RDD(Resilient Distributed Datasets)是Spark的 核心数据结构,本身不包含数据,只包含数据计算需要的方法和属性。所有数据计算操作均基于该结构进行,包括Spark sql 、Spark Streaming。理解RDD有助于了解分布式计算引擎的基本架构,更好地使用Spark进行批处理与流计算。
1. RDD算子简介
RDD本质上是Spark中的一个 抽象类,所有 子RDD(HadoopRDD、MapPartitionRDD、JdbcRDD等)都要继承并实现其中的方法。
abstract class RDD[T: ClassTag](@transient private var _sc: SparkContext,@transient private var deps: Seq[Dependency[_]]) extends Serializable with Logging { ... }
RDD包含的成员属性和方法:
- compute方法:提供在计算过程中Partition元素的获取和计算方式
- partition的列表:每一个partition代表一个并行的最小划分单元
- partitioner方法:定义如何对数据进行分区。spark内部定义了 HashPartitioner、RangePartitioner 等,用户也可以自定义分区器。如果没有特别指定的话,默认使用 HashPartitioner
- dependencies列表:描述RDD依赖那些父RDD生成,即RDD的血缘关系。包含 OneToOneDependency、ShuffleDependency 以及 RangeDependency。为 DAGScheduler 的任务划分及任务执行时寻找依赖的数据提供依据。
- partition的位置列表:定义如何最快速的获取partition的数据,加快计算,这个是可选的,可作为本地化计算的优化选项
- 持久化方法:persist、cache、checkpoint。cache方法底层调用了persist方法,并且二者默认存储级别都是 MEMORY_ONLY
- 重定义分区方法:repartition、coalesce。repartition 底层调用了 coalesce 方法,并且一定发生 shuffle,而 coalesce 则不进行shuffle 操作
- 转换算子:每次操作都会生成一个新的RDD算子,属于抽象类RDD的子RDD
- 行动算子:行动算子会执行 sc.runJob() 方法,从最后一个RDD开始向上进行深度优先遍历,进行Spark任务的触发执行
2. RDD的生成方式
- 并行化Scala集合
Partition的默认值:defaultParallelism
defaultParallelism与spark的部署模式相关:
- Local 模式:本机cpu cores的数量
- Mesos 模式:8
- Yarn 模式:max(2, 所有 executors 的 cpu cores 个数总和)
- 物理数据载入:HDFS、文本、JDBC数据源、Hbase等
Partition的默认值:min(defaultParallelism, 2)
- JDBC数据源可以指定分区数
- HDFS默认分区数等于文件块的个数,可以自定义分区数,但是不能小于HDFS的文件块数(默认大小128M)
- 其他RDD转换得到
3. RDD计算流程
以 词频统计 为例。=> 转换操作为 窄依赖(一对一关系),聚合操作为 宽依赖(多对一关系)。
val context = new SparkContext(conf)val data: RDD[String] = context.textFile("name.csv")val ds: RDD[String] = data.flatMap(_.split(","))val value: RDD[(String, Int)] = ds.map((_, 1))val res: RDD[(String, Int)] = value.reduceByKey(_+_)
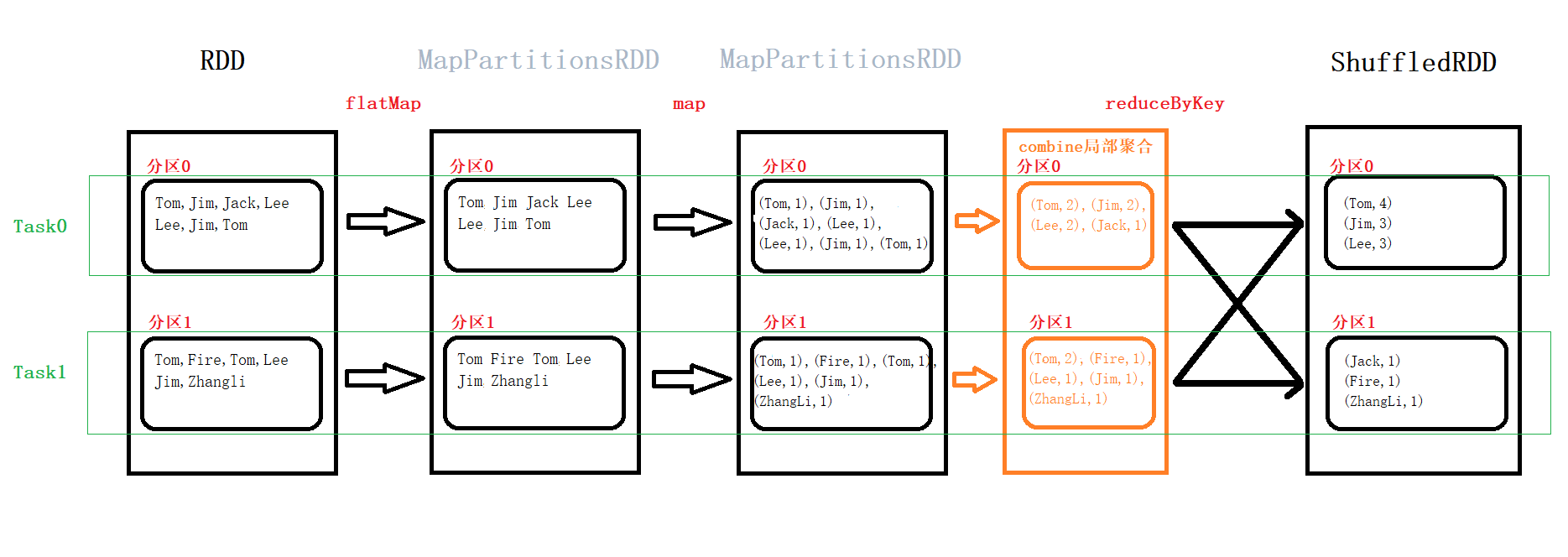
