前言
JVM嘛,Java虚拟机,也就是一个虚拟的硬件机器,所以它的一切功能都是基于真实的硬件机器,可能做了一些灵活的应用.
所以学习JVM的内存模型前,需要先了解下计算机硬件是如何解决并发带来的数据一致性和乱序执行问题.
JVM的内存模型和计算机的内存模型是有一定的映射关系的,但很多定义并不相同.
内存模型
读取速度:CPU 远大于 内存 远大于 磁盘
这个远大于大概就是100倍+
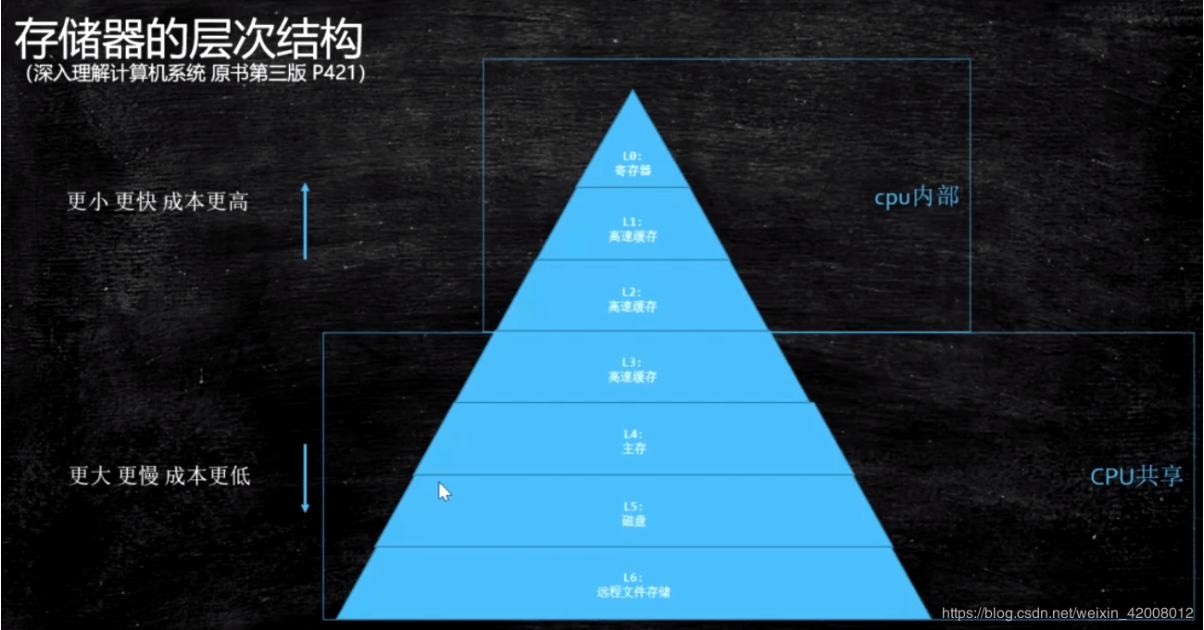
存储器的层次结构
这个金字塔,从最上层L0开始,越往下 速度越慢,成本越低,空间越大
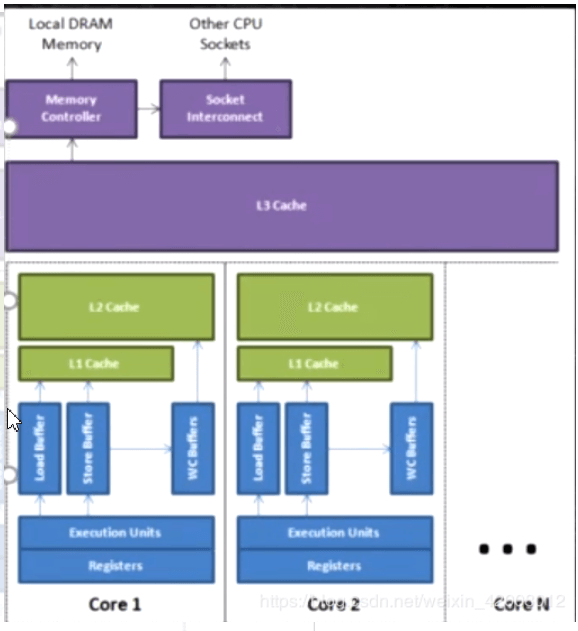
L0 L1 L2是CPU内部的缓存,每个CPU或者CPU的核心独享

数据一致性
上面看到L0 L1 L2是CPU内部的缓存
当两个CPU从L4或L3读取数据到自己的L2后,假如其中一个CPU修改了数据,就可能产生数据不一致的问题.
