KubeSphere 平台概览
创建你的第一个 “Kubernetes 应用”
👩💻👨💻 登陆私有云 KubeSphere 平台,进入
drillground项目。
创建并访问 Nginx 服务
💡 Nginx: Homepage, Docker Hub


从“应用负载”的“服务”面板中,开始“创建”服务,并选择“无状态服务”

在“基本信息”中填写“名称”,“下一步” 👇
 **
**
进入“容器镜像”设置环节,选择“添加容器镜像”
 **
**
在“容器设置”中设置“镜像”为
nginx:1.17-alpine,并通过 “👉使用默认端口” 来设置容器的访问“端口”及其“协议”并确认 ☑️
🍮 镜像拉取策略(Image Pull Policy)
Always:不管本地镜像是否存在都会去仓库进行一次镜像拉取。校验如果镜像有变化则会覆盖本地镜像,否则不会覆盖。Never:只是用本地镜像,不会去仓库拉取镜像,如果本地镜像不存在则 Pod 运行失败。IfNotPresent:只有本地镜像不存在时,才会去仓库拉取镜像。- 镜像拉取策略默认为
IfNotPresent,但:latest标签的镜像默认为Always; - 拉取镜像时 Docker 会进行校验,如果镜像中的 MD5 码没有变,则不会拉取镜像数据;
- 生产环境中应该尽量避免使用
:latest标签,而开发环境中可以借助:latest标签自动拉取最新的镜像。
:::
- 镜像拉取策略默认为

返回到“容器镜像”设置,可查看到已配置完成了
nginx:1.17-alpine的容器镜像,即可执行 “下一步” 👇

暂时不需要配置“挂载存储”,进入“高级设置”并配置“外网访问”为
**NodePort**,然后执行 “创建” 服务
🍮 服务访问的几种主要类型
ClusterIP:默认类型,自动分配一个仅 Kubernetes 集群内部可以访问的虚拟 IP;NodePort:在 ClusterIP 基础上为服务在每台机器上绑定一个端口,这样就可以通过<NodeIP>:NodePort来访问该服务;LoadBalancer:在 NodePort 的基础上,借助云服务供应商创建一个外部的负载均衡器,并将请求转发到<NodeIP>:NodePort。
:::
进入到“工作负载”面板,当得到如上 👆界面状态
my-nginx 运行中 (1/1)即表示应用部署成功

返回到“服务”面板,可查看到 Nginx 服务到外网访问端口(⚠️ 注意该端口默认是随机产生的,但也可按规则指定)
 **
**
进入服务“资源状态”,在右侧面板上也可以更清晰的看到“容器端口”-“服务端口”-“节点端口”(外网端口)的映射关系
🎯 在 Kubernetes 集群内通过服务名访问服务
- 完整的服务名格式是:
<svc-name>.<ns-name>.svc.cluster.local,但通常不需要写完整; - 对于相同 Namespace 下的服务访问可只保留
<svc-name>部分,即直接使用my-nginx; - 对于不同 Namespace 访问服务需要至少保留
<svc-name>.<ns-name>的部分,即使用my-nginx.drillground。 :::

在内网访问 http://10.0.162.5:31917 即可得到如上 Nginx 默认起始页面。
访问容器日志和终端

从“应用负载”的“容器组”面板中,选择(进入)刚刚创建的
my-nginx容器组
 **
**
进入容器组后,在右侧“容器”面板中可以通过容器名右侧的两个图标分别查看“容器日志”和访问“终端”
 **
**
在“终端”中是可以如同本地终端一样对容器内的系统进行操作的
定制启动命令和环境变量
💡 Dockerfile Reference:
[CMD](https://devdocs.io/docker~19/engine/reference/builder/index#cmd),ENV

