索引基本知识
索引的优点
- 大大减少了服务器需要扫描的数据量
- 帮助服务器避免排序和临时表
- 将随机io变成顺序io
索引的用处
- 快速查找匹配WHERE子句的行
- 从consideration中消除行,如果可以在多个索引之间进行选择,mysql通常会使用找到最少行的索引
- 如果表具有多列索引,则优化器可以使用索引的任何最左前缀来查找行
- 当有表连接的时候,从其他表检索行数据
- 查找特定索引列的min或max值
- 如果排序或分组时在可用索引的最左前缀上完成的,则对表进行排序和分组
- 在某些情况下,可以优化查询以检索值而无需查询数据行
索引的分类
- 主键索引
主键唯一且非空,相当于数据库帮忙创建的特殊的唯一索引
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须且只有一个聚集索引:
- 如果表定义了主键,则PK就是聚集索引;
- 如果表没有定义主键,则第一个非空唯一索引(not NULL unique)列是聚集索引;
- 否则,InnoDB会创建一个隐藏的row-id作为聚集索引;(这个row-id是6位的,所以尽量我们指定主键)
唯一索引
普通索引
全文索引
fulltext,一般用在varchar,text上,用的较少
- 组合索引
对于一些经常需要组合查询的条件列,就可以把多个列组合起来共同创建一个所以哦那
面试技术名词
回表
https://www.zhihu.com/question/347087093/answer/830934717
MySQL innodb的主键索引是簇集索引,也就是索引的叶子节点存的是整个单条记录的所有字段值
不是主键索引的就是非簇集索引,非簇集索引的叶子节点存的是主键字段的值。需要取其他列时,要根据主键再去查主键的B+树.
回表是什么意思?就是你执行一条sql语句,需要从两个b+索引中去取数据。
索引覆盖(or覆盖索引)
回表需要查询两次B+树,IO次数就比较多;
如果建立的普通索引/组合索引,我们查询的时候只需要查询该索引(或者主键),不需要查询其他列,就不需要回表了,这就是索引覆盖.
常见于组合索引
最左匹配
建立组合索引后,比如对三个列name,age和sex 建立了组合索引 index_name_age_sex
那么where name=? and age=? and sex=?时肯定可以用到索引
where name=? 或者 where where name=? and age=?时也可以用到索引 (使用多个where条件时,顺序无所谓,MySQL会帮我们优化调整成最左匹配的顺序)
如果达不到最左匹配,比如where age=?,则不会使用该组合索引
那怎么办?
可以把组合索引调整一下顺序,改成 index_age_name_sex;
或者给age单独建立一个索引
如果需要在为name和age单独创建索引中 二选一,那么我会选择age;因为age占用磁盘空间更少,减少磁盘IO.
索引下推
(谓词下推?)
查询sql的过滤条件,比如where name=? and age=?
老版本的MySQL,server第一步会先根据name条件从存储引擎中取出数据,第二步在server层根据age筛选;
索引下推是说,在组合索引中,高版本MySQL会优化一下,会把第二步合并到第一步,在查询数据时就根据name和age筛选,减少了IO量.
索引合并
低版本的MySQL没有这说法,一次查询只能用一个索引
高版本中,优化器会帮我们做组合,但是效率不一定高
索引页分裂 页合并
to be continued…
索引采用的数据结构
MyISAM和InnoDB 都是是B+树;枝干上不存数据,叶子节点存数据
说来话长,下面单独拿出来写
索引匹配方式
create table staffs(id int primary key auto_increment,name varchar(24) not null default '' comment '姓名',age int not null default 0 comment '年龄',pos varchar(20) not null default '' comment '职位',add_time timestamp not null default current_timestamp comment '入职时间') charset utf8 comment '员工记录表';-----------alter table staffs add index idx_nap(name, age, pos);
全值匹配
全值匹配指的是和索引中的所有列进行匹配
explain select * from staffs where name = ‘July’ and age = ‘23’ and pos = ‘dev’;
匹配最左前缀
只匹配前面的几列
explain select from staffs where name = ‘July’ and age = ‘23’;
explain select from staffs where name = ‘July’;
匹配列前缀
可以匹配某一列的值的开头部分
explain select from staffs where name like ‘J%’;
explain select from staffs where name like ‘%y’;
匹配范围值
可以查找某一个范围的数据
explain select * from staffs where name > ‘Mary’;
精确匹配某一列并范围匹配另外一列
可以查询第一列的全部和第二列的部分
explain select * from staffs where name = ‘July’ and age > 25;
只访问索引的查询
查询的时候只需要访问索引,不需要访问数据行,本质上就是覆盖索引
explain select name,age,pos from staffs where name = ‘July’ and age = 25 and pos = ‘dev’;
索引的数据结构
MySQL官网虽然说的B-Tree,但其实是B+树,也许国外没有把他俩区分的这么开.
