5.1 C程序到汇编程序的转换
当我们说到一个RISC-V处理器时,意味着这个处理器能够理解RISC-V的指令集。所以,任何一个处理器都有一个关联的ISA(Instruction Sets Architecture),ISA就是处理器能够理解的指令集。每一条指令都有一个对应的二进制编码或者一个Opcode。当处理器在运行时,如果看见了这些编码,那么处理器就知道该做什么样的操作。
如果你们曾经注意过你们的lab目录,在运行完make qemu之后你会看到一些.o文件,这些就是处理器能够理解的文件。
5.2 RISC-V vs x86
我们在这节课中反复会提到了RISC-V汇编。这一点很重要,因为汇编语言有很多种(注,因为不同的处理器指令集不一样,而汇编语言中都是一条条指令,所以不同处理器对应的汇编语言必然不一样)。如果你使用RISC-V,你不太能将Linux运行在上面。相应的,大多数现代计算机都运行在x86和x86-64处理器上。x86拥有一套不同的指令集,看起来与RISC-V非常相似。通常你们的个人电脑上运行的处理器是x86,Intel和AMD的CPU都实现了x86。
RISC-V中的RISC是精简指令集(Reduced Instruction Set Computer)的意思,而x86通常被称为CISC,复杂指令集(Complex Instruction Set Computer)。这两者之间有一些关键的区别:
- 首先是指令的数量。实际上,创造RISC-V的一个非常大的初衷就是因为Intel手册中指令数量太多了。x86-64指令介绍由3个文档组成,并且新的指令以每个月3条的速度在增加。因为x86-64是在1970年代发布的,所以我认为现在有多于15000条指令。RISC-V指令介绍由两个文档组成。在这节课中,不需要你们记住每一个RISC-V指令,但是如果你感兴趣或者你发现你不能理解某个具体的指令的话,在课程网站的参考页面有RISC-V指令的两个文档链接。这两个文档包含了RISC-V的指令集的所有信息,分别是240页和135页,相比x86的指令集文档要小得多的多。这是有关RISC-V比较好的一个方面。所以在RISC-V中,我们有更少的指令数量。
