1 ESMM
1.1 背景
Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate
论文基于 Multi-Task Learning (MTL) 的思路,提出一种名为ESMM的CVR预估模型,有效解决了真实场景中CVR预估面临的数据稀疏以及样本选择偏差这两个关键问题。
- 样本选择偏差:构建的训练样本集的分布采样不准确
- 稀疏数据:点击样本占曝光样本的比例很小
1.1.1 样本选择偏差 Sample Selection Bias(SSB)
转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间的样本进行预估,而非只对点击样本进行预估。即训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战,导致模型上线后,线上业务效果往往一般。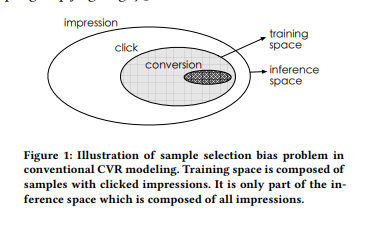
1.1.2 稀疏数据 Data Sparsity(DS)
CVR预估任务的使用的训练数据(即点击样本)远小于CTR预估训练使用的曝光样本。仅使用数量较小的样本进行训练,会导致深度模型拟合困难。
一些策略可以缓解这两个问题,例如从曝光集中对unclicked样本抽样做负例缓解SSB,对转化样本过采样缓解DS等。但无论哪种方法,都没有从实质上解决上面任一个问题。
由于点击=>转化,本身是两个强相关的连续行为,作者希望在模型结构中显示考虑这种“行为链关系”,从而可以在整个空间上进行训练及预测。这涉及到CTR与CVR两个任务,因此使用多任务学习(MTL)是一个自然的选择,论文的关键亮点正在于“如何搭建”这个MTL。
1.2 ESMM 模型核心思想CTR:点击率预估模型
CVR:转化率预估模型
CRVR:点击转化率预估模型
ESMM引入两个辅助任务 CTR 以及 CTCVR 消除了之前传统的CVR问题并同时得到了CVR模型,在ESMM中训练的模型就是针对全空间样本S来训练的,通过估计CTR以及估计CTCVR来得到CVR
其中 表示曝光,
表示曝光, 表示点击,
表示点击,  表示转化
表示转化
- 损失函数
ESMM的损失函数由CTR以及CTCVR的损失函数组成
其中  和
和  分别是CVR网络和CTR网络的参数,
分别是CVR网络和CTR网络的参数,  是交叉熵损失函数,在CTR任务中,点击表示正样本,其余的表示负样本;在CVR任务中,点击并转化的表示正样本,其余的表示负样本。
是交叉熵损失函数,在CTR任务中,点击表示正样本,其余的表示负样本;在CVR任务中,点击并转化的表示正样本,其余的表示负样本。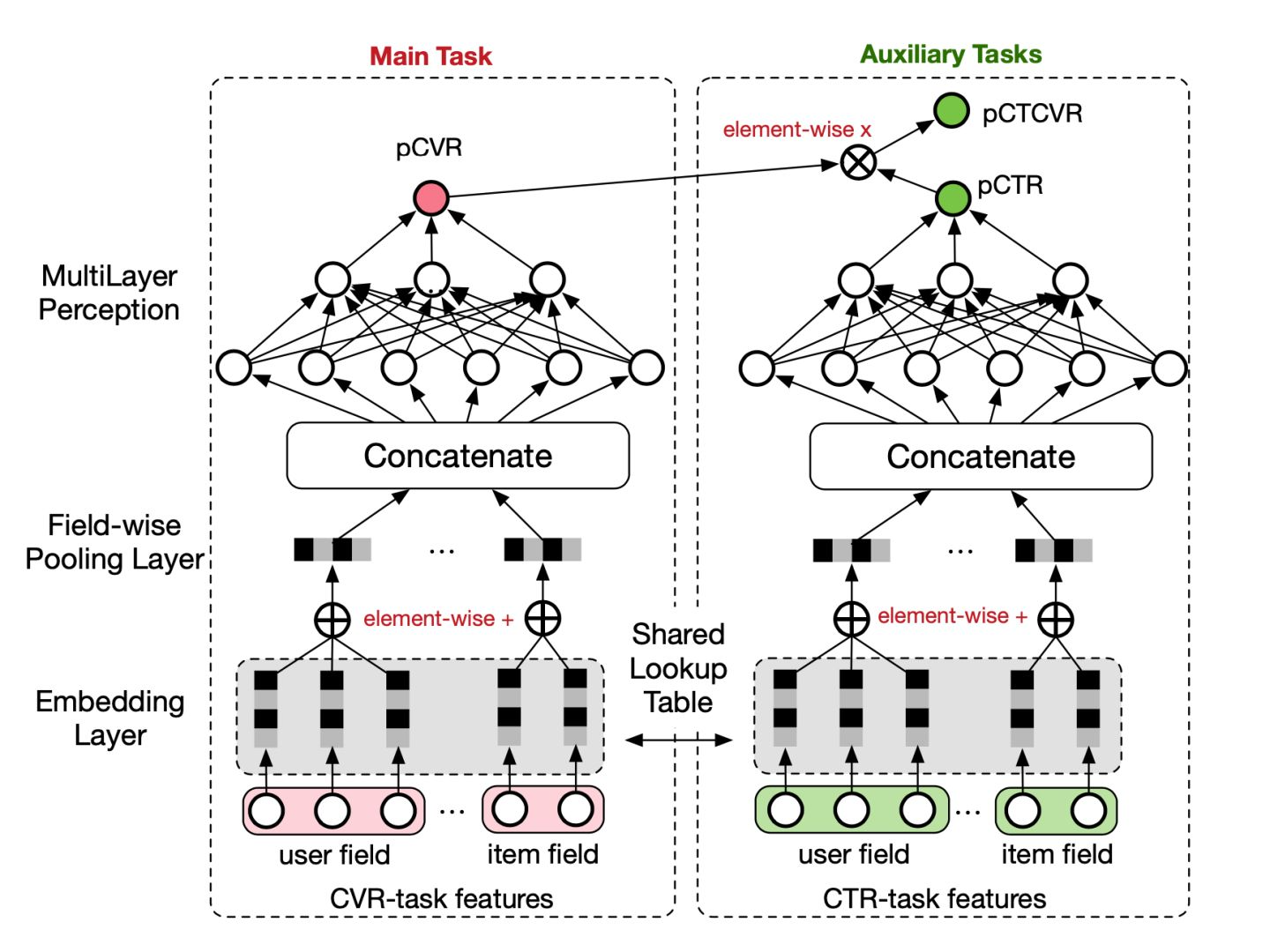
整个模型的结构非常的简单清晰,分为一个main task和一个auxiliary task,其中main task依然是传统的cvr转化模型,auxiliary task通过shared lookup table与main task共享embedding层,这样缓解了数据稀疏导致的embedding学习表达较弱的问题,ctr预估模型主要用到了impression数据,因此共享embedding层可以为cvr预估模型带来一些impression相关的数据信息,这样就解决了样本偏差的问题
