10月5日
- 关联知识领域:词向量NLP。
- 涉及的interesting的知识:deepWalk和node2vec算法等等。
- NRL网络表示学习:将音乐框架网络(节点图)通过一系列过程转变成一个多维向量。
- 目的:将复杂的网络信息结构化为多维特征,利于机器学习喂入。
- Node Embedding
- 学习属性的选择:表示方法的侧重,引发各类算法
- 规模化问题:大量的节点和边的规模化处理
- 向量维度问题:维度确定
- Encoder-Decoder模型
- Encoder:负责把每个node映射到低维向量中
- Decoder:负责从低维向量信息中重新构建网络结构和节点属性
- 节点关系函数
 :定量衡量节点间距离
:定量衡量节点间距离 - Encode函数ENC:将节点映射到一定维度d的向量上(embedding)
- Decode函数DEC:将向量化信息恢复为节点关系
- 损失函数
 :用于衡量模型刻画能力,比如
:用于衡量模型刻画能力,比如 和
和  的差距
的差距

该文章深入浅出解释了Embedding的意义及其作用,对生成方法进行了说明,指明了学习方向(知识名词)。
Embedding的理解.pdf
同样对Embedding进行了讲解(独热码的转化),并对其可视化TSNE说明。
10月9日
对于基础算法word2vec的理解。
在得到每个单词的向量表示后,我们需要思考下一个问题:比如在多数情况下,“香蕉”和“橘子”更加相似,而“香蕉”和“句子”就没有那么相似;同时,“香蕉”和“食物”、“水果”的相似程度可能介于“橘子”和“句子”之间。那么如何让存储的词向量具备这样的语义信息呢?
我们先学习自然语言处理领域的一个小技巧。在自然语言处理研究中,科研人员通常有一个共识:使用一个单词的上下文来了解这个单词的语义,比如:
“苹果手机质量不错,就是价格有点贵。” “这个苹果很好吃,非常脆。” “菠萝质量也还行,但是不如苹果支持的APP多。”
在上面的句子中,我们通过上下文可以推断出第一个“苹果”指的是苹果手机,第二个“苹果”指的是水果苹果,而第三个“菠萝”指的应该也是一个手机。事实上,在自然语言处理领域,使用上下文描述一个词语或者元素的语义是一个常见且有效的做法。我们可以使用同样的方式训练词向量,让这些词向量具备表示语义信息的能力。
2013年,Mikolov提出的经典word2vec算法就是通过上下文来学习语义信息。word2vec包含两个经典模型:CBOW(Continuous Bag-of-Words)和Skip-gram,如 图4 所示。
- CBOW:通过上下文的词向量推理中心词。
- Skip-gram:根据中心词推理上下文。
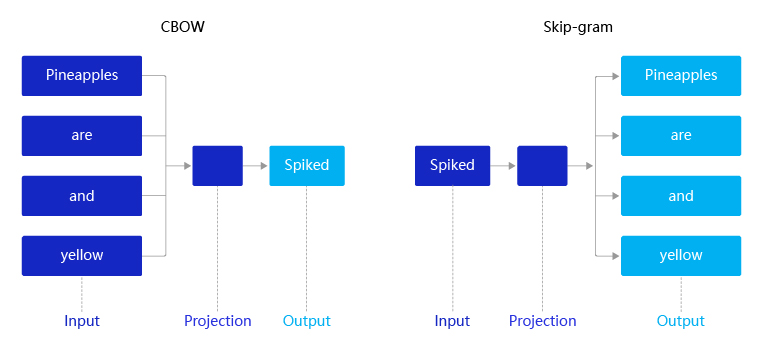
图4:CBOW和Skip-gram语义学习示意图
假设有一个句子“Pineapples are spiked and yellow”,两个模型的推理方式如下:
- 在CBOW中,先在句子中选定一个中心词,并把其它词作为这个中心词的上下文。如 图4 CBOW所示,把“spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。在学习过程中,使用上下文的词向量推理中心词,这样中心词的语义就被传递到上下文的词向量中,如“spiked → pineapple”,从而达到学习语义信息的目的。
- 在Skip-gram中,同样先选定一个中心词,并把其他词作为这个中心词的上下文。如 图4 Skip-gram所示,把“spiked”作为中心词,把“Pineapples、are、and、yellow”作为中心词的上下文。不同的是,在学习过程中,使用中心词的词向量去推理上下文,这样上下文定义的语义被传入中心词的表示中,如“pineapple → spiked”, 从而达到学习语义信息的目的。
说明:
一般来说,CBOW比Skip-gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文average的方式进行训练,每个训练step会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好,原因是skip-gram不会刻意回避生僻字。
CBOW和Skip-gram的算法实现