- 除此之外,RISC-V指令也更加简单。在x86-64中,很多指令都做了不止一件事情。这些指令中的每一条都执行了一系列复杂的操作并返回结果。但是RISC-V不会这样做,RISC-V的指令趋向于完成更简单的工作,相应的也消耗更少的CPU执行时间。这其实是设计人员的在底层设计时的取舍。并没有一些非常确定的原因说RISC比CISC更好。它们各自有各自的使用场景。
- 相比x86来说,RISC另一件有意思的事情是它是开源的。这是市场上唯一的一款开源指令集,这意味着任何人都可以为RISC-V开发主板。RISC-V是来自于UC-Berkly的一个研究项目,之后被大量的公司选中并做了支持,网上有这些公司的名单,许多大公司对于支持一个开源指令集都感兴趣。
如果查看RISC-V的文档,可以发现RISC-V的特殊之处在于:它区分了Base Integer Instruction Set和Standard Extension Instruction Set。Base Integer Instruction Set包含了所有的常用指令,比如add,mult。除此之外,处理器还可以选择性的支持Standard Extension Instruction Set。例如,一个处理器可以选择支持Standard Extension for Single-Precision Float-Point。这种模式使得RISC-V更容易支持向后兼容。 每一个RISC-V处理器可以声明支持了哪些扩展指令集,然后编译器可以根据支持的指令集来编译代码。
5.3 gdb和汇编代码执行
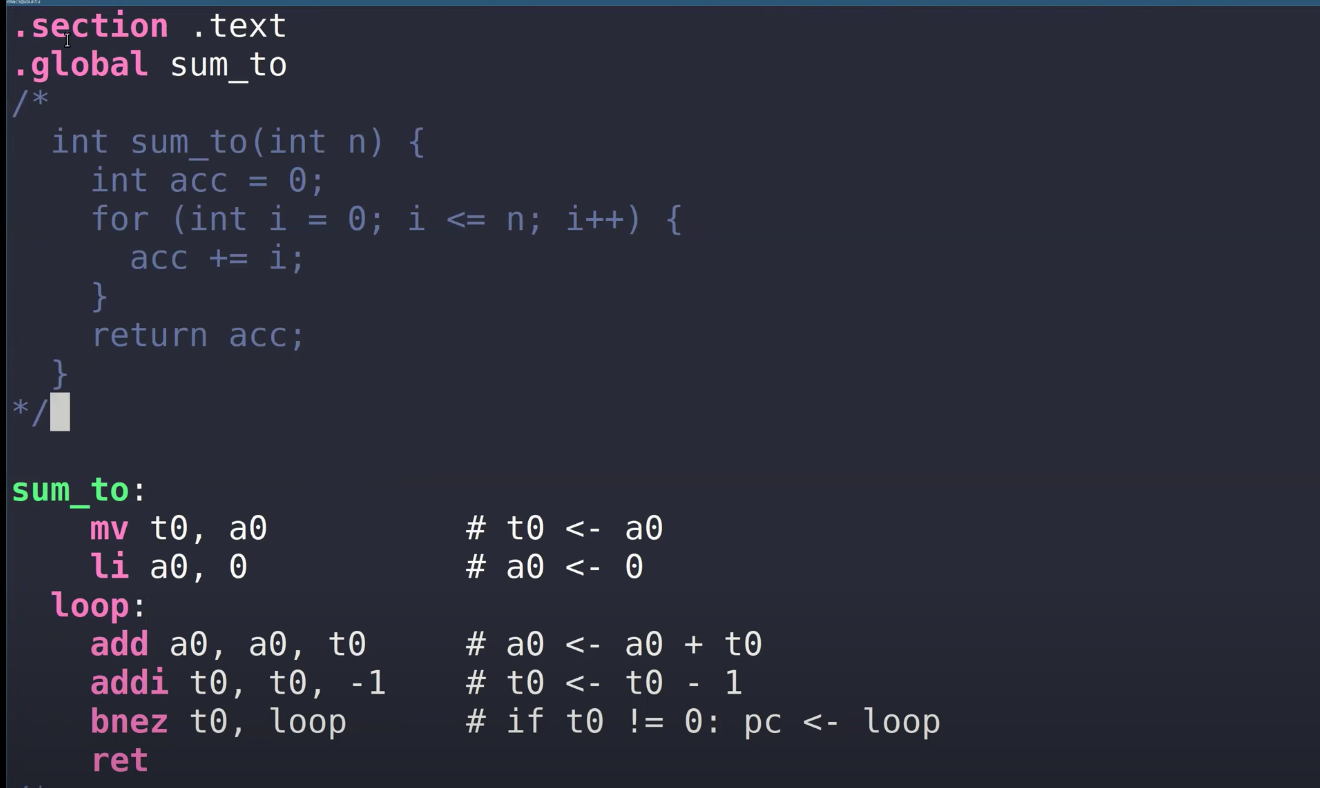
学生提问:这里面.secion,.global,.text分别是什么意思?
TA:global表示你可以在其他文件中调用这个函数。text表明这里的是代码,如果你还记得XV6中的图3.4,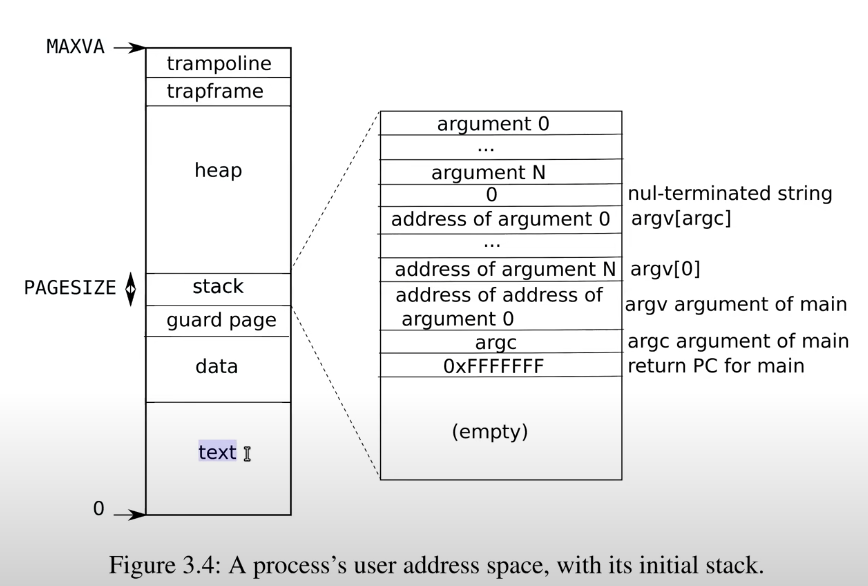
每个进程的page table中有一个区域是text,汇编代码中的text表明这部分是代码,并且位于page table的text区域中。text中保存的就是代码。
5.4 RISC-V寄存器
我们之前看过了汇编语言和RISC-V的介绍。接下来我们看一下之后lab相关的内容。这部分的内容其实就是本节课的准备材料中的内容。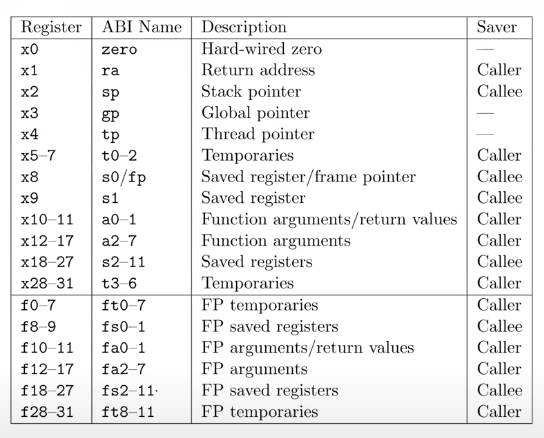