从“应用负载”的“工作负载”面板中,选择(进入)刚刚创建的
my-nginx工作负载
 **
**
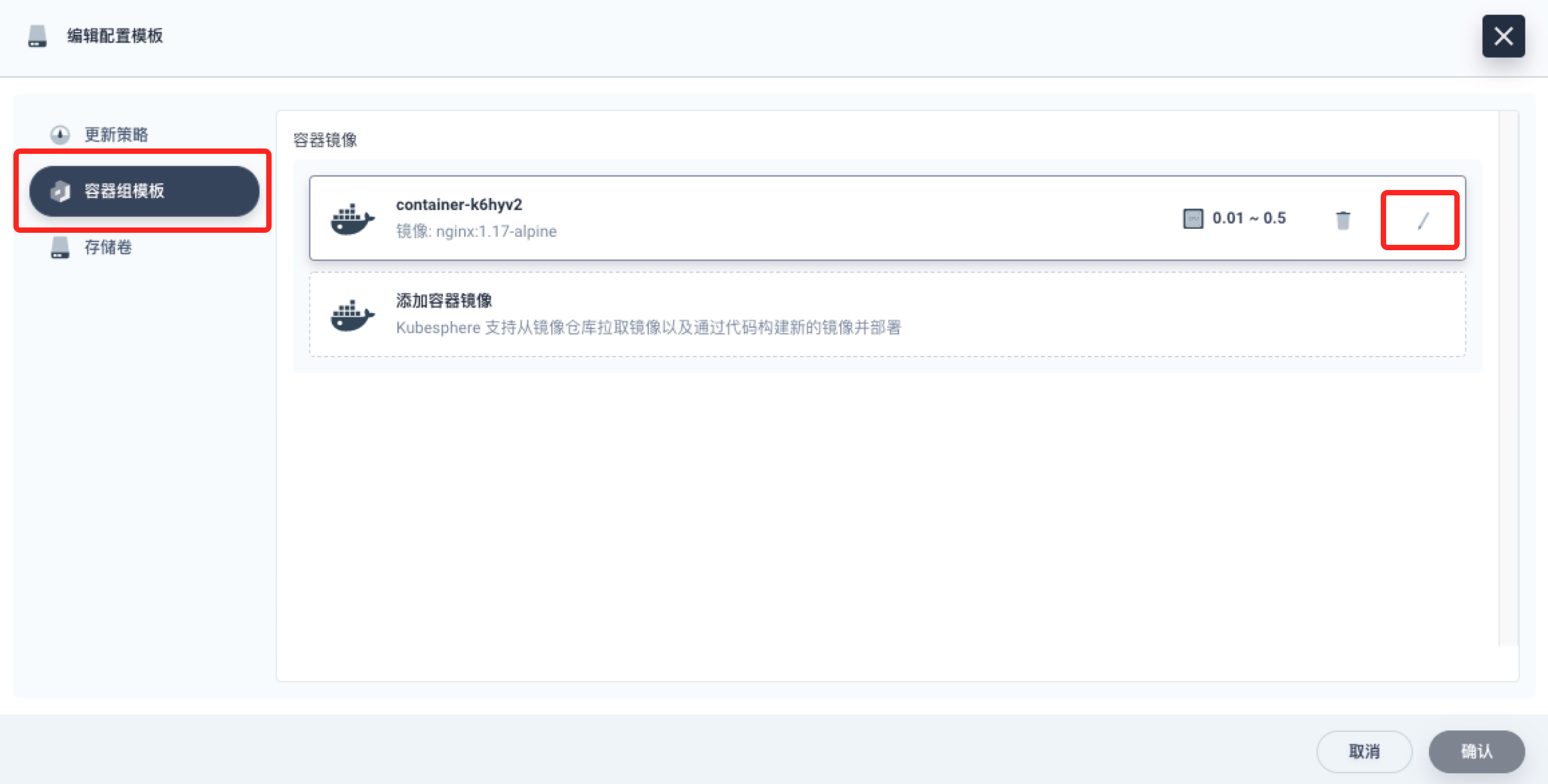
从左侧操作面板的“更多操作”中选择“编辑配置模版”
 **
**
选择“容器组模版”,在右侧“容器镜像”面板选择 Nginx 所在容器通过最右侧的编辑按钮进入容器编辑
 **
**
在“编辑容器”面板中,通过开启“启动命令”和“环境变量”面板可以对这两项内容进行编辑,编辑完成保存后将新更新部署
配置应用部署的更新策略
💡 Kubernetes Documentation: Perform Rolling Update Using a Replication Controller
在使用 KubeSphere 创建各类部署时,默认推荐的更新策略便是“滚动更新”(另一项为“替换更新”),同时也支持随时进行策略的变更和配置。
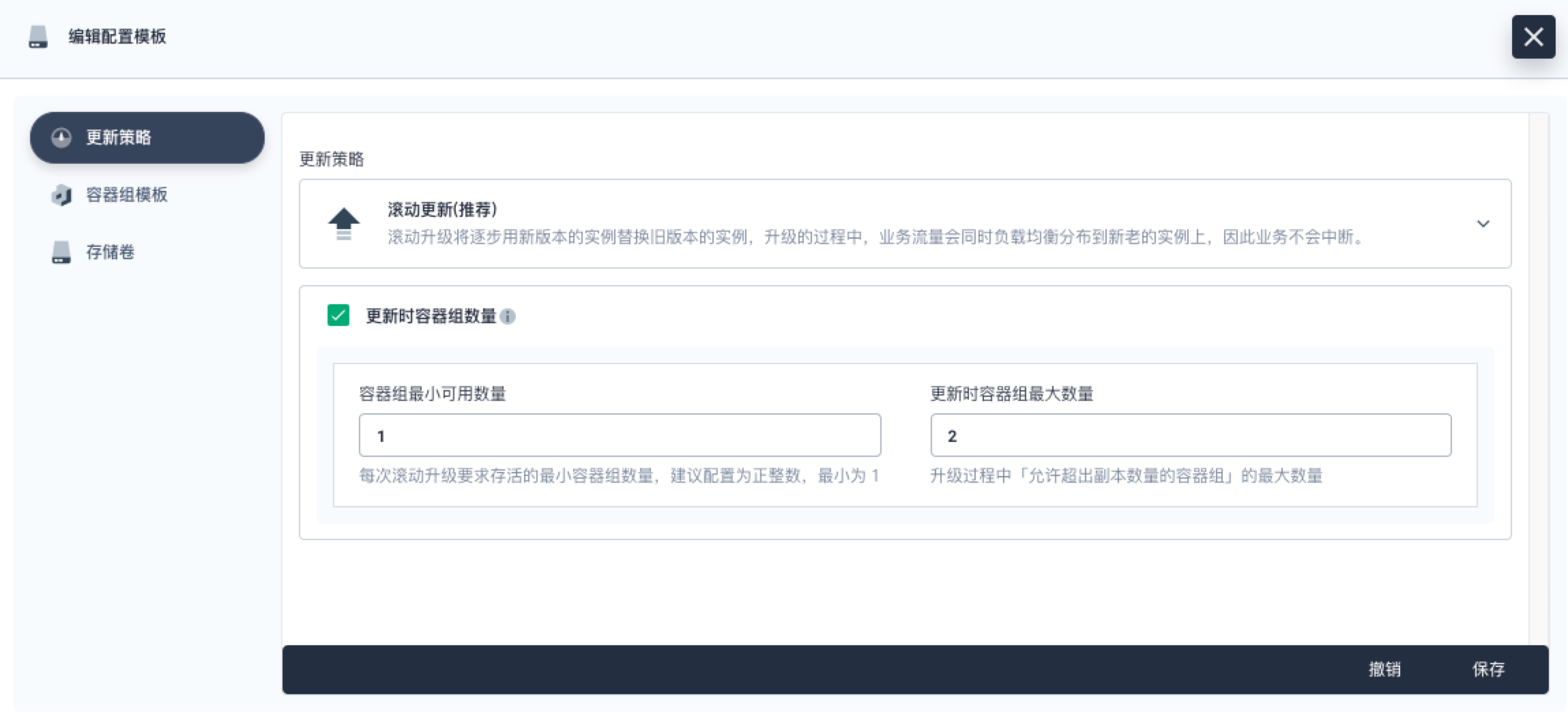
