##论文复现
摘要内容
最终目的
基于生成对抗网络(GAN)及其相关原理,实现多轨时序音乐生成。
三种基于GAN框架的理论模型(详细见后)
- 混乱音乐家模型(the jamming model)
- 单一指挥家模型(the composer model)
- 混合模型(the hybrid model)
- 喂入与输出
- input:神经网络喂入 Lakh MIDI Dataset,该数据集包含了170000个以上的独立MIDI文件。
喂入共有两种可能:
1. 无人工输入,独立生成。1. 喂入一段人类制作的轨道作为先验条件,从中学习潜在的时间结构并依据此进行生成。- output:生成包含五个音轨(bass, drums, guitar, piano, strings)的音乐文件(pianoRoll or MIDI),其共有连续四个小节(bars)。
- 定量评估生成结果
每次计算四个轨道内目标矩阵和一个轨道间目标矩阵(评估指标),实现生成效果量化(详细见后)。
Human-AI
可传入由人类预先编辑好的音轨,经编码器进行特征提取,并依据特征生成剩下四个音轨(tracks)。
Github链接:https://salu133445.github.io/musegan
- 基本介绍
- 音乐的性质
该部分首先分析了一段音乐应有的性质与特性,并在此基础上分析合理的框架,以实现自动编曲。
- 性质一
音乐以时间流动为构造基础,一段音乐的结构具有层级,因此需要合理的层机制对应该结构。
- 性质二
音乐由多样的乐器(轨道)组成,且各轨道间互相作用影响,最终相互依赖地演奏出来。
- 性质三
单轨道内的音符常以和弦、琶音或是旋律的方式组合,且单音生成模型不能很好地生成复音音乐。
- 难点与简化
正因为音乐性质很难完全被模型化并实现,故前人对生成模型做出相应的简化,其中包括:
- 只生成单轨音乐
- 喂入一段按时间顺序的音符并生成复调音乐
- 将几个单轨旋律结合生成复调音乐
- 本文目标与实现方法
首先,为避免上述的简化,基于如下三点生成多轨复调音乐:
- 和声与旋律结构
- 某种时间结构
以bar为最小单元,以time step为最小单位时间,并基于CNN生成(CNN更适合平移不变关系)。
- 多轨道相互依赖性
共有三种解决方法(详细见后)。
1. 混乱音乐家模型(the jamming model):每个轨道都有独立的生成器并独立生成。
1. 单一指挥家模型(the composer model):所有轨道共享一个生成器。
1. 混合模型(the hybrid model):每个轨道在独立生成器和一个**轨道间共享的输入**的共同作用下生成音乐,该**输入**旨在指导各轨道之间相互协和。
之后,提出几个轨道间与轨道内评估指标,实现生成效果量化(摘要部分所述)(详细见后)。
- GAN生成对抗网络
本项目最终采用WGAN-GP模型作为其生成模型,对WGAN-GP的数学由来和原理简要分析请详见文章museGAN的数学原理https://www.yuque.com/sfzq/wbhaoz/elozh0。
简要地讲,GAN的根本模型即对抗学习,生成器与判别器互相博弈从而互相优化,使得生成器更好地生成类似真实数据分布的作品。但是,因为GAN模型所用的JS散度存在梯度消失的问题,故出现WGAN以弥补该不足。与此同时,WGAN出现的优化困难和梯度爆炸的问题,则进一步由WGAN-GP进行修缮,GP即梯度惩罚。
WGAN-GP的目标函数D为:
其中 。实验表明,该模型收敛速度更快,参数调整次数更少。
。实验表明,该模型收敛速度更快,参数调整次数更少。
- 项目模型
- 数据表示
使用多轨piano-roll形式表示。如下图,该形式是二值化的矩阵(0和1),1表示音符的存在。

M个轨道的piano-roll在一个小节内的张量形式为 ,其中R代表一小节的单位时间数(time steps),S代表参与的音符数。可见如果有T个小节,道理相同。
,其中R代表一小节的单位时间数(time steps),S代表参与的音符数。可见如果有T个小节,道理相同。
- 对多轨道相关性建模
- Jamming Model(混乱音乐家模型)