基本上来说,RISC-V中通常的指令是64bit,但是在Compressed Instruction中指令是16bit。
表单中的第4列,Saver列,当我们在讨论寄存器的时候也非常重要。它有两个可能的值Caller,Callee。我经常混淆这两个值,因为它们只差一个字母。我发现最简单的记住它们的方法是:
- Caller Saved寄存器在函数调用的时候不会保存
- Callee Saved寄存器在函数调用的时候会保存

这里的意思是,一个Caller Saved寄存器可能被其他函数重写。假设我们在函数a中调用函数b,任何被函数a使用的并且是Caller Saved寄存器,调用函数b可能重写这些寄存器。我认为一个比较好的例子就是Return address寄存器(注,保存的是函数返回的地址),你可以看到ra寄存器是Caller Saved,这一点很重要,它导致了当函数a调用函数b的时侯,b会重写Return address。所以基本上来说,任何一个Caller Saved寄存器,作为调用方的函数要小心可能的数据可能的变化;任何一个Callee Saved寄存器,作为被调用方的函数要小心寄存器的值不会相应的变化。我经常会弄混这两者的区别,然后会到这张表来回顾它们。
5.5 Stack
下面是一个非常简单的栈的结构图,其中每一个区域都是一个Stack Frame,每执行一次函数调用就会产生一个Stack Frame。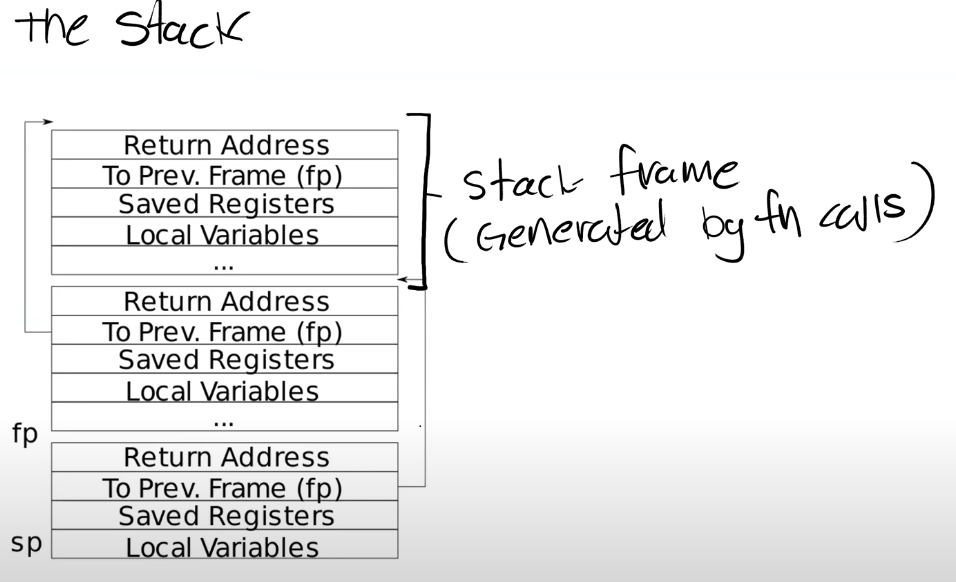
每一次我们调用一个函数,函数都会为自己创建一个Stack Frame,并且只给自己用。函数通过移动Stack Pointer来完成Stack Frame的空间分配。
对于Stack来说,是从高地址开始向低地址使用。所以栈总是向下增长。
有关Stack Frame有两件事情是确定的:
- Return address总是会出现在Stack Frame的第一位
- 指向前一个Stack Frame的指针也会出现在栈中的固定位置
有关Stack Frame中有两个重要的寄存器,第一个是SP(Stack Pointer),它指向Stack的底部并代表了当前Stack Frame的位置。第二个是FP(Frame Pointer),它指向当前Stack Frame的顶部。因为Return address和指向前一个Stack Frame的的指针都在当前Stack Frame的固定位置,所以可以通过当前的FP寄存器寻址到这两个数据。
