说起前端性能优化,这应该是所有从事前端工作绕不开的话题。不管业务是否需要,跳槽的时候简历上不来点优化内容好像说不过去。作为应届生,能够在业务上接触到的优化场景还不算多,这篇blog也是参考了一些面试宝典。给自己个优化框架,留个印象即可,不求能够说出方案,至少能够知道哪些场景可以做优化。
从输入URL,到页面展示到浏览器发生了什么?
这是一道老生常谈的面试题了,之所以说到这个。因为这个流程是前端开发的全部,所有的优化场景都体现在这个流程中。
- url首先通过DNS服务器,将其转换为对应的IP地址
- 和对应IP的主机建立TCP连接
- 发送HTTP请求到对应主机上
- 收到来自主机的HTTP响应
- 解析响应的HTML文件,并将其内容渲染到浏览器界面上。
DNS查询优化
DNS查询过程
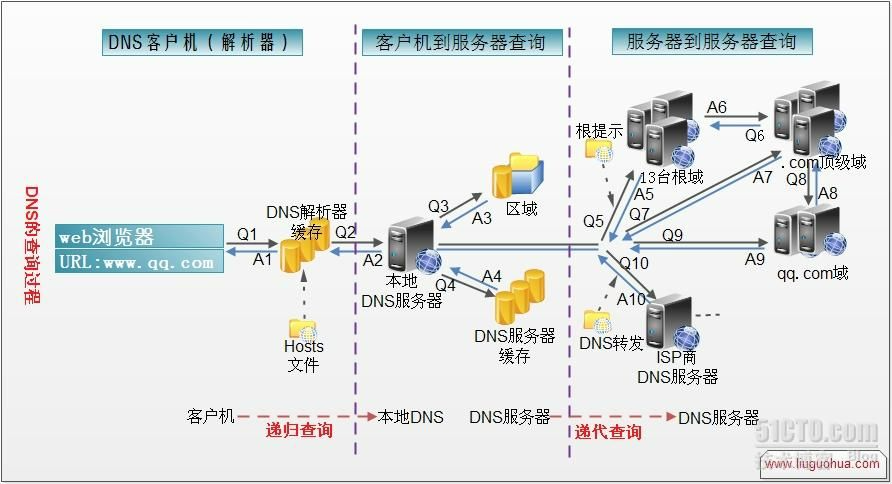
首先复习下,DNS查询过程,
- 首先查询本机hosts文件,如果hosts中有对应的域名IP的映射,就直接返回IP,否则下一步。
- 查找本地DNS解析器缓存,是否有这个网址映射关系,如果有,直接返回,完成域名解析 ,否则下一步。
- 查找它本地DNS服务器,是否有这个网址映射关系,如果有,直接返回,完成域名解析 ,否则下一步。
- 本地DNS服务器把请求发至13台根DNS,根DNS服务器收到请求后会判断这个域名(.com)是谁来授权管理,并会返回一个负责该顶级域名服务器的一个IP。本地DNS服务器收到IP信息后,将会联系负责.com域的这台服务器。这台负责.com域的服务器收到请求后,如果自己无法解析,它就会找一个管理.com域的下一级DNS服务器地址(http://qq.com)给本地DNS服务器。当本地DNS服务器收到这个地址后,就会找http://qq.com域服务器,重复上面的动作,进行查询,直至找到www . qq .com主机。
可以看到,1-3是递归查询,也就是我跑出去一个请求,得到的一定是最后我要的答案。
而4是迭代请求,发出去的请求得到的是下一级域名服务器的IP,直到找到对应域名服务器IP后,才返回最终的答案。
P.S. 本地服务器不是指的本机电脑,而是指的电脑中设置ipv4窗口中设置的DNS服务器。
如何优化(待完善)?
