认识JVM常用命令行参数
- JVM的命令行参数参考:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
- HotSpot参数分类
常用的查看参数的命令标准: - 开头,所有的HotSpot都支持非标准:-X 开头,特定版本HotSpot支持特定命令不稳定:-XX 开头,下个版本可能取消
java -version
java -X
java -XX:+PrintFlagsInitial 默认参数值
java -XX:+PrintFlagsFinal 最终参数值
java -XX:+PrintFlagsFinal -version |grep GC
java -XX:+PrintFlagsFinal | grep xxx 找到对应的参数
认识GC日志和相关参数
一个小程序观察GC日志
这里就是不断的产生不能回收的对象,观察GC
public class HelloGC {public static void main(String[] args) {System.out.println("hello gc~");List<byte[]> list = new LinkedList<>();for (; ; ) {list.add(new byte[1024 * 1024]);}}}
区分概念:内存泄漏memory leak,内存溢出out of memory
内存泄漏就是有一块内存,我们用不到 但是GC也无法回收,
内存溢出是分配内存时,发现内存不够用啦
这俩其实没啥必然的联系:
泄漏不一定导致溢出,内存总空间够大的话,浪费一点也不致命;
内存溢出不一定是由内存泄漏导致,内存总空间比较小,程序的对象又很多时,正常的使用也可能内存溢出
java -XX:+PrintCommandLineFlags -version
打印JAVA版本时打印出JVM的一些参数,也可以把-version换成执行的程序
会有些默认的JVM参数:
-XX:InitialHeapSize=267595520 -XX:MaxHeapSize=4281528320 -XX:+PrintCommandLineFlags -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC
-XX:+PrintGC 打印GC信息,<br />关于打印GC的参数还有:<br /> -XX:+PrintGCDetails 打印详细信息,这个下面详细看<br /> -XX:+PrintGCTimeStamps 时间戳<br /> -XX:+PrintGCCause 原因<br /> -Xmn 年轻代空间的最大值,-XX:MaxNewSize<br /> -Xms 堆空间的最小值,-XX:InitialHeapSize,即初始大小<br /> -Xmx 堆空间的最大值,-XX:MaxHeapSize<br /> 一般把Xms和Xmx设置成一样的大小,避免堆的扩容和缩容所带来的资源消耗<br />执行后输出:<br />GC就是Young GC,年轻代的GC
-XX:InitialHeapSize=41943040 -XX:MaxHeapSize=62914560 -XX:MaxNewSize=10485760 -XX:NewSize=10485760 -XX:+PrintCommandLineFlags -XX:+PrintGC -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGChello gc~[GC (Allocation Failure) 7289K->5888K(39936K), 0.0025545 secs][GC (Allocation Failure) 13212K->13072K(39936K), 0.0019146 secs][GC (Allocation Failure) 20554K->20160K(39936K), 0.0016964 secs][GC (Allocation Failure) 27481K->27392K(39936K), 0.0019578 secs][Full GC (Ergonomics) 27392K->27275K(54784K), 0.0088717 secs][GC (Allocation Failure) 34598K->34507K(54784K), 0.0018232 secs][GC (Allocation Failure) 41824K->41739K(53760K), 0.0022524 secs][Full GC (Ergonomics) 41739K->41611K(59392K), 0.0021946 secs][GC (Allocation Failure) 47889K->47851K(59904K), 0.0014204 secs][Full GC (Ergonomics) 47851K->47755K(59904K), 0.0021113 secs][Full GC (Ergonomics) 54027K->53900K(59904K), 0.0035498 secs][Full GC (Ergonomics) 57096K->56972K(59904K), 0.0024055 secs][Full GC (Allocation Failure) 56972K->56953K(59904K), 0.0069355 secs]Exception in thread “main” java.lang.OutOfMemoryError: Java heap spaceat com.mashibing.jvm.c5_gc.HelloGC.main(HelloGC.java:16)
java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags -XX:+PrintGC HelloGC
-XX:+UseConcMarkSweepGC 使用CMS,观察CMS的GC
日志会详细一些,打出来CMS的一些阶段
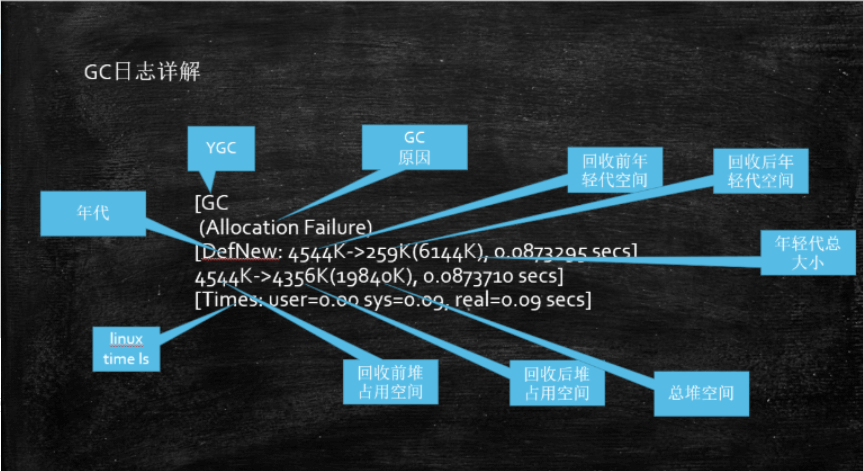
PS GC日志详解
每种垃圾回收器的日志格式是不同的!
