1. 流处理引擎对比
Spark 在流处理方面真正擅长的是 面向吞吐 的数据分析,Spark利用 内存技术、查询优化、缓存 以及 代码生成 来加速数据集的转换过程。在端到端的应用中使用Spark,需要注意接收数据的下游系统必须能够承受流处理带来的吞吐量,否则将面临系统瓶颈。
| 类别 | Spark Streaming | Structured Streaming |
|---|---|---|
| 底层数据结构 | DStream | 流式DataFrame/DataSet |
| 作业特点 | 固定时间间隔的微批处理 | 动态批次间隔的微批处理,基于无限表的连续查询。核心思想是让微批收敛到最小可处理的大小,使流处理更快产生结果 |
| 窗口计算 | 支持 | 支持 |
| 状态计算 | 支持 | 支持 |
| 事件时间处理 | 不支持,但可以通过开发工作自行实现类似原语 | 支持 |
| 故障恢复 | 血缘机制 + 副本机制 | |
| 惰性执行 | 基于惰性组合消除中间过程数据,同时中间结果会在下一个算子操作消费完成后被移除 | |
| 弹性容错 | 1. Yarn等集群管理器一旦发现节点故障,若此时还有空闲资源则会用新的节点来替换当前节点; 1. 失败节点恢复:Spark判断节点是否包含checkpoint文件,方便状态恢复;明确节点在作业的那个阶段重新加入计算。 |
2. 数据交付语义
有些情况会导致数据交付语义出现问题。比如由于 网络分区 原因引起的 僵尸节点 问题,同时当流处理的输出和状态的checkpoint不能在一个原子操作 中完成,即在此过程中发生了故障的话,会导致数据的损坏。
| 交付语义 | 含义 | 使用场景 |
|---|---|---|
| 至少一次 | 保证每个元素都会被处理一次或者多次 | 流处理程序在部分节点失败时,需要替换节点进行重新计算,如果不采用至少一次语义,则可能丢失数据 |
| 至多一次 | 保证每个元素只会被处理一次或者不处理 | 保证僵尸节点与重新调度节点产生了相同的结果时,只追踪其中一组结果。通过丢弃重复数据达到最多一次的交付语义 |
| 仅一次 | 保证每个元素有且仅被处理一次 |
3. Spark弹性计算
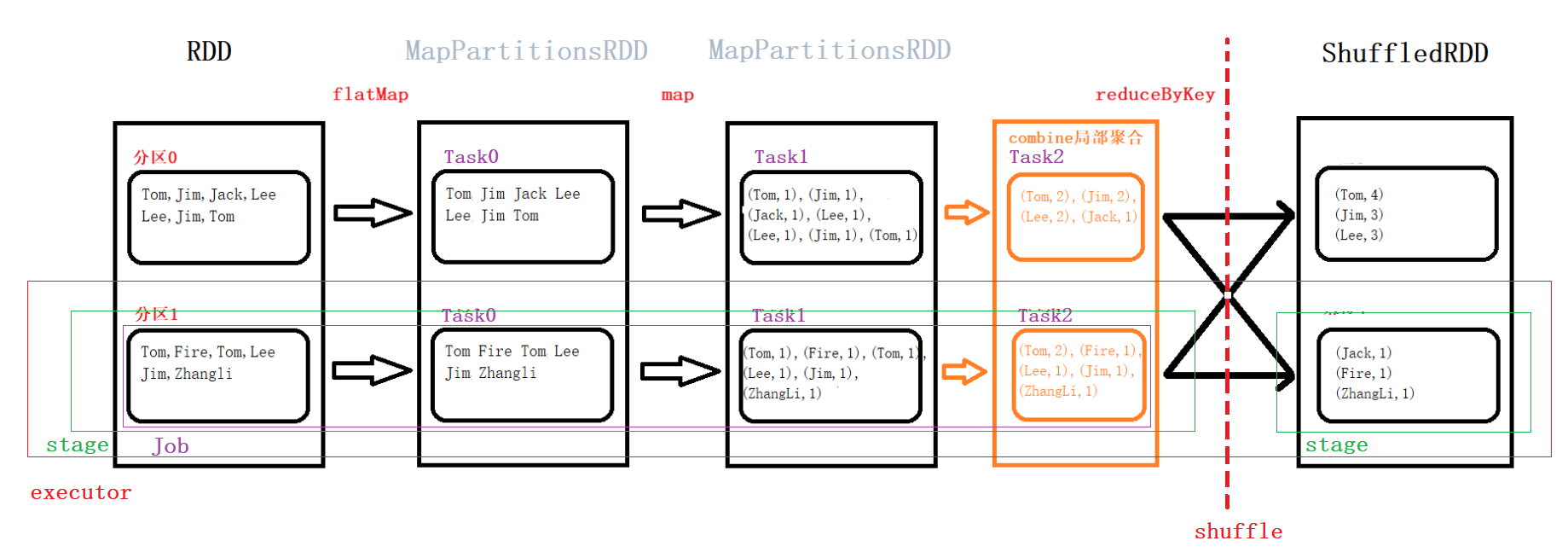
RDD:分布式弹性数据集的逻辑表示,一个RDD包含多个分区 分区:分区是可以独立加载的物理块 Stage:用户程序会分为一个个Stage。根据最后一个RDD创建一个ResultStage,从后往前遍历。如果是 窄依赖,就把父RDD加入到当前的Stage中;如果是 宽依赖,结束当前的Stage,创建一个新的Stage,继续往前遍历 Job:在stage中,对定义一组相互依赖的job(调度单元),job本质上是一个完整的转换集合 Task:根据数据在集群中的位置,作业会被切分为多个Task。Task即本地计算的线程单元,也是job在本地executor中的名称