如果我们自己设计索引,怎么设计?
数据存储在磁盘文件中,我们想定位一组数据,首先要知道存储文件的路径,还要知道该数据在文件的偏移量offset(cursor,seek)
即我们设计索引的话,要记录下数据对应的 1.文件的路径;2.偏移量
想记录这俩东西,需要用啥数据结构?
hash,二叉树,红黑树,B树,B+树,为啥MySQL的InnoDB选择了B+树?
- hash表?
hash表只适合进行”等值”判断,我们经常会需要范围查找;
同时hash表也需要把数据都加载到内存才能加快查询效果,消耗内存比较大;
其实memory存储引擎,使用的索引的数据结构就是hash
- 叉树?
(一般说到二叉树,指的都是普通二叉树,或者更多的是说二叉搜索树)
可能数据倾斜,树的深度过深,极端情况下变成链表,每一个节点都需要一次IO,从而造成IO次数变多,影响数据
读取的效率
- 平衡树(AVL树,仨人名字首字母)?
AVL要求最短子树和最长子树的高度差 不能超过1
高度差超过1时,平衡树会通过左旋/右旋自我平衡,避免二叉树的数据倾斜问题,
但是也因为这个旋转,每次插入数据时,会进行很多次(1~N)旋转,旋转比较消耗资源
所以平衡树的插入/删除效率很低,查询效率较高
- 红黑树(RBT)?
红黑树算是AVL树的一个变种,要求最长子树高度 不超过最短子树高度的两倍
通过旋转+变色,把插入和查找的性能,去了一个均衡
无论是二叉树,AVL树,还是红黑树,每个节点都最多有俩子节点,最终都可能因为树的高度很大,造成IO次数增