PS日志格式(-XX:+PrintGCDetails)
-XX:InitialHeapSize=41943040 -XX:MaxHeapSize=62914560 -XX:MaxNewSize=10485760 -XX:NewSize=10485760 -XX:+PrintCommandLineFlags -XX:+PrintGC -XX:+PrintGCDetails -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGChello gc~[GC (Allocation Failure) [PSYoungGen: 7289K->840K(9216K)] 7289K->5968K(39936K), 0.0015575 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][GC (Allocation Failure) [PSYoungGen: 8164K->792K(9216K)] 13292K->13088K(39936K), 0.0019297 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][GC (Allocation Failure) [PSYoungGen: 8274K->696K(9216K)] 20570K->20160K(39936K), 0.0031077 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][GC (Allocation Failure) [PSYoungGen: 8016K->696K(9216K)] 27481K->27328K(39936K), 0.0032998 secs] [Times: user=0.02 sys=0.00, real=0.00 secs][Full GC (Ergonomics) [PSYoungGen: 696K->0K(9216K)] [ParOldGen: 26632K->27275K(45056K)] 27328K->27275K(54272K), [Metaspace: 3480K->3480K(1056768K)], 0.0083194 secs] [Times: user=0.00 sys=0.00, real=0.01 secs][GC (Allocation Failure) [PSYoungGen: 7323K->160K(9216K)] 34598K->34603K(54272K), 0.0016512 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][GC (Allocation Failure) [PSYoungGen: 7477K->128K(8192K)] 41920K->41739K(53248K), 0.0030788 secs] [Times: user=0.03 sys=0.00, real=0.00 secs][Full GC (Ergonomics) [PSYoungGen: 128K->0K(8192K)] [ParOldGen: 41611K->41611K(51200K)] 41739K->41611K(59392K), [Metaspace: 3480K->3480K(1056768K)], 0.0023069 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][GC (Allocation Failure) [PSYoungGen: 6278K->1152K(8704K)] 47889K->47883K(59904K), 0.0015485 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][Full GC (Ergonomics) [PSYoungGen: 1152K->0K(8704K)] [ParOldGen: 46731K->47755K(51200K)] 47883K->47755K(59904K), [Metaspace: 3480K->3480K(1056768K)], 0.0025861 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][Full GC (Ergonomics) [PSYoungGen: 6272K->3072K(8704K)] [ParOldGen: 47755K->50828K(51200K)] 54027K->53900K(59904K), [Metaspace: 3480K->3480K(1056768K)], 0.0021735 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][Full GC (Ergonomics) [PSYoungGen: 6268K->6144K(8704K)] [ParOldGen: 50828K->50828K(51200K)] 57096K->56972K(59904K), [Metaspace: 3480K->3480K(1056768K)], 0.0015226 secs] [Times: user=0.00 sys=0.00, real=0.00 secs][Full GC (Allocation Failure) [PSYoungGen: 