当然硬件的发明者不会这么傻,肯定有解决方案,那硬件是怎么保证数据一致性的呢?
总线锁
CPU去读主存或者其他层级的时候,是通过内存总线读的.
以前的CPU,为了保证数据一致性,会这么干:
CPU1访问变量t的时候,会锁住总线,这时候CPU2就不能访问变量t了,直到CPU1释放锁.
总线锁会锁住总线,使得其他CPU甚至不能访问内存中其他的地址,因而效率较低.
缓存锁+总线锁
各种缓存一致性协议
最常听的是intel的CPU的MESI协议,参考这个:https://www.cnblogs.com/z00377750/p/9180644.html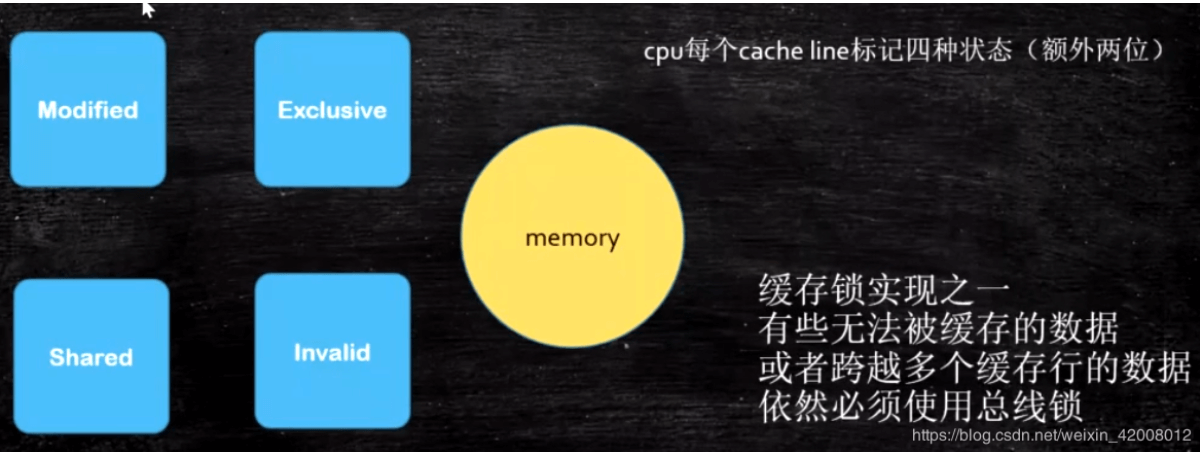
cache line 缓存行
cache line是读取缓存的基本单位
CPU去L3读取一个变量t时,假如t的数据很小,那么并不只是读取t自己,而是会带着t身边的一块数据,这个块成为”基本缓存单位”,即cache line缓存行,大小一般是64Bits
伪共享问题
假如CPU1需要读写变量t1,CPU2需要读写变量t2,而t1和t2在同一个缓存行中,这俩CPU就会产生不必要的互相影响,不必要的重新读取变量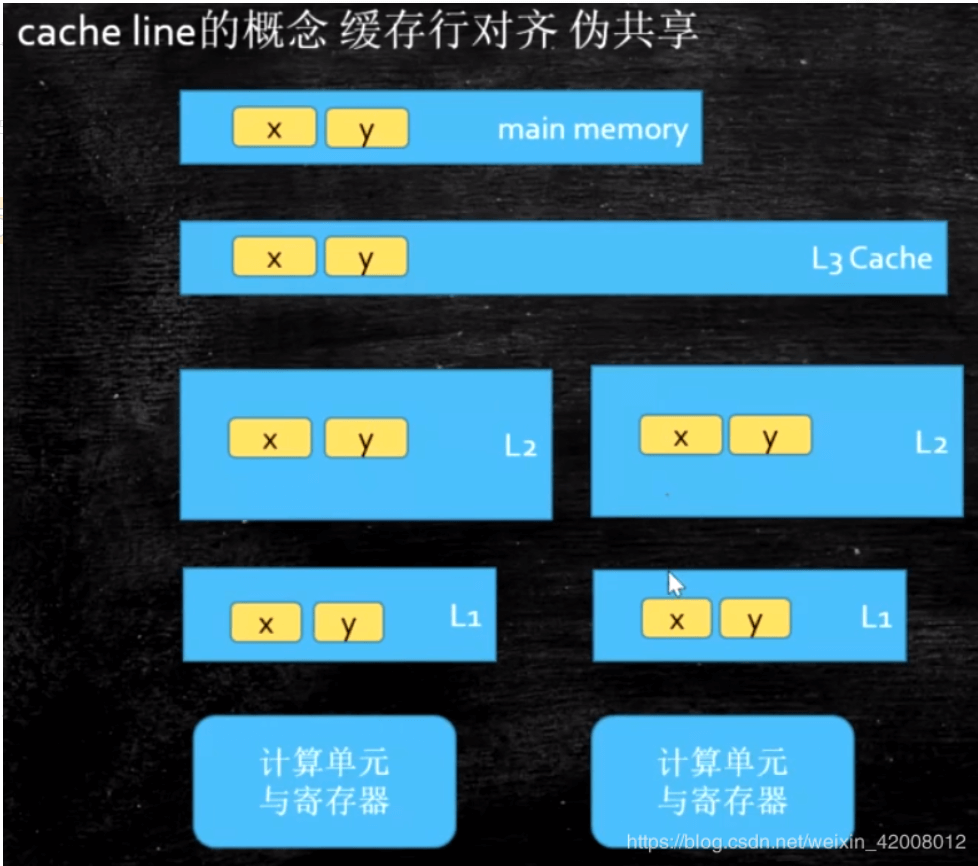
一些优秀的开源软件,代码中会规避掉缓存行的伪共享问题,比如Disruptor的cursor,就是前后各加了7个long变量,保证cursor变量一定是在独立的缓存行中,即缓存行对齐
下面我们来一对例子,验证一下伪共享:
反例:
static void originalMethod() throws InterruptedException {long[] arr = new long[2];Thread t1 = new Thread(() -> {for (int i = 0; i < TIMES; i++) {arr[0] = i;}});Thread t2 = new Thread(() -> {for (int i = 0; i < TIMES; i++) {arr[1] = i;}});long start = System.currentTimeMillis();t1.start();t2.start();t1.join();t2.join();long end = System.currentTimeMillis();System.out.println("originalMethod :" + (end - start));}
正例,就是多占一些内存,把使用的东西分成不同的缓存行:
这个实验结果,优化后快很多
// 这个类,就是只用到了num,其他的参数用来填充缓存行static class Param {long l1, l2, l3, l4, l5, l6, l7;long num;}static void optimizedMethod() throws InterruptedException {Param[] arr = {new Param(), new Param()};Thread t1 = new Thread(() -> {for (int i = 0; i < TIMES; i++) {arr[0].num = i;}});Thread t2 = new Thread(() -> {for (int i = 0; i < TIMES; i++) {arr[1].num = i;}});long start = System.currentTimeMillis();t1.start();t2.start();t1.join();t2.join();long end = System.currentTimeMillis();System.out.println("optimizedMethod :" + (end - start));}
乱序问题
CPU为了提高效率,可能会在一个慢指令执行的同时,指令另一条(无前后依赖关系的)指令,这就会打乱一些指令的顺序.