加,所以也不太合适.
- B树
让每个节点的分叉多一些,
MySQL读取文件时,磁盘预读,InnoDB默认读取16Kb(4页)的数据
B树每个节点可以存储16Kb数据,每个节点会存储key值,指针,和数据
数据会占用很大的空间,所以三层的B树支撑不了太多的数据
- B+树
在B树的基础上,做了优化:
data只存储于叶子节点;枝干节点上不存data
三层的B+树,基本上可以支撑千万级别的数据
子节点会有一些key值的重复,不过这个数据量很小,可以接受
InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位的row_id来作为主键;
如果是非主键索引,那么在叶子节点中存储的是该记录的主键(和该索引自己),如果查询其他列数据 就需要通过主键索引找到对应的记录,叫做回表;
主键索引的叶子节点中存储的是整行数据,不需要回表.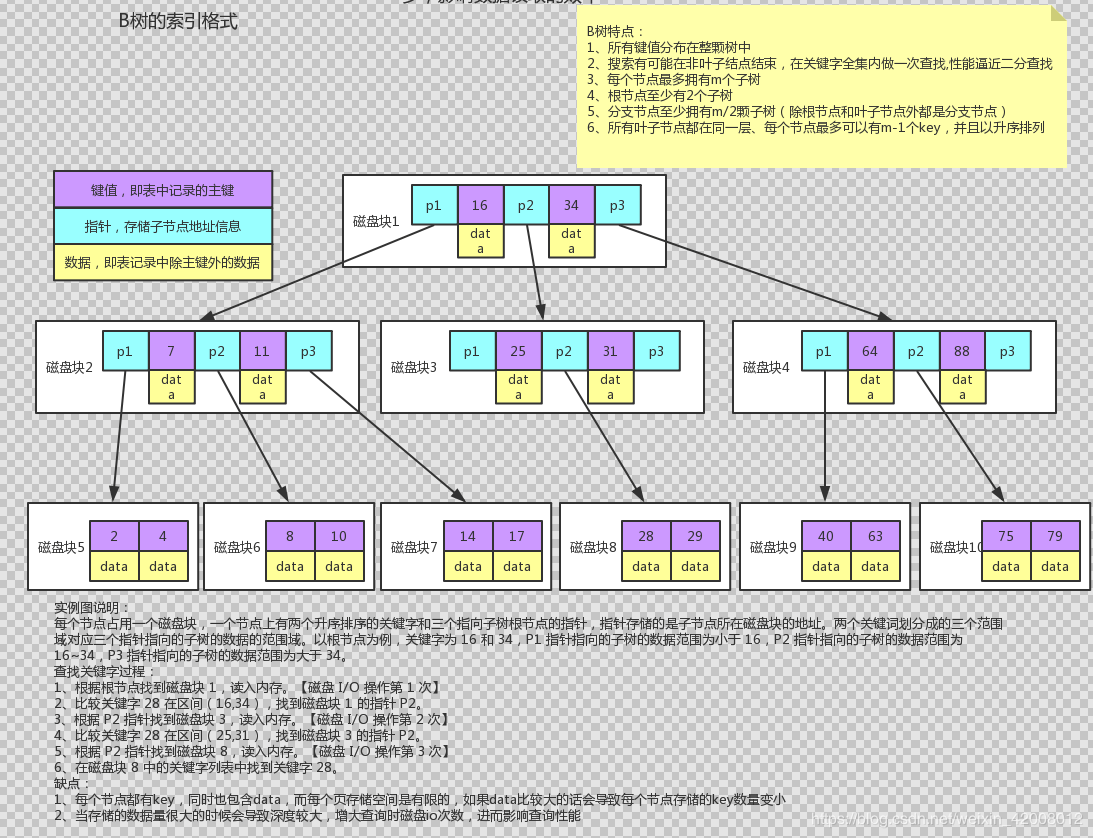
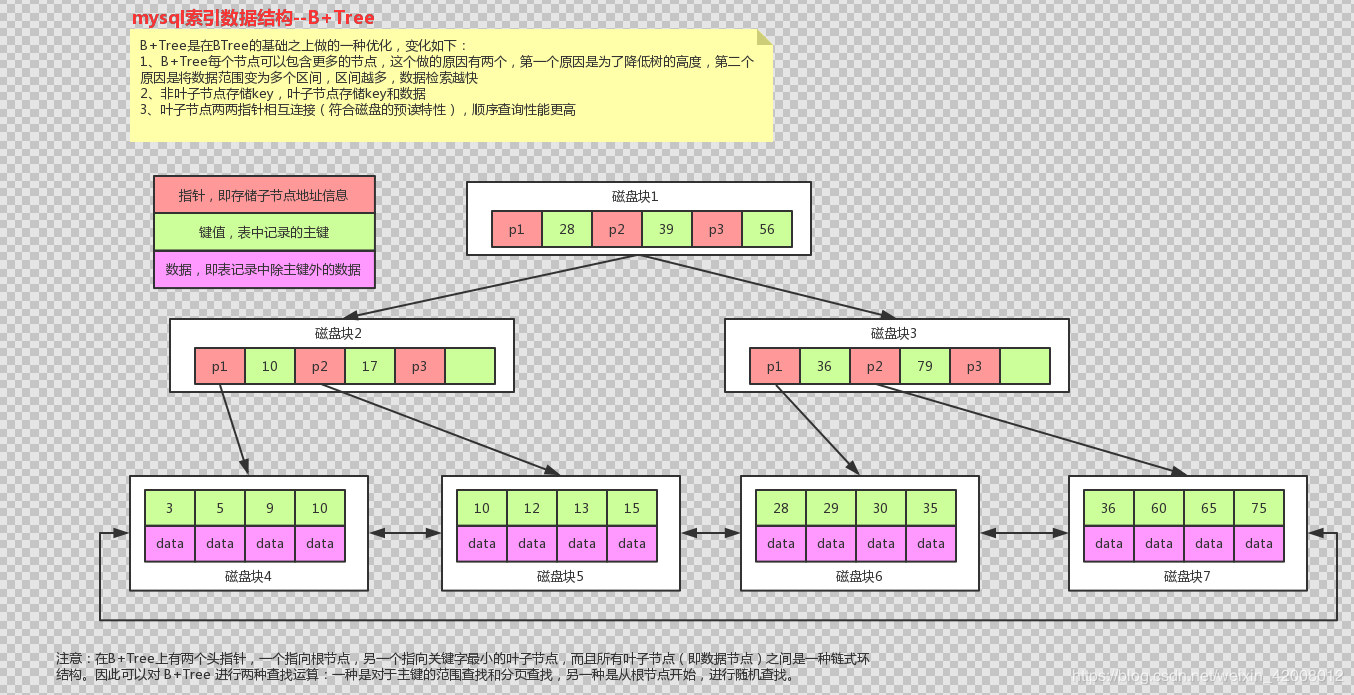
MyISAM 和 InnoDB 虽然都是使用B+树,但他们格式是不一样的MyISAM 会把数据和索引分开存储;InnoDB会把他们放一起MyISAM 的节点中的data,存储的是真正数据的地址,根据这个地址去对应的MYD文件里面找数据InnoDB节点中的data就是真实的数据行

若有收获,就点个赞吧
0 人点赞