6144K->6144K(8704K)] [ParOldGen: 50828K->50809K(51200K)] 56972K->56953K(59904K), [Metaspace: 3480K->3480K(1056768K)], 0.0094250 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]HeapPSYoungGen total 8704K, used 6393K [0x00000000ff600000, 0x0000000100000000, 0x0000000100000000)eden space 7168K, 89% used [0x00000000ff600000,0x00000000ffc3e4d0,0x00000000ffd00000)from space 1536K, 0% used [0x00000000ffd00000,0x00000000ffd00000,0x00000000ffe80000)to space 1536K, 0% used [0x00000000ffe80000,0x00000000ffe80000,0x0000000100000000)ParOldGen total 51200K, used 50809K [0x00000000fc400000, 0x00000000ff600000, 0x00000000ff600000)object space 51200K, 99% used [0x00000000fc400000,0x00000000ff59e630,0x00000000ff600000)Metaspace used 3512K, capacity 4502K, committed 4864K, reserved 1056768Kclass space used 391K, capacity 394K, committed 512K, reserved 1048576K
heap dump部分:
PSYoungGen(也有的是def new generation): 年轻代total = eden + 1个survivoreden space 5632K, 94% used [0x00000000ff980000,0x00000000ffeb3e28,0x00000000fff00000)后面的内存地址分别指的是,起始地址,使用空间结束地址,整体空间结束地址
Metaspace就是元数据区了,下面的class space时Metaspace中专门放class的空间
reserved 预留出来的空间大小
committed 内存是分块的,目前占用的块的大小
capacity 目前指定的容量
used 真正使用的大小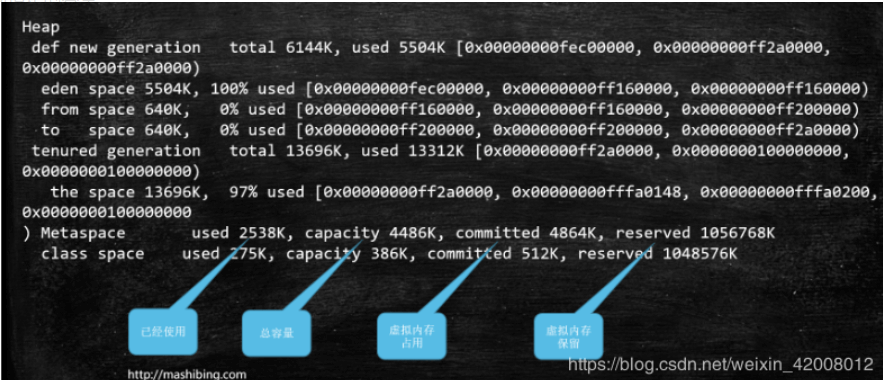
调优前的基础概念
衡量JVM-GC的两个指标
吞吐量throughput:用户代码执行时间 /(用户代码执行时间 + 垃圾回收时间),吞吐量越大,JVM花在GC上的时间越少
响应时间:STW越短,响应时间越好
这俩指标几乎是不可能兼得的,
想要更高的吞吐量,就是要GC总体占用更少的CPU时间,这样的话,一旦需要STW,会STW很久(典型代表:CMS);
想要更快的响应时间,就是要STW很短,需要有线程去不断的标记处理对象,但是这样的话,吞吐量势必会降低,因为GC占用更多的CPU时间了.
所谓调优,首先确定,追求啥?
吞吐量优先,还是响应时间优先?还是在满足一定的响应时间的情况下,要求达到多大的吞吐量等等
一般我们做web网站的,肯定是响应时间优先了.
科学计算/数据挖掘,吞吐量。吞吐量优先的一般选择PS + PO
响应时间:网站 GUI API (1.8 G1)
怎么调优?
- 根据需求进行JVM规划和预调优
- 优化JVM运行环境(慢,卡顿,一般是GC的STW过长了)
- 排查定位JVM运行过程中出现的各种问题(CPU 内存使用过高告警,OOM)
第三条其实分的不是特别开,规划的时候要考虑JVM运行环境,
生产中想要去优化JVM运行环境,需要先排查问题
实际中还是要根据业务,配合压测分析日志,逐步调整
其实说白了,就是要根据大量的案例,找到经验,去做一些规划和堆内存的调整,然后线上出问题了定位并解决问题.
根据需求进行JVM规划
调优,从业务场景开始,没有业务场景的调优都是耍流氓
无监控(压力测试,能看到结果),不调优
步骤:
熟悉业务场景,选择优化的维度
(没有最好的垃圾回收器,只有最合适的垃圾回收器)
响应时间、停顿时间 [CMS G1 ZGC] (需要给用户作响应)
吞吐量 = 用户时间 /( 用户时间 + GC时间) [PS]选择回收器组合
- 计算内存需求(经验值,不一定是越大越好, 有的从1.5G升到16G甚至还慢了很多)
- 选定CPU(越高越好)
- 设定年代大小、升级年龄
设定日志参数
-Xloggc:/opt/xxx/logs/xxx-xxx-gc-%t.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 - XX:GCLogFileSize=20M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCCause<br />最多保留5个GC日志文件,每个文件最大20M,超过5个时最新的文件会把最老的覆盖掉<br />或者每天产生一个日志文件
观察日志情况
案例1:垂直电商,最高每日百万订单,处理订单系统需要什么样的服务器配置?