我们保存前一个Stack Frame的指针的原因是为了让我们能跳转回去。所以当前函数返回时,我们可以将前一个Frame Pointer存储到FP寄存器中。所以我们使用Frame Pointer来操纵我们的Stack Frames,并确保我们总是指向正确的函数。
Stack Frame必须要被汇编代码创建,所以是编译器生成了汇编代码,进而创建了Stack Frame。所以通常,在汇编代码中,函数的最开始你们可以看到Function prologue,之后是函数的本体,最后是Epollgue。这就是一个汇编函数通常的样子。
函数sum_then_double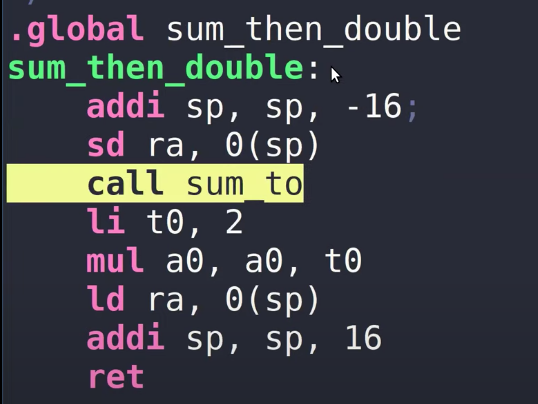
所以在这个函数中,需要包含prologue。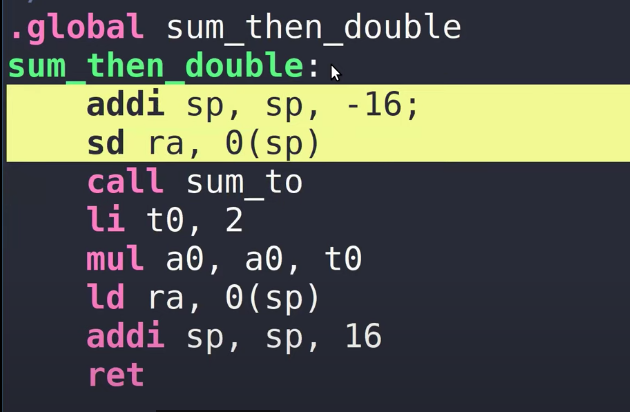
这里我们对Stack Pointer减16,这样我们为新的Stack Frame创建了16字节的空间。之后我们将Return address保存在Stack Pointer位置。
之后就是调用sum_to并对结果乘以2。最后是Epllogue,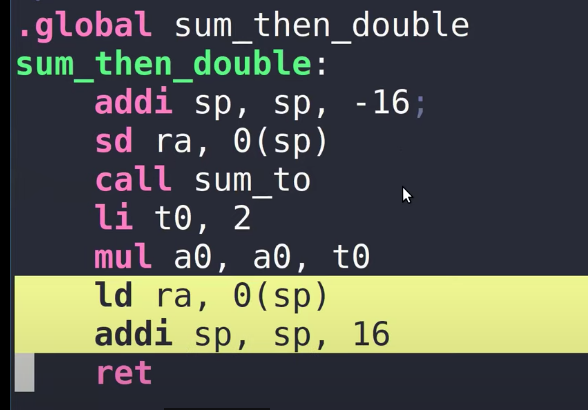
这里首先将Return address加载回ra寄存器,通过对Stack Pointer加16来删除刚刚创建的Stack Frame,最后ret从函数中退出。
如果我们删除掉Prologue和Epllogue,然后只剩下函数主体会发生什么?有人可以猜一下吗?
学生回答:sum_then_double将不知道它应该返回的Return address。所以调用sum_to的时候,Return address被覆盖了,最终sum_to函数不能返回到它原本的调用位置。
是的,完全正确。
5.6 Struct
基本上来说,struct在内存中是一段连续的地址,如果我们有一个struct,并且有f1,f2,f3三个字段。
当我们创建这样一个struct时,内存中相应的字段会彼此相邻。你可以认为struct像是一个数组,但是里面的不同字段的类型可以不一样。(注,这应该是这一节中最有用的一句话了。。。)

若有收获,就点个赞吧
0 人点赞