CPU读等待同时执行指令,这样CPU的执行就是乱序的
必须使用内存屏障(Memory Barrier)来做好指令排序
volatile的底层就是这么实现的.(Linux是Memory Barrier,Windows是lock指令)
CPU乱序执行的根源,参考 https://www.cnblogs.com/liushaodong/p/4777308.html
读的乱序执行
比如CPU要去读L3中的一个数据,这个读的速度对CPU来说很慢,它就判断如果下面的指令和这个数据没有直接关系,就可能同时去执行下面的指令.
生活中的例子就是下main这个泡茶的过程: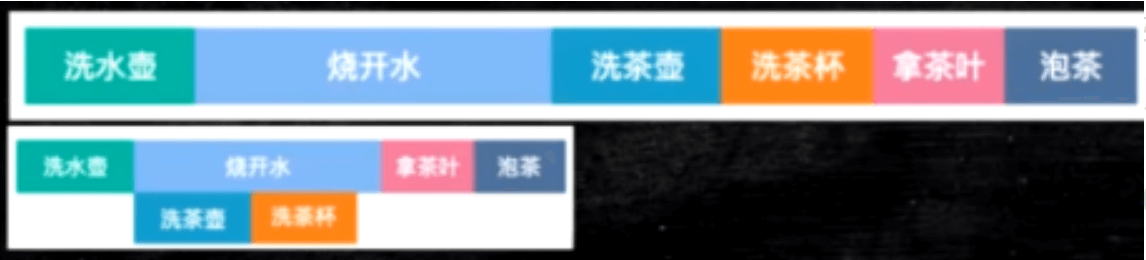
一个程序验证乱序确实存在:
需要执行很久,这里简单说一下逻辑:
如果一直都是顺序执行的,那么有以下这几种可能:
a=1;x=b;b=1;y=a —> x=0,y=1
a=1;b=1;x=b;y=a —> x=1,y=1
a=1;b=1;y=a;x=b —> x=1,y=1
b=1;y=a;a=1;x=b —> x=1,y=0
b=1;a=1;y=a;x=b —> x=1,y=1
b=1;a=1;x=b;y=a —> x=1,y=1
及无论如何都不会出现x=0,y=0的情况,如果出现了,那就是出现了乱序执行的情况,
即x=b发生在b=1之前,并且y=a发生在a=1之前
public class Disorder {private static int x = 0, y = 0;private static int a = 0, b =0;public static void main(String[] args) throws InterruptedException {int i = 0;for(;;) {i++;x = 0; y = 0;a = 0; b = 0;Thread one = new Thread(new Runnable() {public void run() {//由于线程one先启动,下面这句话让它等一等线程two. 读着可根据自己电脑的实际性能适当调整等待时间.shortWait(100000);a = 1;x = b;}});Thread other = new Thread(new Runnable() {public void run() {b = 1;y = a;}});one.start();other.start();one.join();other.join();String result = "第" + i + "次 (" + x + "," + y + ")";if(x == 0 && y == 0) {System.err.println(result);break;} else {//System.out.println(result);}}}public static void shortWait(long interval){long start = System.nanoTime();long end;do{end = System.nanoTime();}while(start + interval >= end);}}
有时候乱序会带来问题,如何保证顺序执行?
硬件内存屏障 X86
不同的CPU会有不同的实现,这里就以X86为例,稍微了解一下:
sfence: store| 在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
lfence:load | 在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
mfence:modify/mix | 在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
原子指令,如x86上的”lock …” 指令是一个Full Barrier,执行时会锁住内存子系统来确保执行顺序,甚至跨多个CPU。Software Locks通常使用了内存屏障或原子指令来实现变量可见性和保持程序顺序
JVM级别如何规范(JSR133)
LoadLoad屏障:
- 对于这样的语句Load1; LoadLoad; Load2,
- 在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:
- 对于这样的语句Store1; StoreStore; Store2,
- 在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:
- 对于这样的语句Load1; LoadStore; Store2,
- 在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:
- 对于这样的语句Store1; StoreLoad; Load2,
- 在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
合并写(WC)
提到乱序时,一般也会提到合并写,尽管合并写其实并不算是乱序执行,这里就简单了解一下.