其实很多不同的服务器配置都能支撑(1.5G 16G),只是GC的次数影响吞吐量和响应时间这里我们要找到最高峰的TPS,在最高峰TPS时,能够满足多少的响应时间假设每天的高峰期在的1小时内产生36W订单,平均100个订单/秒或者通过日志或者数据库发现,最顶峰是 1000个订单/秒找到高峰期后,其实还是根据经验值,然后压测,因为还跟CPU算力有关非要计算:一个订单产生需要多少内存?512K * 1000 500M内存重要的还是要靠压测!
案例2:12306遭遇春节大规模抢票应该如何支撑?(架构问题)
12306应该是中国并发量最大的秒杀网站:号称并发量100W最高CDN -> LVS -> NGINX -> 业务系统 -> 每台机器1W并发(10K问题) 100台机器普通电商订单 -> 下单 ->订单系统(IO)减库存 ->等待用户付款12306的一种可能的模型: 下单 -> 减库存 和 订单(redis kafka) 同时异步进行 ->等付款减库存最后还会把压力压到一台服务器可以做分布式本地库存 + 单独服务器做库存均衡大流量的处理方法:分而治之
怎么得到一个事务会消耗多少内存?
用压测来确定实际中一般是弄台机器,看能承受多少TPS?是不是达到目标?扩容或调优,让它达到目标即可
优化JVM运行环境
说白了就是选用合适的GC,这个现代的内存越来越便宜了,建议扩内存,上G1
调整各个分代区域(年轻代,老年代)的空间,这个要根据实际业务,压测结果分析日志了.
有一个50万PV的资料类网站(从磁盘提取文档到内存)原服务器32位,1.5G的堆,用户反馈网站比较缓慢,因此公司决定升级,新的服务器为64位,16G的堆内存,结果用户反馈卡顿十分严重,反而比以前效率更低了
1.1 为什么原网站慢?<br /> 很多用户浏览数据,很多数据load到内存,内存不足,频繁GC,STW长,响应时间变慢<br /> 1.2 为什么会更卡顿?<br /> 内存越大,FGC时间越长<br /> 1.3 咋办?<br /> 换个垃圾回收器<br /> PS -> PN + CMS 或者 G1
系统CPU经常100%,如何定位问题?(面试高频)
CPU100%那么一定有线程在占用系统资源,
2.1 找出哪个进程cpu高(top)
2.2 该进程中的哪个线程cpu高(top -Hp)
看看是 工作线程占比高 还是 垃圾回收线程占比高
2.3 导出该线程的堆栈 (jstack)
2.4 查找哪个方法(栈帧)消耗时间 (jstack)系统内存飙高,如何查找问题?(面试高频)
3.1 导出堆内存 (jmap)<br /> 3.2 分析 (jhat jvisualvm mat jprofiler … )
如何监控JVM
jstat jvisualvm jprofiler arthas top…
通过一个简单案例,掌握如何定位JVM运行中的问题
通过一个案例理解常用工具
测试代码:
启动加JVM参数: -Xms200M -Xmx200M -XX:+PrintGC
java -Xms200M -Xmx200M -XX:+PrintGC com.mashibing.jvm.gc.T15_FullGC_Problem01
package com.mashibing.jvm.gc;import java.math.BigDecimal;import java.util.ArrayList;import java.util.Date;import java.util.List;import java.util.concurrent.ScheduledThreadPoolExecutor;import java.util.concurrent.ThreadPoolExecutor;import java.util.concurrent.TimeUnit;/*** 从数据库中读取信用数据,套用模型,并把结果进行记录和传输*/public class T15_FullGC_Problem01 {private static class CardInfo {BigDecimal price = new BigDecimal(0.0);String name = "张三";int age = 5;Date birthdate = new Date();public void m() {}}private static ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(50,new ThreadPoolExecutor.DiscardOldestPolicy());public static void main(String[] args) throws Exception {executor.setMaximumPoolSize(50);for (;;){modelFit();Thread.sleep(100);}}private static void modelFit(){List<CardInfo> taskList = getAllCardInfo();taskList.forEach(info -> {// do somethingexecutor.scheduleWithFixedDelay(() -> {//do sth with infoinfo.m();}, 2, 3, TimeUnit.SECONDS);});}private static List<CardInfo> getAllCardInfo(){List<CardInfo> taskList = new ArrayList<>();for (int i = 0; i < 100; i++) {CardInfo ci = new CardInfo();taskList.add(ci);}return taskList;}}
这段代码是有问题的,生产中我们也很可能遇到各种问题,大概流程是这样:
一般是运维团队首先受到报警信息(CPU Memory)
top命令找到问题进程
发现有个进程 内存不断增长 CPU占用率居高不下
记住这个进程ID
这个问题进程其实就是我们的JAVA进程
观察进程中的线程(top -Hp)(jstack)
代码中的线程名称一定要写的有意义,不然出了问题很难定位这也是为什么阿里规范里规定,线程的名称(尤其是线程池)都要写有意义的名称,通过自定义ThreadFactory实现
top -Hp 进程ID,观察进程中的线程,哪个线程CPU和内存占比高
jstack JAVA进程ID,定位线程状况,重点关注:WAITING BLOCKED(死锁)
eg.