1.3 代码实现
class ESMM(torch.nn.Module):def __init__(self, user_features, item_features, cvr_params, ctr_params):super().__init__()self.user_features = user_featuresself.item_features = item_featuresself.embedding = EmbeddingLayer(user_features + item_features)self.tower_dims = user_features[0].embed_dim + item_features[0].embed_dim# 构建CVR和CTR的双塔self.tower_cvr = MLP(self.tower_dims, **cvr_params)self.tower_ctr = MLP(self.tower_dims, **ctr_params)def forward(self, x):embed_user_features = self.embedding(x, self.user_features,squeeze_dim=False).sum(dim=1)embed_item_features = self.embedding(x, self.item_features,squeeze_dim=False).sum(dim=1)input_tower = torch.cat((embed_user_features, embed_item_features), dim=1)cvr_logit = self.tower_cvr(input_tower)ctr_logit = self.tower_ctr(input_tower)cvr_pred = torch.sigmoid(cvr_logit)ctr_pred = torch.sigmoid(ctr_logit)# 计算pCTCVR = pCTR * pCVRctcvr_pred = torch.mul(cvr_pred, cvr_pred)ys = [cvr_pred, ctr_pred, ctcvr_pred]return torch.cat(ys, dim=1)
2 MMOE模型
Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Expert
2.1 Motivation
- 多任务模型通过学习不同任务的联系和差异,可提高每个任务的学习效率和质量。
- 多任务学习的的框架广泛采用shared-bottom的结构,不同任务间共用底部的隐层。这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响