3.1 Task失败恢复
- 错误原因:基础设施出现故障、程序中的逻辑错误导致的偶发性内存溢出、网络及存储错误,以及数据质量问题(eg:NumberFormatException 以及 NullPointerException 等)
- 解决方案:如果 task 的输入数据通过调用 cache() 或者 persist() 进行存储。如果没有持久化或者存储级别来保证 task 输入数据的副本,spark driver 则需要查询定义了用户计算的 DAG 来决定那些 job 需要重新计算,因为 task 失败可能会触发其他 task 的重新计算,直到 stage 的边界为止。这里有两种情况:
- 存储级别选择 内存/硬盘 时,OOM 等常见错误导致 task 失败的情况,spark 会在缓存的中间数据基础上重新计算;
- 存储级别中包含 数据副本 时,节点故障导致的 task 失败的情况,task 不必重新计算输入数据,因为会在集群的其他节点存在一份完整的副本,可以直接利用副本进行重新启动 task。
3.2 Stage失败恢复
- 错误原因:频繁的 task 失败会导致包含该 task 的 stage 的失败。stage 的边界是 shuffle,如果 shuffle 时 map 端的 stage 失败,则会影响整个 混洗 流程。
解决方案:spark 为了防止 stage 失败引入了 shuffle 服务,利用优秀的本地性在集群中对map数据进行保存和分发。shuffle服务是长期存在于NodeManager进程中的一个辅助服务,独立于 spark task 存在,为 executor 提供一个数据文件交换服务。shuffle 服务本身使用 netty 作为后端服务,数据传输速度快,开销低。一旦 shuffle 服务拥有了数据副本后,executor 便可以在 map task 运行完成后关闭。
3.3 Driver失败恢复
错误原因:driver 在 spark 扮演重要的角色,他是 block 管理器的存储仓库,知道集群中每个数据块所在的位置。同时也是 DAG 保存的位置,另外还是 job 调度状态、元数据以及日志所在之处。如果 driver 丢失,Spark 集群整体可能会立刻丢失目前计算得到的 stage、计算内容以及数据的位置等信息。