简单来说,就是要能缓存就尽量缓存。上面查询下来其实挺费时间的。
TCP连接优化(待完善)
HTTP请求过程优化
优化方案1:浏览器缓存机制
对于同一个网页得第二次请求,可以走浏览器得缓存。具体介绍看这篇blog:
浏览器缓存
优化方案2:本地存储
本地存储就是cookie、localstorage、sessionstorage了。
主要讲下localstorage和sessionstorage区别:
- 生命周期不同。localstorage是本地持久化存储,存储在其中的数据是永远不会过期的,使其消失的唯一办法是手动删除;seesionstorage是会话级别的。当浏览器tab页关闭时,seesionstorage存储内容也随之释放。
作用域不同。两者虽然都遵循策略,但是seesionstorage 特别的一点在于,即便是相同域名下的两个不同页面,它们的 Session Storage 内容都无法共享。
优化方案3:CDN
以上两种方案优化的是能够少发http请求就少发,即便发了也走协商缓存。那么确实有资源没有缓存,需要请求服务器的时候怎么优化呢?这时候我们就要祭出CDN大法了。
CDN (Content Delivery Network,即内容分发网络)指的是一组分布在各个地区的服务器。这些服务器存储着数据的副本,因此服务器可以根据哪些服务器与用户距离最近,来满足数据的请求。 CDN 提供快速服务,较少受高流量影响。
CDN 往往被用来存放静态资源。所谓“静态资源”,就是像 JS、CSS、图片等不需要业务服务器进行计算即得的资源。而“动态资源”,顾名思义是需要后端实时动态生成的资源。较为常见的就是 JSP、ASP 或者依赖服务端渲染得到的 HTML 页面。
除此之外:
CDN还有一个重要的优化细节:
关于我们讲的cookie,对于每次请求www.abc.com的资源,我们都会在请求头自动携带cookie,但是对于静态资源没有鉴权的需要,不需要携带cookie。当将静态资源放到CDN上后,CDN往往和www.abc.com不在一个域上。例如cdn.abc.com,因此向CDN请求静态资源,请求头不会携带cookie,极大的压缩请求头的体积。HTTP响应过程优化
对于HTTP响应过程,就是将数据发送给客户端。那么怎么处理待发送的数据,才能使这条链路上得到优化呢?
优化方案1:code split
如果我们用webpack将所有资源打包到一个大文件里。体积如此之大的文件在浏览器端script标签中下载必然会造成一定程度的性能问题。因此code split十分必要。
Code Splitting一般需要做这些事情:为 Vendor 单独打包(Vendor 指第三方的库或者公共的基础组件,因为 Vendor 的变化比较少,单独打包利于缓存)
- 为 Manifest (Webpack 的 Runtime 代码)单独打包
- 为不同入口的业务代码打包,也就是代码分割异步加载(同理,也是为了缓存和加载速度)
-
优化方案2:构建结果体积压缩
压缩代码体积(gzip)、删除冗余代码(tree-shaking)。
gzip用法:
具体的做法非常简单,只需要你在你的request headers中加上这么一句:accept-encoding: gzip
一般来说,Gzip 压缩是服务器的活儿:服务器了解到我们这边有一个 Gzip 压缩的需求,它会启动自己的 CPU 去为我们完成这个任务。而压缩文件这个过程本身是需要耗费时间的,大家可以理解为我们以服务器压缩的时间开销和 CPU 开销(以及浏览器解析压缩文件的开销)为代价,省下了一些传输过程中的时间开销。
既然存在着这样的交换,那么就要求我们学会权衡。服务器的 CPU 性能不是无限的,如果存在大量的压缩需求,服务器也扛不住的。服务器一旦因此慢下来了,用户还是要等。Webpack 中 Gzip 压缩操作的存在,事实上就是为了在构建过程中去做一部分服务器的工作,为服务器分压。优化方案3:图片资源的优化
在返回的资源中,图片资源通常数量很多,毕竟大部分网页后由许多贴图嘛。因此,图片资源优化必不可少。
不同的图片格式有不同的优点,下面总结一下:JPG/JPEG
特点:有损压缩、体积小、加载快、不支持透明。
缺点:压缩后显示一些线条感强的图片,如logo图。会导致看起来很模糊。
使用场景:适用于色彩丰富的图片,出现在:大背景图、轮播图。PNG
特点:无损压缩、质量高、体积大、支持透明
缺点:体积大,如果一些很大的图,色彩丰富的图用PNG的话,体积会很大。
使用场景:小logo,线条感强的图片。SVG
特点:文本文件、体积小、不失真、兼容性好
缺点:渲染成本较高
使用场景:哪里都可以用base64
特点:文本文件、依赖编码、小图标解决方案(减少一次HTTP请求)
缺点:Base64 编码后,图片大小会膨胀为原文件的 4/3(这是由 Base64 的编码原理决定的)
应用场景:图片无法以雪碧图的形式与其它小图结合(合成雪碧图仍是主要的减少 HTTP 请求的途径,Base64 是雪碧图的补充)webP
雪碧图
雪碧图并不是一个图片格式,而是图片优化手段。雪碧图就是把众多小图片合成一张大图片,然后通过
background-position去定位具体的某个图片。是一种减少HTTP请求的优化手段。浏览器渲染过程优化
优化方案1:服务端渲染
是什么
在各类框架兴起的现代前端中,我们常常采用的是客户端渲染。回顾下写react的时候,是不是index中有这么一句
<!doctype html><html><head><title>我是客户端渲染的页面</title></head><body><div id='root'></div><script src='index.js'></script></body></html>
我们的react代码从index.js引入。交给浏览器执行index.js,并插入对应的DOM。浏览器不执行js,压根不知道最终展示的页面是什么。
与之相反,服务端渲染就是把index.js的执行交给服务器,在服务器上就把页面加载好了。浏览器收到的页面就是完整的可以交互的页面。为什么
我们为什么需要服务端渲染?