多个生成器独立地生成,每个生成器都有独自的随机输入向量 。
。
这些生成器G从不同的判别器D收到反向传播的监督信号。
- Composer Model(单一指挥家模型)
只有一个生成器G,生成多个轨道的piano-roll矩阵。
该模型只需要一个共享的随机向量z(该向量可以视为指挥家的“意图”)。
对应地,只有一个判别器D检验真假,且不论轨道数M多大,均只有一个生成器和判别器。
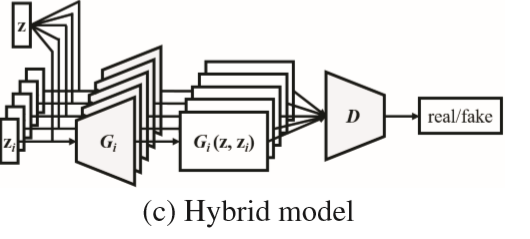
- Hybrid Model(混合模型)
将上面的两种模型进行结合。
一共M个生成器G,每个生成器接收一个轨道间共享的随机向量z和一个轨道内私有的随机向量 。
。
我们希望这个轨道间的共同向量z可以协调不同 (音乐家们)的生成,就如一个指挥家的指挥。
(音乐家们)的生成,就如一个指挥家的指挥。
更多地,只使用一个判别器D去共同地评估M个轨道(只判别最终效果与实际数据分布的差异)。
这样建模,使得喂入的随机向量既有共同依赖的分布(chords),也有独自不同的分布(styles)。
<br />注意,此时还没有讨论时序问题。
- 对时序结构建模
上面的模型只能一小节一小节生成多轨音乐片段,且各小节间几乎没有关联性。
因此,我们需要一个时间结构生成音乐,共有两种方法。
- 直接生成
该方法需要另一个单独的生成器G,该生成器视小节进行(bar progression)为另一独特的维度。
该生成器G由两个子网络组成,一个时序结构生成器 和一个小节生成器
和一个小节生成器 。
。
图中仅画出生成器部分。 负责将噪音向量z映射到一些互相有关联的向量序列
负责将噪音向量z映射到一些互相有关联的向量序列 。
。
这之后,带着时序信息的结果 将被喂入,以生成多小节的piano-rolls矩阵文件。
将被喂入,以生成多小节的piano-rolls矩阵文件。
最终有
- 人工喂入一个条件音轨
该方法假设一个特殊的小节时序 是由人类给定的,并且试着去学习这个特殊轨道的时序结构,之后生成剩余的轨道并完成作曲。
是由人类给定的,并且试着去学习这个特殊轨道的时序结构,之后生成剩余的轨道并完成作曲。

从图中可以看出,条件音轨生成器 通过
通过 生成多小节的piano-rolls。其中接收按时序的噪声向量z,和人类给定音轨y。
生成多小节的piano-rolls。其中接收按时序的噪声向量z,和人类给定音轨y。
y经分析得出的结果为 ,其中E表示编码器Encoder。这个额外的编码器将被训练把y映射到z空间上,以指导生成按时序的音乐小节。
,其中E表示编码器Encoder。这个额外的编码器将被训练把y映射到z空间上,以指导生成按时序的音乐小节。
最终有
需要注意的是,编码器E提取的对象应该是人工给定数据的轨道间特征而不是轨道内特征,因为轨道内特征对于生成其他轨道是没有用处的。
- MuseGAN架构
综上,MuseGAN是一个多轨道、按时序生成音乐模型的综合体和延伸体。
如下图,输入MuseGAN的z共由四个部分组成:
1. :轨道**间**的、**非时序**的随机向量
1. :轨道**内**的、**非时序**的几个随机向量
1. :轨道**间**的、**时序**的随机向量
1. :轨道**内**的、**时序**的几个随机向量
 对于所有轨道(tracks),共有的(指挥家)时序结构生成器和独自的时序结构生成器
对于所有轨道(tracks),共有的(指挥家)时序结构生成器和独自的时序结构生成器 将时序的随机向量
将时序的随机向量 和
和 分别作为各自的输入,分别输出一系列相关联的轨道内、轨道间的时序信息。
分别作为各自的输入,分别输出一系列相关联的轨道内、轨道间的时序信息。
之后,这些时序信息与非时序的随机向量 和
和 (更偏重于音高与音调而不是时间上的节奏)被连接在一起(信息整合),一起被喂入小节生成器,接着生成piano-rolls序列。
(更偏重于音高与音调而不是时间上的节奏)被连接在一起(信息整合),一起被喂入小节生成器,接着生成piano-rolls序列。
最终有
对于人工喂入一个条件音轨的情况,多出一个编码器E负责将给入音轨中有用的轨道间信息提取出来。