- 解决方案:Spark 通过两个方式处理 Driver 失败导致的问题。集群模式部署 + checkpoint检查点机制
- Spark 集群模式,driver 会在集群中的 worker 进程中启动,客户端进程可以在完成提交应用程序的任务后立即退出,无需等待应用程序执行完成。即Spark可以自动重启driver。driver失败后不会导致任务结束,因为集群管理器会重启driver进程,但是只能从头恢复,因为之前保存在 driver 节点上的计算中间状态可能已经丢失。客户端模式则不具备该功能,因此driver会与提交程序的客户端进程中启动;
- 检查点机制,为了避免在driver崩溃时丢失中间状态,spark通过配置checkpoint定期将应用程序的状态快照记录到磁盘上。注意要将 setCheckPointDirectory 设置为可靠存储,如分布式文件系统。因为这些RDD通过集群上的executor创建,不应该与driver程序进行交互来备份。
4. 流处理概念
4.1 窗口计算
窗口:基于时间来进行定期的聚合操作
滚动窗口:滑动窗口和一种特殊形式,即报告频率刚好等于窗口大小。
滑动窗口:基于一段时间内进行聚合操作,并且 滑动频率 比其 聚合周期 要低。比如 最近一天的股价,每小时报告一次。
【常见场景】:滑动窗口和平均函数组合起来就是最常见的滑动窗口形式,即所谓的 移动平均
4.2 有状态计算
有状态的流处理:基于历史观察到的数据来理解新的数据。数据流本质是一个随时间不断增加元素的长集合。
【常见场景】:异常检测,可以计算输入数字的移动平均值和标准差,并输出新元素是否偏离平均值超过5个标准差,这是简单有效计算输入元素分布的极端异常值的方法。
4.3 数据的时间概念
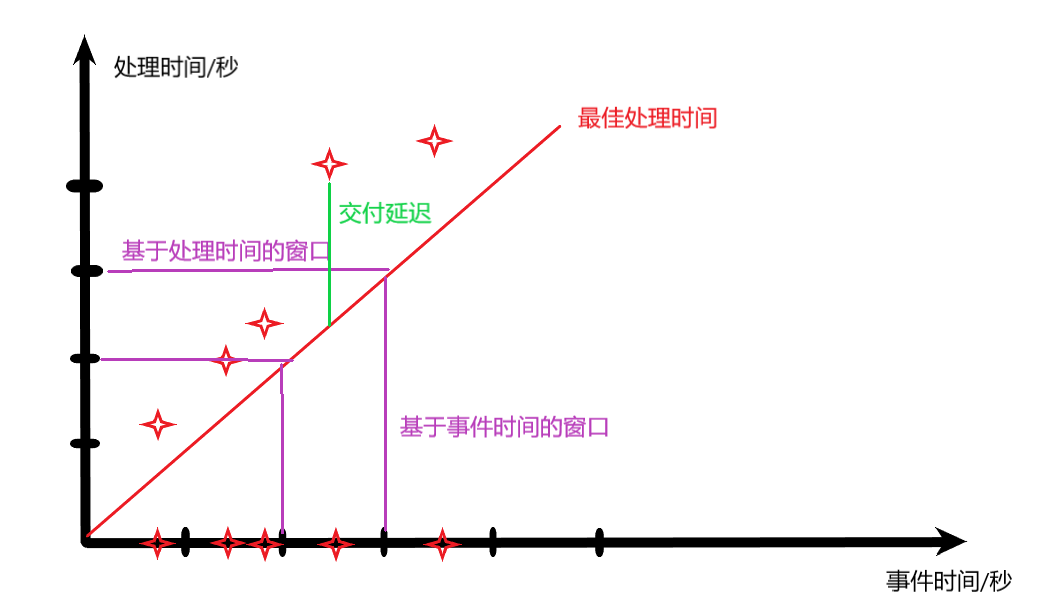
交付延迟:事件产生与最终消费之间的时间差
4.3.1 事件时间
事件时间:事件最初生成的时间轴,通常事件会由 设备时钟 产生时间戳
4.3.2 处理时间
处理时间:流处理系统处理事件的时间
4.3.3 水印:水位线计算
水位线:数据流中给定任意时刻我们 能接受的最晚时间戳。主要用于解决基于事件时间的窗口元素延迟到达的问题。因为有些时候事件会由于网络问题而存在被丢弃的风险,因此水位线定义了元素最晚到达的时间。
在 水位线 的基础上,可以选择两种模式进行处理:
- 在事件超过水位线时进行输出,此时的输出是最终的,因为到目前为止不会考虑更晚的数据;
- 对水位线之前的数据产生输出,此后任意早于水位线的元素延迟到达后可以改变结果。此时结果是临时性的,新数据仍然可以改变最终的结果。

若有收获,就点个赞吧
0 人点赞