“更新策略”的配置入口与“容器组模版”在同一层,如果选择“滚动更新”,可额外配置容器组更新时“最少存活的 Pod 数量”和“允许超出副本数的 Pod 数量”
🍮 滚动更新(Rolling Update)的两个配置项
**maxUnavailable**:用来指定在升级过程中不可用 Pod 的最大数量。该值可以是一个正整数,或者是百分比(例如 10%,通过计算百分比的绝对值向下取整)- Max Surge 为 0 时,这个值不可以为 0。默认值是 1。
- 上图中的 “容器组最小可用数量” 实际对应生成的数值为 25%,通过向下取整得到 0,故表示不能存在不可用的容器组(即最小存活 1 个容器组)
**maxSurge**:用来指定可以超过期望的 Pod 数量的最大个数。该值可以是一个正整数,或者是百分比(例如 10%,通过百分比计算的绝对值向上取整)- Max Unavailable 为 0 时该值不可以为 0。默认值是 1。 :::
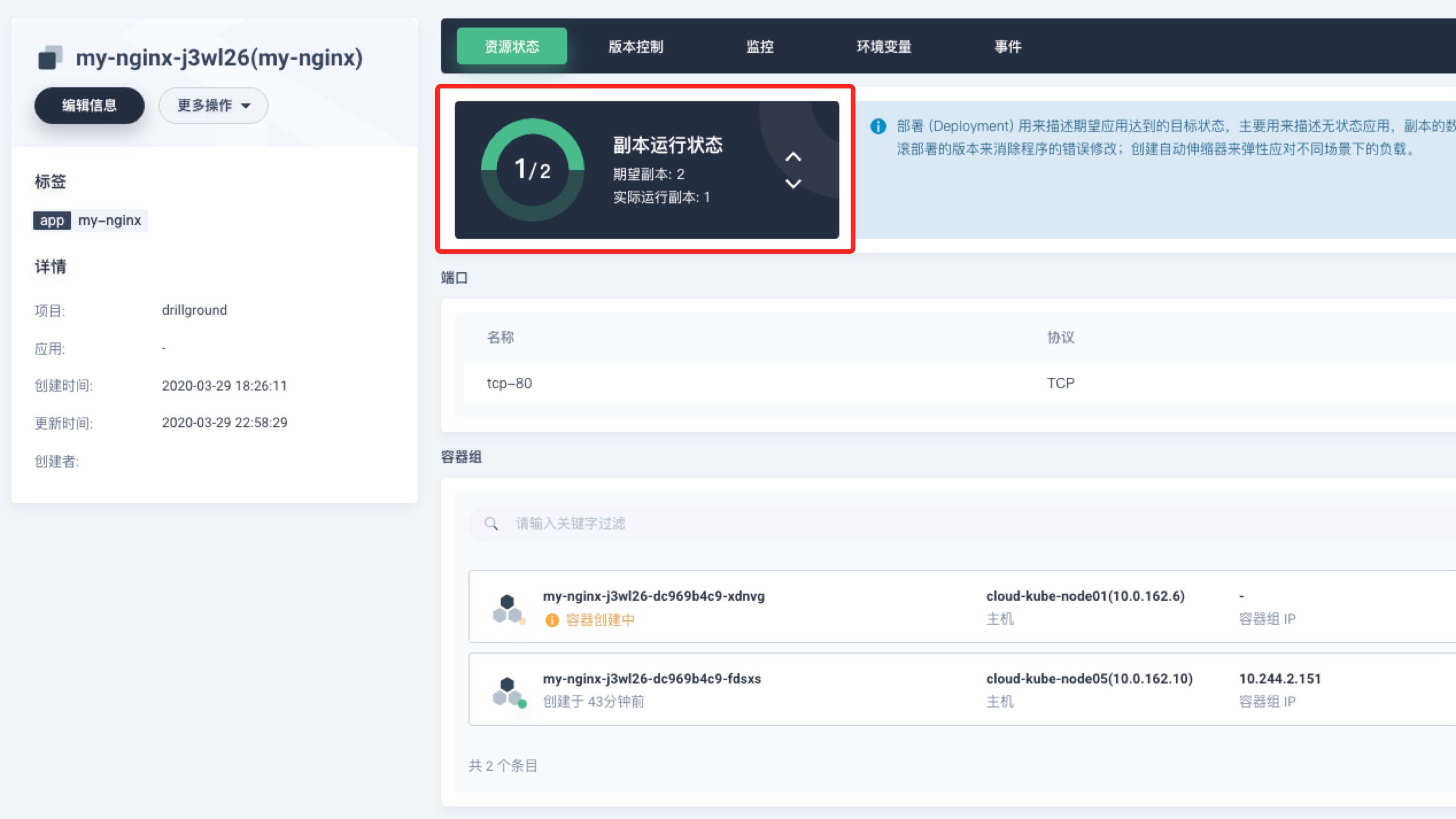