理由1:处于SEO的考虑,通常网站更愿意在搜索引擎中增加曝光量。搜索引擎也会爬取相应的网页。但是并不会去执行它的js代码。这样的话客户端渲染的页面啥也没有,不利于SEO。
理由2:提高首屏加载速度。很显然,js的执行会阻塞其他线程,如果客户端渲染的js执行时间过长,那么就会导致首屏白屏,这是很不利于用户体验的。因此,在服务器就把对应的js加载完,更加有利于用户体验。缺点:
你想想,一个网站数以万计的用户,都需要服务端渲染,那么这对服务器是多么大的压力啊。
插播一条前置知识:浏览器运行机制
浏览器内核可以分成两部分:渲染引擎(Layout Engine 或者 Rendering Engine)和 JS 引擎。早期渲染引擎和 JS 引擎并没有十分明确的区分,但随着 JS 引擎越来越独立,内核也成了渲染引擎的代称。
浏览器渲染过程解析
优化方案2:CSS优化建议
CSS 引擎查找样式表,对每条规则都按从右到左的顺序去匹配。
#myList li {}
我们这个看似“没毛病”的选择器,实际开销相当高:浏览器必须遍历页面上每个 li 元素,并且每次都要去确认这个 li 元素的父元素 id 是不是 myList。
因此,根据这一特性,在开发中总结如下几点: 避免使用通配符,只对需要用到的元素进行选择。
- 关注可以通过继承实现的属性,避免重复匹配重复定义。
- 少用标签选择器。如果可以,用类选择器替代。
- 减少嵌套。后代选择器的开销是最高的,因此我们应该尽量将选择器的深度降到最低(最高不要超过三层),尽可能使用类来关联每一个标签元素。
优化方案3:CSS,JS加载顺序
HTML、CSS 和 JS,都具有阻塞渲染的特性。
HTML和CSS解析过程虽然是并行的,但是CSS解析为未完成,两者也不能合成render树。JS就不用说了,阻塞渲染进程。
因此,CSS应该尽早的下载到客户端,以便缩短首次渲染的时间。
事实上,现在很多团队都已经做到了尽早(将 CSS 放在 head 标签里)和尽快(启用 CDN 实现静态资源加载速度的优化)。这个“把 CSS 往前放”的动作,对很多同学来说已经内化为一种编码习惯。那么现在我们还应该知道,这个“习惯”不是空穴来风,它是由 CSS 的特性决定的。
对于首屏网站来说,js不是最主要的。没有 JS,CSSOM 和 DOM 照样可以组成渲染树,页面依然会呈现——即使它死气沉沉、毫无交互。
JS 的作用在于修改,它帮助我们修改网页的方方面面:内容、样式以及它如何响应用户交互。这“方方面面”的修改,本质上都是对 DOM 和 CSSDOM 进行修改。因此 JS 的执行会阻止 CSSOM,在我们不作显式声明的情况下,它也会阻塞 DOM。
当 HTML 解析器遇到一个 script 标签时,它会暂停渲染过程,将控制权交给 JS 引擎。JS 引擎对内联的 JS 代码会直接执行,对外部 JS 文件还要先获取到脚本、再进行执行。等 JS 引擎运行完毕,浏览器又会把控制权还给渲染引擎,继续 CSSOM 和 DOM 的构建。 因此与其说是 JS 把 CSS 和 HTML 阻塞了,不如说是 JS 引擎抢走了渲染引擎的控制权。
JS三种加载模式:
<!-- 这种情况下 JS 会阻塞浏览器,浏览器必须等待 index.js 加载和执行完毕才能去做其它事情。 --><script src="index.js"></script><!-- async 模式下,JS 不会阻塞浏览器做任何其它的事情。它的加载是异步的,当它加载结束,JS 脚本会立即执行。 --><script async src="index.js"></script><!-- defer 模式下,JS 的加载是异步的,执行是被推迟的。等整个文档解析完成,被标记了 defer 的 JS 文件才会开始依次执行。 --><script defer src="index.js"></script>
什么时候用async、defer?
如果脚本和DOM依赖关系不强的话,选择async。如果脚本和DOM依赖关系强的话,选defer。
理解:像是操作DOM之类的脚本,肯定得等到渲染完成后,才能拿到DOM元素。因此此时必须要defer,其他就async即可。
插播第二条前置知识:DOM操作为什么慢?
