pandas.concat,df.join。以下,我们来详细的介绍。
df_l.join
df_l.join(df_r,how=”left”) 默认情况下是把行索引相同的数据合并到一起,以左边的矩阵为主。
import numpy as npimport pandas as pddf1 = pd.DataFrame(np.arange(12).reshape(3,4), index=list("ABC"), columns=list("DEFG"))df2 = pd.DataFrame(np.arange(6).reshape(2,3), index=list("AB"), columns=list("WXY"))df3 = pd.DataFrame(np.arange(6).reshape(2,3), index=list("CD"), columns=list("QRE"))"""join 拼接行索引公共的部分的值不会改变df1和df2谁在前面以谁为主, 所以df2较df1缺失的部分会补齐为NaN"""df1.join(df2)"""输出结果D E F G X Z YA 0 1 2 3 0.0 1.0 2.0B 4 5 6 7 3.0 4.0 5.0C 8 9 10 11 NaN NaN NaN""""""df2在左,以df2为主,所以多处的部分会直接去掉"""df2.join(df1)"""输出结果X Z Y D E F GA 0 1 2 0 1 2 3B 3 4 5 4 5 6 7""""""行索引不存在公共部分,以左边为主,df3全补齐为NaN"""df2.join(df3)"""输出结果X Z Y U I OA 0 1 2 NaN NaN NaNB 3 4 5 NaN NaN NaN"""
pd.merge
pd.merge(df_l,df_r) 根据一个或多个键将行进行连接
- how 指定拼接方式;inner,outer,left,right。默认是inner
- on 需要连接的列名。注:必须是公共列
- left_on 左边数组中用作连接的列
- right_on 右边数组中用作连接的列 ```python “”” pd.merage() 这个与join最明显的区别是merage是根据列来拼接,因此如果没有公共的列就会报错 而join是通过行拼接 “”” df4 = pd.DataFrame(np.arange(6).reshape(2,3), index=list(“AB”), columns=list(“XZY”)) df5 = pd.DataFrame(np.arange(6).reshape(3,2), index=list(“ABC”), columns=list(“SX”)) print(df4) print(df5)
“””输出结果 X Z Y A 0 1 2 B 3 4 5
S X A 0 1 B 2 3 C 4 5 “””
“”” 默认以公共列拼接,当公共列有公共元素时,以公共元素直接拼接 “”” pd.merge(df4,df5)
“”” X Z Y S 0 3 4 5 2 “””
“”” 如果没有公共元素时,虽然不会报错,但是拼接后矩阵是空的 “”” df5.loc[“B”,”X”] = 6 # 将df5矩阵里的B行X列的值改为6, pd.merge(df4, df5)
“””输出结果 X Z Y S “””
“”” 公共列中有多个相同的元素,只要有公共元素的,都会拼接 “”” df5.loc[“A”:”B”, “X”] = [0,3] # 将df5矩阵的A~B行的X列的值改为0和3 pd.merge(df4,df5)
“””输出结果 X Z Y S 0 0 1 2 0 1 3 4 5 2 “””
“”” 改变拼接的方式 merge()默认是使用左连接,修改how参数可以改为右连接 “”” pd.merge(df4,df5, how=”right”)
“”” X Z Y S 0 1 NaN NaN 0 1 3 4.0 5.0 2 2 5 NaN NaN 4 “””
“”” on参数,指定拼接列 只能指定公共列,如果是非公共列会报错 “”” pd.merge(df4,df5, on=”X”) # on=并集,默认为None,也就是默认是交集
“””输出结果 X Z Y S 0 3 4 5 2 “””
“”” 指定两个非公共列进行拼接 left_on 左边数组中用作连接的列 right_on 右边数组中用作连接的列
“”” print(df4) print(df5) pd.merge(df4,df5, left_on=”Y”, right_on=”S”)
“””输出结果 X Z Y A 0 1 2 B 3 4 5
S X A 0 1 B 2 3 C 4 5
X_x Z Y S X_y 0 0 1 2 2 3 “””
<a name="7o0DQ"></a>####<a name="1Rmoe"></a>### 数据分组与聚合数据包含在Series、DataFrame数据结构中,可以根据一个或多个键分离到各个组中。分组操作之后,一个函数就可以应用到各个组中,产生新的值。如下图则是简单的分组聚合过程。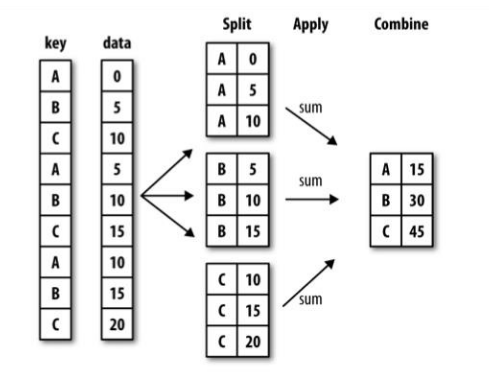<br />key为指定分组的列<br />**<a name="dAeQC"></a>#### df.groupby('key')```pythonimport pandas as pdimport numpy as npdata = {"key1":['a','a','b','b','a'],"key2":['one',"two","one","two","one"],"data1":np.arange(5),"data2":np.arange(5)}df = pd.DataFrame(data)k2_g = df.groupby("key2") # 只分组,并没有进行计算操作# for g in k2_g:# print(g)"""计算时,会自动将字符串的列过滤"""k2_g.sum() # 求和运算"""根据key1标签计算data1的均值"""k1_g = df["data1"].groupby(df["key1"])k1_g.mean()
pd.concat
pd.concat((df_l,df_r),axis=0) 使对象在轴向上进行黏合或”堆叠”
df1 = pd.DataFrame(np.arange(12).reshape(3,4),index=list("ABC"),columns=list("QWER"))df2 = pd.DataFrame(np.arange(15).reshape(3,5),index=list("ABC"),columns=list("ZXCVB"))

若有收获,就点个赞吧
0 人点赞