在部署面板中,可以非常方便的增加或减少部署副本的数量,基于以上“滚动更新”的配置,会至少保证有“容器组最小可用数量”个存活的容器组在滚动更新的过程中工作以保障服务可用
 **
**
每个应用部署已执行过的更新都可以被记录下来,并通过进入 “版本控制” 标签页选择进行相应的更新条目进行版本回退
为应用添加健康检查器
💡 Kubernetes Documentation: Configure Liveness, Readiness and Startup Probes
为了确保容器在部署后确实处在正常运行状态,Kubernetes 提供了三种探针(Probe)来探测容器的状态:
- Liveness Probe:探测应用是否处于健康状态,如果不健康则删除并重新创建容器
- Readiness Probe:探测应用是否启动完成并且处于正常服务状态,如果不正常则不会接收来自 Kubernetes Service 的流量(即将该 Pod 从 Service 的 Endpoint 中移除)
- Startup Probe:探测应用是否启动完成,如果设定了此探针,则前两项探针只有在启动探测成功后才生效;且成功后,即刻转由 Liveness Probe 接替健康状态探测
- 启动探针主要适用的场景:应用启动时间非常长,但启动后的健康检测间隔不长(常见于冷启动、自带大量数据需初始化的业务服务场景)
🍮 探针(Probe)的三种执行方式
**exec**:在容器中执行一个命令,如果 命令退出码 返回0则表示探测成功,否则表示失败**tcpSocket**:对指定的容器 IP 及端口执行一个 TCP 检查,如果端口是开放的则表示探测成功,否则表示失败**httpGet**:对指定的容器 IP、端口及路径执行一个 HTTP 的 GET 请求,如果返回的 状态码 在[200,400)之间则表示探测成功,否则表示失败
:::