【说明】:在Spark中,提交的应用程序叫做application。一个application中每触发一次action算子就会提交一个job(DAG),一个job根据宽窄依赖可关系以划分成一到多个stage。每一个stage都会生产出多个Task(一个分区对应一个Task),Task是Spark中最小的执行单元,本身是一个线程,在同一个stage中,task内部的计算逻辑是一样的,只是计算的数据不一样。Task本质上就是一个java的实例对象,包含属性和方法。
- reduceByKey 的shuffle操作后分区数默认和混洗前一致,也可以自定义shuffle的分区数(自定义分区数不应小于之前的分区数,否则任务的并行度则为较小的自定义分区数)
- 分区 是可以独立加载的物理块,分区对应并行度。每个分区被读入一个 executor
- task主要包含两种:ShuffleMapTask 和 ResultTask
- stage主要包含两种:ShuffleMapStage 和 ResultStage
4. 任务解析流程
Driver是Spark作业的主控进程,具有main函数。在实例化SparkContext对象后会产生三个实例:DAGScheduler, TaskScheduler, SchedulerBackend,其中SchedulerBackend会产生Driver进程。Driver主要向集群申请资源,记录master注册信息,负责任务的调度和解析,生成stage并调度task到Executor上,Driver运行时会用到 DAGScheduler和TaskScheduler。
程序运行基本机制:在触发RDD的行动算子的时候,会构建DAG有向无环图,并传给DAGScheduler,进行stage划分,并生成TaskSet,交给TaskScheduler。然后TaskScheduler再将每个Task交给具体的Executor执行。
DAGScheduler运行机制:
- (切分stage)根据最后一个RDD创建一个ResultStage,从后往前遍历。如果是窄依赖,就把父RDD加入到当前的stage中;如果是宽依赖,结束当前的stage,创建一个新的stage,继续往前遍历。
- (提交stage)从最后一个stage开始提交,使用深度优先遍历,找有没有父stage没有执行的。有,提交该stage;没有,运行当前stage。
- (运行stage)根据stage的类型,创建task的类型,task的数量等于当前stage中最后一个RDD的分区数量,用TaskSet来封装所有的task,提交给TaskScheduler来调度。
TaskScheduler运行机制:从TaskSet中遍历每一个task,把task进行序列化,之后把序列化的task发送给executor去执行。一个executor的一个core对应处理一个task,若task数量大于总核数,则需要执行多个轮次
5. RDD常见算子的对比
5.1 reduceByKey和groupByKey
reduceByKey 支持 分区内预聚合 功能,可以有效减少 Shuffle 时落盘的数据量,提升Shuffle的性能; groupByKey 支持按照 key 进行分组,直接进行 shuffle。
开发指导:建议使用reduceByKey,但是需要注意是否会影响业务逻辑。
5.2 map和mapPartitions
map 是对rdd中的每一个元素进行操作; mapPartitions 则是对rdd中的每个分区的迭代器进行操作。SparkSql或DataFrame默认会对程序进行mapPartition的优化。
开发指导:在创建数据库连接时,mapPartitions的效率要高很多。但是MapPartitions操作,对于大量数据来说,比如甚至一个partition,100万数据,一次传入一个function以后,那么可能一下子内存不够,但是又没有办法去腾出内存空间来,可能就OOM,内存溢出。而 map 则不存在该问题,逐条处理在内存不够时会进行 GC 回收。

若有收获,就点个赞吧
0 人点赞