waiting on <0x0000000088ca3310> (a java.lang.Object)
假如有一个进程中100个线程,很多线程都在waiting on ,一定要找到是哪个线程持有这把锁
怎么找?搜索jstack dump的信息,找 ,看哪个线程持有这把锁RUNNABLE
1:写一个死锁程序,用jstack观察2:写一个程序,一个线程持有锁不释放,其他线程等待,用jstack观察
观察JAVA进程的JVM信息
jinfo pid ,查看version,classpath和启动参数等
观察gc情况
jstat -gc 动态观察gc情况 / 阅读GC日志发现频繁GC / arthas观察 / jconsole/jvisualVM/ Jprofiler(最好用,但是收费)
jstat -gc 4655 500 : 每个500个毫秒打印GC的情况(4655是进程id)
怎么定位OOM问题的?生产中不能直接用图形界面,影响性能
1:已经上线的系统不用图形界面用什么?(cmdline,arthas)
2:图形界面到底用在什么地方?测试!测试的时候进行监控!(压测观察)
查找最多的前xx个实例对象的类
jmap - histo 4655 | head -20
jmap -dump:format=b,file=xxx pid (这个要注意!!)
线上系统,内存特别大,jmap执行期间会对进程产生很大影响,甚至卡顿(电商不适合)
1:设定了参数HeapDump,OOM的时候会自动产生堆转储文件
java -Xms20M -Xmx20M -XX:+UseParallelGC -XX:+HeapDumpOnOutOfMemoryError com.mashibing.jvm.gc.T15_FullGC_Problem01
2:很多服务器备份(高可用),停掉这台服务器对其他服务器不影响
3:在线定位(一般小点儿公司用不到)
使用MAT / jhat /jvisualvm 进行dump文件分析
https://www.cnblogs.com/baihuitestsoftware/articles/6406271.html
jhat -J-mx512M xxx.dump
浏览器直接访问 http://ip:7000 操作
拉到最后:找到对应链接
可以使用OQL查找特定问题对象
图形界面观察gc情况
jconsole远程连接
程序启动加入参数:
java -Djava.rmi.server.hostname=192.168.17.11 -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.port=11111 -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false XXX
如果遭遇 Local host name unknown:XXX的错误,修改/etc/hosts文件,把XXX加入进去
192.168.17.11 basic localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
关闭linux防火墙(实战中应该打开对应端口)
service iptables stopchkconfig iptables off #永久关闭
windows上打开 jconsole远程连接 192.168.17.11:11111
jvisualvm远程连接
jprofiler (收费)
arthas在线排查工具
为什么需要在线排查?
在生产上我们经常会碰到一些不好排查的问题,例如线程安全问题,用最简单的threaddump或者heapdump不好查到问题原因。为了排查这些问题,有时我们会临时加一些日志,比如在一些关键的函数里打印出入参,然后重新打包发布,如果打了日志还是没找到问题,继续加日志,重新打包发布。对于上线流程复杂而且审核比较严的公司,从改代码到上线需要层层的流转,会大大影响问题排查的进度。
java -jar arthas.jar 启动arthas,然后找到对应的Java进程,进入后可输入help查看帮助命令
- jvm观察jvm信息
- thread定位线程问题
- dashboard 观察系统情况
- heapdump + jhat分析
jad反编译
动态代理生成类的问题定位
第三方的类(观察代码)
版本问题(确定自己最新提交的版本是不是被使用)redefine 热替换
目前有些限制条件:只能改方法实现(方法已经运行完成),不能改方法名, 不能改属性
m() -> mm()
sc - search class
watch - watch method
没有包含的功能:jmap (jmap - histo 4655 | head -20)

若有收获,就点个赞吧
0 人点赞