优化方案3:减少DOM操作
看如下html,
<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta ><meta http-equiv="X-UA-Compatible" content="ie=edge"><title>DOM操作测试</title></head><body><div id="container"></div></body></html>
当前需求是需要往container的div中插入10000条数据。
如果我如下写:
for(var count=0;count<10000;count++){document.getElementById('container').innerHTML+='<span>我是一个小测试</span>'}
很明显,DOM操作次数太多了。每次循环中都进行了一次DOM操作,都会引起浏览器的reflow和repaint。
我们完全可以改为如下操作:
let container = document.getElementById('container')
let content = ''
for(let count=0;count<10000;count++){
// 先对内容进行操作
content += '<span>我是一个小测试</span>'
}
// 内容处理好了,最后再触发DOM的更改
container.innerHTML = content
先将插入的10000条html语句通过字符串保存起来,再一次性执行。
或者,使用DOM Fragment 的 API。
let container = document.getElementById('container')
// 创建一个DOM Fragment对象作为容器
let content = document.createDocumentFragment()
for(let count=0;count<10000;count++){
// span此时可以通过DOM API去创建
let oSpan = document.createElement("span")
oSpan.innerHTML = '我是一个小测试'
// 像操作真实DOM一样操作DOM Fragment对象
content.appendChild(oSpan)
}
// 内容处理好了,最后再触发真实DOM的更改
container.appendChild(content)
优化方案4:合理利用渲染时机
现代前端框架都是了异步更新策略,但具体是怎么运行的呢?首先得从浏览器执行顺序说起:
- 首先,将script脚本作为宏任务执行,将内部的宏任务进宏任务队列,微任务进微任务队列
- 将微任务队列清空(注意,宏任务队列一次取一个执行,微任务队列一次一整队全执行)
- 执行渲染,更新界面
- 检查是否存在 Web worker 任务,如果有,则对其进行处理 。
这四个步骤构成一个循环,也就是浏览器中的事件循环机制。
那么问题来了,当我们在script中编写代码操作DOM时候,如果采用异步更新策略的话,是将更新这个动作作为宏任务好呢?还是微任务好呢?
答案是微任务,因为放进微任务队列的话,当我们处理完脚本后,马上就可以清空微任务队列,从而在浏览器渲染之前更新完DOM。
总结:
我们更新 DOM 的时间点,应该尽可能靠近渲染的时机。当我们需要在异步任务中实现 DOM 修改时,把它包装成 micro 任务是相对明智的选择。
优化方案5:合理利用CSS中的回流和重绘
向我们之前直接操作DOM节点,增加删除操作。肯定是会引发回流和重绘的。但更改DOM元素的一些CSS属性同样也会引发回流和重绘。
什么属性会触发回流?
- 改变DOM元素几何结构的,例如:width、height、padding、margin、border、left、top等
- 获取一些特定属性的值,需要通过即时计算得到。因此浏览器为了获取这些值,也会进行回流。例如:
offsetTop、offsetLeft、offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight - 当我们调用了
getComputedStyle方法,或者 IE 里的currentStyle时,也会触发回流。原理是一样的,都为求一个“即时性”和“准确性”。避免逐条改变样式,使用类名去合并样式
优化成如下:<head> <title>Document</title> <style> .basic_style { width: 100px; height: 200px; border: 10px solid red; color: red; } </style> </head> <body> <div id="container"></div> <script> const container = document.getElementById('container') container.classList.add('basic_style') </script> </body>把DOM离线
我们上文所说的回流和重绘,都是在“该元素位于页面上”的前提下会发生的。一旦我们给元素设置 display: none,将其从页面上“拿掉”,那么我们的后续操作,将无法触发回流与重绘——这个将元素“拿掉”的操作,就叫做 DOM 离线化。const container = document.getElementById('container') container.style.width = '100px' container.style.height = '200px' container.style.border = '10px solid red' container.style.color = 'red'
优化为:const container = document.getElementById('container') container.style.width = '100px' container.style.height = '200px' container.style.border = '10px solid red' container.style.color = 'red'let container = document.getElementById('container') // 离线 container.style.display = 'none' container.style.width = '100px' container.style.height = '200px' container.style.border = '10px solid red' container.style.color = 'red' //...(省略了许多类似的后续操作) container.style.display = 'block'聪明的现代浏览器
现代浏览器是很聪明的。浏览器自己也清楚,如果每次 DOM 操作都即时地反馈一次回流或重绘,那么性能上来说是扛不住的。于是它自己缓存了一个 flush 队列,把我们触发的回流与重绘任务都塞进去,待到队列里的任务多起来、或者达到了一定的时间间隔,或者“不得已”的时候,再将这些任务一口气出队。
因此,实际上执行下面这一段代码,也只触发一次回流重绘
但是,你无法要求所有浏览器都是聪明的,作为开发者基本的优化手段还是要有的。const container = document.getElementById('container') container.style.width = '100px' container.style.height = '200px' container.style.border = '10px solid red' container.style.color = 'red'优化应用
图片懒加载(本质就是滚动优化)
略防抖与节流
略

若有收获,就点个赞吧
0 人点赞