- 项目运行
- 数据集
采用LMD(Lakh MIDI dataset)进行训练。
- 数据处理过程
如下图所示。 首先,对于某些音轨只取少数音符,以增加数据稀疏性并加快学习过程,同时对它们进行相似乐器的多轨道融合,最终得到LPD-5-matched数据集。
首先,对于某些音轨只取少数音符,以增加数据稀疏性并加快学习过程,同时对它们进行相似乐器的多轨道融合,最终得到LPD-5-matched数据集。
接着,采用更好效果的piano-rolls,即4/4拍的摇滚歌曲,得到LPD-5-cleansed。
最后,对数据再进行算法上的修剪,以及去掉罕见的高音(C8以上)和低音(C1以下)。
- 模型设置
- 生成器G和判别器D都通过深度卷积神经网络实现(deepCNN)。
- 其中,G先从时序入手调整,再调整音高,而D反之。
- 所有输入的随机向量的长度为128。
- 判别器D每更新5次,更新一次生成器G。
- 最终一层使用tanh作为激活函数,初始值设为0。
- 用于评估结果的目标矩阵
为了评估模型结果,设计了四个轨道内目标矩阵和一个轨道间目标矩阵。
- EB:空小节所占比例
- UPC:每小节已用的音高数
- QN:符合要求的音符所占比例(qualified notes),即音符要长于三个time steps(三十二分音符)。QN反映了音乐的稀松程度。
- DP:鼓点模式,音符组的特定长度(8或16)的比例,形成鼓点。
- TD:音符间距离(tonal distance),它衡量了各轨道间的和谐程度,该指标较大往往效果更差。
通过比较真实数据与生成数据的这些指标的差别,我们可以定性衡量MuseGAN的表现。
- 对于训练数据的分析
首先对于训练数据应用这些目标矩阵并查看结果,从而更好地理解训练数据(只看表格第一行)。

如上两张表格的第一行即为对应结果,ablated作为对照组。
- EB:可以看出,将轨道分出5组是很合适的。
- UPC:该指标对应音高数,可以看出bass倾向于演奏一定的旋律(其值小于2.0),而guitar和piano等的值几乎大于3.0,说明它们更倾向于演奏和弦等等。
- QN:符合要求的音符所占比例很高,说明训练数据的音符紧实度很好。
- DP:超过88%的鼓点音符都是8或16节奏的。
- TD:对于偏向旋律的轨道和偏向和弦的轨道之间,TD值在1.50左右。而对于两个偏向和弦的轨道,TD值在1.00左右。值得注意的是,打乱训练数据会干扰到TD,说明该值确实与轨道间和谐度有关。
- 实验结果
 **
**
如上图为六个小节的piano-rolls生成结果。
- 目标分析
如上两张表格除去第一行以外即为实验结果,ablated因为没有batch normalization而作为对照组。
对于轨道内目标矩阵,我们发现整体上jamming model表现更佳,其原因可能在于该模型更专注于自己独立的轨道,即有独立的G。
- EB:jamming model的鼓点大幅密集,而composer model的整体音轨都相对密集。composer model和hybrid model的鼓点空小节数相对高。
- UPC:该指标对应音高数,可以看出bass倾向于演奏一定的旋律(其值小于2.0),而guitar和piano等的值几乎大于3.0,说明它们更倾向于演奏和弦等等。实验结果的UPC和QN整体低于训练数据的。
- QN:与对照组相比,三个模型符合要求的音符所占比例均更高,且jamming model的紧实度相对更高(个人认为此处取名qualified notes有不妥之处,该指标仅仅反映了生成音乐的稀松度,或者说是音符的完整程度)。然而QN显著低于训练数据,说明训练过程中产生了噪声和碎片化的音符(可能是因为将piano-rolls这种二值化的矩阵作为输出去取代连续变化的音乐音高所致的)。
- DP:表现良好,说明drums轨道确实捕获了训练数据的节奏信息。
- TD: 较于jamming model其他两组相对低,说明jamming model的和谐度不如其他两组,这与之前的分析是一致的。

若有收获,就点个赞吧
0 人点赞