多任务学习的的框架广泛采用shared-bottom的结构,不同任务间共用底部的隐层。这种结构本质上可以减少过拟合的风险,但是效果上可能受到任务差异和数据分布带来的影响
2.2 MMOE模型原理
MMoE模型的结构(下图c)基于广泛使用的Shared-Bottom结构(下图a)和MoE结构,其中图(b)是图(c)的一种特殊情况,下面依次介绍。
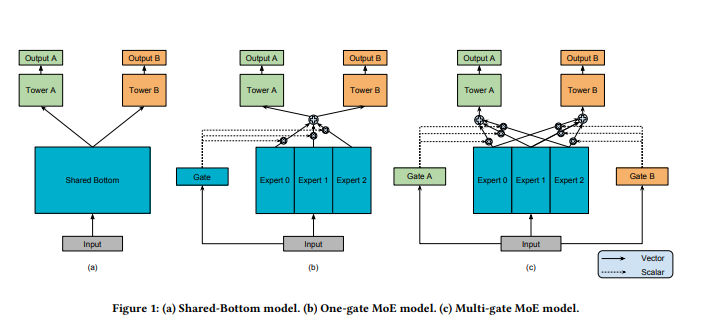
2.2.1 Shared-Bottom Multi-task Model
如上图a所示,shared-bottom网络(表示为函数f)位于底部,多个任务共用这一层。往上,K个子任务分别对应一个tower network(表示为
 ),每个子任务的输出
),每个子任务的输出  。
。
2.2.3 Mixture-of-Experts
MoE模型可以形式化表示为

其中 ,
,  是n个expert network(expert network可认为是一个神经网络)。g是组合experts结果的gating network,具体来说g产生n个experts上的概率分布,最终的输出是所有experts的带权加和。显然,MoE可看做基于多个独立模型的集成方法。这里注意MoE并不对应上图中的b部分。
是n个expert network(expert network可认为是一个神经网络)。g是组合experts结果的gating network,具体来说g产生n个experts上的概率分布,最终的输出是所有experts的带权加和。显然,MoE可看做基于多个独立模型的集成方法。这里注意MoE并不对应上图中的b部分。
后面有些文章将MoE作为一个基本的组成单元,将多个MoE结构堆叠在一个大网络中。比如一个MoE层可以接受上一层MoE层的输出作为输入,其输出作为下一层的输入使用。2.2.4 Multi-gate Mixture-of-Experts
章提出的模型(简称MMoE)目的就是相对于shared-bottom结构不明显增加模型参数的要求下捕捉任务的不同。其核心思想是将shared-bottom网络中的函数f替换成MoE层,如上图c所示,形式化表达为:

其中 ,输入就是input feature,输出是所有experts上的权重。
,输入就是input feature,输出是所有experts上的权重。
一方面,因为gating networks通常是轻量级的,而且expert networks是所有任务共用,所以相对于论文中提到的一些baseline方法在计算量和参数量上具有优势。
另一方面,相对于所有任务公共一个门控网络(One-gate MoE model,如上图b),这里MMoE(上图c)中每个任务使用单独的gating networks。每个任务的gating networks通过最终输出权重不同实现对experts的选择性利用。不同任务的gating networks可以学习到不同的组合experts的模式,因此模型考虑到了捕捉到任务的相关性和区别。0 参考

若有收获,就点个赞吧
0 人点赞