我们以这句话:“Pineapples are spiked and yellow”为例分别介绍CBOW和Skip-gram的算法实现。
如 图5 所示,CBOW是一个具有3层结构的神经网络,分别是: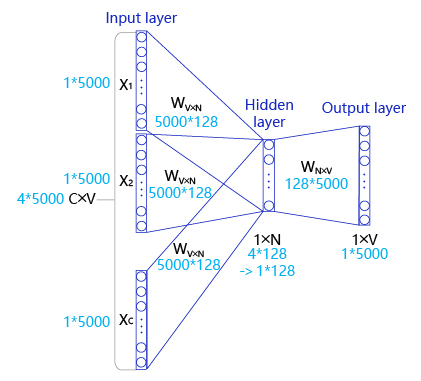
图5:CBOW的算法实现
- 输入层: 一个形状为C×V的one-hot张量,其中C代表上线文中词的个数,通常是一个偶数,我们假设为4;V表示词表大小,我们假设为5000,该张量的每一行都是一个上下文词的one-hot向量表示,比如“Pineapples, are, and, yellow”。
- 隐藏层: 一个形状为V×N的参数张量W1,一般称为word-embedding,N表示每个词的词向量长度,我们假设为128。输入张量和word embedding W1进行矩阵乘法,就会得到一个形状为C×N的张量。综合考虑上下文中所有词的信息去推理中心词,因此将上下文中C个词相加得一个1×N的向量,是整个上下文的一个隐含表示。
- 输出层: 创建另一个形状为N×V的参数张量,将隐藏层得到的1×N的向量乘以该N×V的参数张量,得到了一个形状为1×V的向量。最终,1×V的向量代表了使用上下文去推理中心词,每个候选词的打分,再经过softmax函数的归一化,即得到了对中心词的推理概率:

如 图6 所示,Skip-gram是一个具有3层结构的神经网络,分别是:
图6:Skip-gram算法实现
- Input Layer(输入层):接收一个one-hot张量 V∈R1×vocabsizeV \in R^{1 \times \text{vocab_size}}_V∈_R_1×vocab_size 作为网络的输入,里面存储着当前句子中心词的one-hot表示。
- Hidden Layer(隐藏层):将张量VVV乘以一个word embedding张量W1∈Rvocab_size×embed_sizeW_1 \in R^{\text{vocab_size} \times \text{embed_size}}_W_1∈_R_vocab_size×embed_size,并把结果作为隐藏层的输出,得到一个形状为R1×embed_sizeR^{1 \times \text{embed_size}}_R_1×embed_size的张量,里面存储着当前句子中心词的词向量。
- Output Layer(输出层):将隐藏层的结果乘以另一个word embedding张量W2∈Rembed_size×vocab_sizeW_2 \in R^{\text{embed_size} \times \text{vocab_size}}_W_2∈_R_embed_size×vocab_size,得到一个形状为R1×vocab_sizeR^{1 \times \text{vocab_size}}_R_1×vocab_size的张量。这个张量经过softmax变换后,就得到了使用当前中心词对上下文的预测结果。根据这个softmax的结果,我们就可以去训练词向量模型。
在实际操作中,使用一个滑动窗口(一般情况下,长度是奇数),从左到右开始扫描当前句子。每个扫描出来的片段被当成一个小句子,每个小句子中间的词被认为是中心词,其余的词被认为是这个中心词的上下文。
Skip-gram的理想实现
使用神经网络实现Skip-gram中,模型接收的输入应该有2个不同的tensor:
- 代表中心词的tensor:假设我们称之为centerwords VV_V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中,每个中心词的ID,对应位置为1,其余为0。
- 代表目标词的tensor:目标词是指需要推理出来的上下文词,假设我们称之为targetwords TT_T,一般来说,这个tensor是一个形状为[batch_size, 1]的整型tensor,这个tensor中的每个元素是一个[0, vocab_size-1]的值,代表目标词的ID。
在理想情况下,我们可以使用一个简单的方式实现skip-gram。即把需要推理的每个目标词都当成一个标签,把skip-gram当成一个大规模分类任务进行网络构建,过程如下:
- 声明一个形状为[vocabsize, embedding_size]的张量,作为需要学习的词向量,记为W0W_0_W_0。对于给定的输入VV_V,使用向量乘法,将VVV乘以W0W0_W_0,这样就得到了一个形状为[batch_size, embedding_size]的张量,记为H=V×W0H=V×W_0_H=V×W_0。这个张量HH_H就可以看成是经过词向量查表后的结果。
- 声明另外一个需要学习的参数W1W1_W_1,这个参数的形状为[embedding_size, vocab_size]。将上一步得到的HH_H去乘以W1W1_W_1,得到一个新的tensor O=H×W1O=H×W_1_O=H×W_1,此时的OO_O是一个形状为[batch_size, vocab_size]的tensor,表示当前这个mini-batch中的每个中心词预测出的目标词的概率。
- 使用softmax函数对mini-batch中每个中心词的预测结果做归一化,即可完成网络构建。
Skip-gram的实际实现
然而在实际情况中,vocabsize通常很大(几十万甚至几百万),导致W0W_0_W_0和W1W_1_W_1也会非常大。对于W0W_0_W_0而言,所参与的矩阵运算并不是通过一个矩阵乘法实现,而是通过指定ID,对参数W0W_0_W_0进行访存的方式获取。然而对W1W_1_W_1而言,仍要处理一个非常大的矩阵运算(计算过程非常缓慢,需要消耗大量的内存/显存)。为了缓解这个问题,通常采取负采样(negative_sampling)的方式来近似模拟多分类任务。此时新定义的W0W_0_W_0和W1W_1_W_1均为形状为[vocab_size, embedding_size]的张量。
假设有一个中心词cc_c和一个上下文词正样本tptp_t__p。在Skip-gram的理想实现里,需要最大化使用ccc推理tptp_t__p的概率。在使用softmax学习时,需要最大化tptp_t__p的推理概率,同时最小化其他词表中词的推理概率。之所以计算缓慢,是因为需要对词表中的所有词都计算一遍。然而我们还可以使用另一种方法,就是随机从词表中选择几个代表词,通过最小化这几个代表词的概率,去近似最小化整体的预测概率。比如,先指定一个中心词(如“人工”)和一个目标词正样本(如“智能”),再随机在词表中采样几个目标词负样本(如“日本”,“喝茶”等)。有了这些内容,我们的skip-gram模型就变成了一个二分类任务。对于目标词正样本,我们需要最大化它的预测概率;对于目标词负样本,我们需要最小化它的预测概率。通过这种方式,我们就可以完成计算加速。上述做法,我们称之为负采样。
在实现的过程中,通常会让模型接收3个tensor输入:
- 代表中心词的tensor:假设我们称之为centerwords VV_V,一般来说,这个tensor是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个中心词具体的ID。
- 代表目标词的tensor:假设我们称之为targetwords TT_T,一般来说,这个tensor同样是一个形状为[batch_size, vocab_size]的one-hot tensor,表示在一个mini-batch中每个目标词具体的ID。
- 代表目标词标签的tensor:假设我们称之为labels LLL,一般来说,这个tensor是一个形状为[batch_size, 1]的tensor,每个元素不是0就是1(0:负样本,1:正样本)。
模型训练过程如下:
- 用VVV去查询W0W0_W_0,用TT_T去查询W1W_1_W_1,分别得到两个形状为[batch_size, embedding_size]的tensor,记为H1H_1_H_1和H2H_2_H_2。
- 点乘这两个tensor,最终得到一个形状为[batchsize]的tensor O=[Oi=∑jH0[i,j]×H1[i,j]]i=1batch_sizeO = [O_i = \sum_j H_0[i,j] × H_1[i,j]]{i=1}^{batch_size}O=[O__i=∑j__H_0[_i,j]×H_1[_i,j]]i=1batch___size。
- 使用sigmoid函数作用在OOO上,将上述点乘的结果归一化为一个0-1的概率值,作为预测概率,根据标签信息LLL训练这个模型即可。
在结束模型训练之后,一般使用W0W_0_W_0作为最终要使用的词向量,可以用W0W_0_W_0提供的向量表示。通过向量点乘的方式,计算两个不同词之间的相似度。

若有收获,就点个赞吧
0 人点赞
