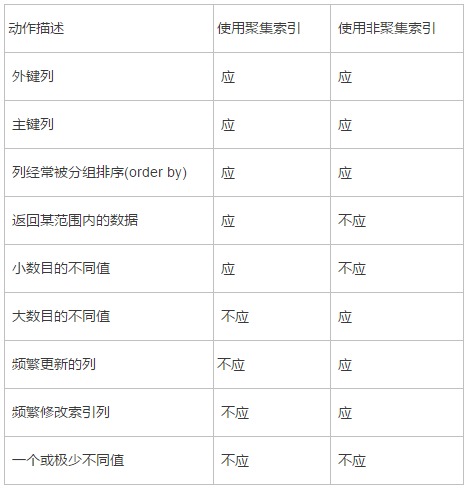
索引的简介: 索引的分类: 什么情况下使用索引: 语法: name ( column_name [ ASC | DESC ] [ ,…n ] ) [ ,…n ] ] ::= ::= 参数: 例子: 50 , —表示填充因子为50%50 , —表示填充因子为50%
—创建非聚集索引
—创建唯一索引
—创建非聚集覆盖索引,未指定默认为非聚集索引001 and S_StuNo <= 020
—创建非聚集筛选索引,未指定默认为非聚集索引001 and S_StuNo <= 020 修改索引: 删除和查看索引:
—删除指定表 Student 中名为 Index_StuNo_SName 的索引
—检查表 Student 中索引 UQ_S_StuNo 的碎片信息
—整理 Test 数据库中表 Student 的索引 UQ_S_StuNo 的碎片
—更新表 Student 中的全部索引的统计信息索引定义原则: http://www.cnblogs.com/knowledgesea/p/3672099.html https://msdn.microsoft.com/zh-cn/library/ms188783.aspx