WCBuffers: WriteCombiningBuffers,这个WCBuffers的个数依赖cpu模型,目前测试是和CPU的核数相等.
也就是CPU有几颗核心,那么WCBuffers一次就可以更新几个地址的数据
当cpu执行存储指令时,它会首先试图将数据写到离cpu最近的L1_cache, 如果此时cpu出现L1未命中,则会访问下一级缓存。速度上L1_cache基本能和cpu持平,其他的均明显低于cpu,L2_cache的速度大约比cpu慢20-30倍,而且还存在L2_cache不命中的情况,又需要更多的周期去主存读取。其实在L1_cache未命中以后,cpu就会使用一个另外的缓冲区,叫做合并写存储缓冲区(WCBuffers)。这一技术称为合并写入技术。
在请求L2_cache缓存行的所有权尚未完成时,cpu会把待写入的数据写入到合并写存储缓冲区.这个缓冲区允许cpu在写入或者读取该缓冲区数据的同时继续执行其他指令,这就缓解了cpu写数据时cache miss时的性能影响。
有些牛逼的程序员也会充分利用合并写,有个人,他搞了个Java程序模拟,我按照我的CPU稍微改了一点点:
感觉这个东西挺牛逼的就拿来试一试,但是这个也不稳定,也太局限于CPU了,想正确利用的话,得继续深挖CPU原理才行,我们其他地方还差的很多,先不纠结这么细节了…
public final class WriteCombining {private static final int ITERATIONS = Integer.MAX_VALUE;private static final int ITEMS = 1 << 24;private static final int MASK = ITEMS - 1;private static final byte[] array1 = new byte[ITEMS];private static final byte[] array2 = new byte[ITEMS];private static final byte[] array3 = new byte[ITEMS];private static final byte[] array4 = new byte[ITEMS];private static final byte[] array5 = new byte[ITEMS];private static final byte[] array6 = new byte[ITEMS];private static final byte[] array7 = new byte[ITEMS];private static final byte[] array8 = new byte[ITEMS];private static final byte[] array9 = new byte[ITEMS];private static final byte[] array10 = new byte[ITEMS];private static final byte[] array11 = new byte[ITEMS];private static final byte[] array12 = new byte[ITEMS];public static void main(final String[] args) {for (int i = 1; i <= 3; i++) {System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());}}public static long runCaseOne() {long start = System.nanoTime();int i = ITERATIONS;while (--i != 0) {int slot = i & MASK;byte b = (byte) i;array1[slot] = b;array2[slot] = b;array3[slot] = b;array4[slot] = b;array5[slot] = b;array6[slot] = b;array7[slot] = b;array8[slot] = b;array9[slot] = b;array10[slot] = b;array11[slot] = b;array12[slot] = b;}return System.nanoTime() - start;}public static long runCaseTwo() {long start = System.nanoTime();int i = ITERATIONS;while (--i != 0) {int slot = i & MASK;byte b = (byte) i;array1[slot] = b;array2[slot] = b;array3[slot] = b;array4[slot] = b;array5[slot] = b;array6[slot] = b;}i = ITERATIONS;while (--i != 0) {int slot = i & MASK;byte b = (byte) i;array7[slot] = b;array8[slot] = b;array9[slot] = b;array10[slot] = b;array11[slot] = b;array12[slot] = b;}return System.nanoTime() - start;}}
测试结果输出:(第三次之后就几乎一样了,估计又是什么奇怪的CPU机制,暂时不深究了,平时写程序也做不到这么细的优化…)
其实原理也很简单:
函数中连续写入12个不同位置的内存,那么当6个数据写满了合并写缓冲时,cpu就要等待合并写缓冲区更新到L2cache中,因此cpu就被强制暂停了。
然而每次写入6个不同位置的内存,可以很好的利用合并写缓冲区,因合并写缓冲区满到引起的cpu暂停的次数会大大减少,当然如果每次写入的内存位置数目小于6,也是一样的。

若有收获,就点个赞吧
0 人点赞