参考 定制启动命令和环境变量 部分的操作进入“编辑容器”面板,打开“健康检查器”配置
配置并使用“存活”探测器

此处选用“TCP 端口检查”的方式作为“存活探测器”的探针形态,并绑定探测的端口为
80,其它皆使用默认配置并确认 ☑️

保存配置后,容器组会执行滚动更新以使“存活探测器”生效
 **
**
通过进入“终端”修改 Nginx 监听的端口使
80端口不生效,“存活探测器”会基于“不健康阈值”配置在 3 次探测失败后重启容器组,该过程可以在容器组“事件”标签页中观察到
配置并使用“就绪”探测器

类似地,选择“HTTP 请求检查”的方式作为“容器就绪检查”的探针形态,绑定
GET :80/作为探针入口,且设置“初始延迟”为 10 秒(服务就绪通常需要更多时间)

保存配置后,容器组仍然会执行滚动更新以使“就绪探测器”生效
 **
**
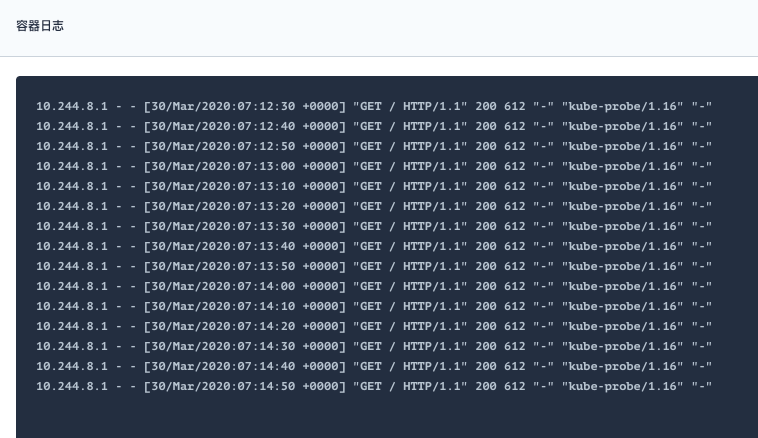
配置了基于“HTTP 请求检查”后可以在“容器日志”里面很清楚的看到探针的请求正在按检测配置执行
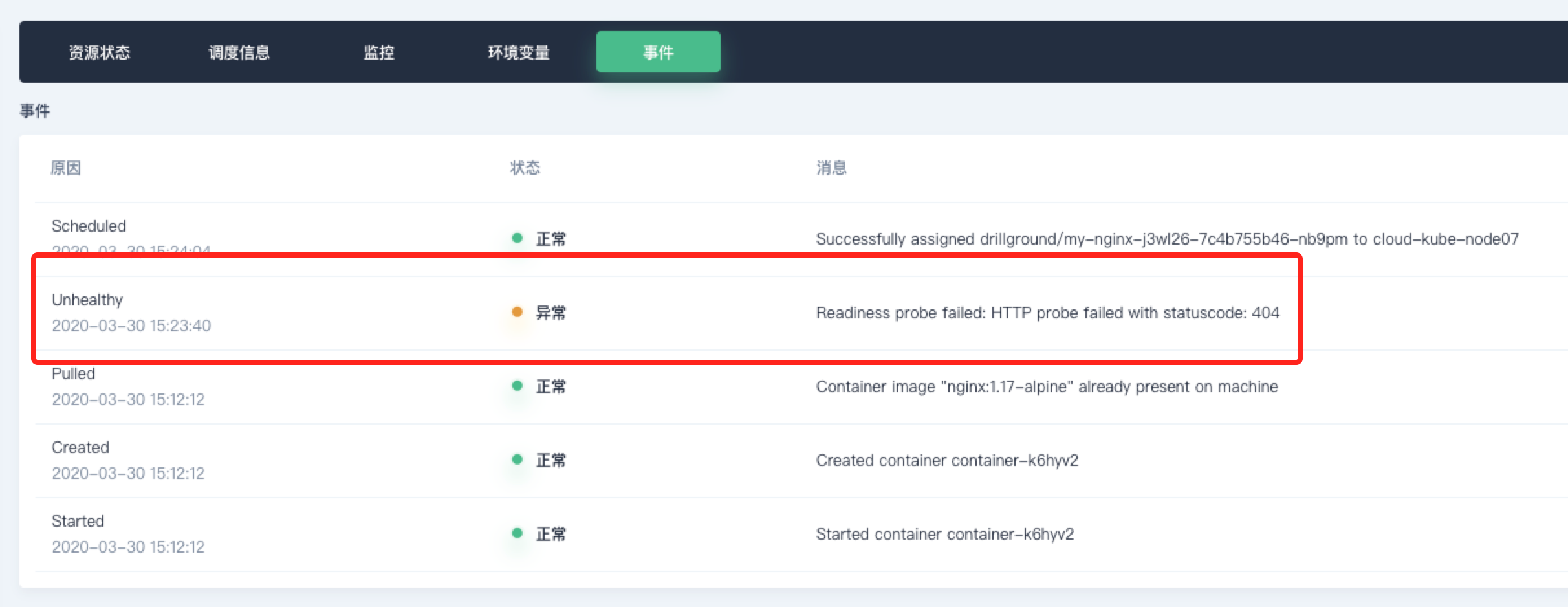
通过进入“终端”修改 Nginx 使
80端口直接返回**404**,“就绪探测器”会基于“不健康阈值”配置在 3 次探测失败后把容器组标记为不健康,该过程可以在容器组“事件”标签页中观察到
 **
**
在部署面板中,也可以看到容器组被“就绪探测器”被标记为“容器没有准备就绪”(⚠️ 就绪检测是吧是不会导致容器组重启的)

若有收获,就点个赞吧
0 人点赞
