1 YoutubeDNN
YouTube是世界上最⼤的视频创作及分享平台,其视频推荐的⾯临的主要问题有:
- 海量数据:现有的推荐算法通常在⼩数据集有良好的表现,但是在YouTube这样规模的数据集上未必表现良好,同时YouTube⽤户基数庞⼤,对服务系统的响应时间有严格要求。
- 新鲜度:YouTube系统每秒钟都有⼤量新视频上传,推荐系统应该能够快速的对视频及⽤户⾏为作出反馈,并平衡新⽼视频的综合推荐。
- 噪声: ⽤户通常多种外界因素⼲扰,推荐系统通常不能够准确获得⽤户对视频的反馈信息,所以推荐算法必须对数据⾜够鲁棒。
Deep Neural Networks for YouTube Recommendations
论文通过深度召回模型(candidate generation model)和深度排序模型(deep ranking model)搭建推荐系统,为YouTube用户推荐视频。文章中还详细介绍了在实践应用中的一些小tricks.
1.1 推荐系统架构
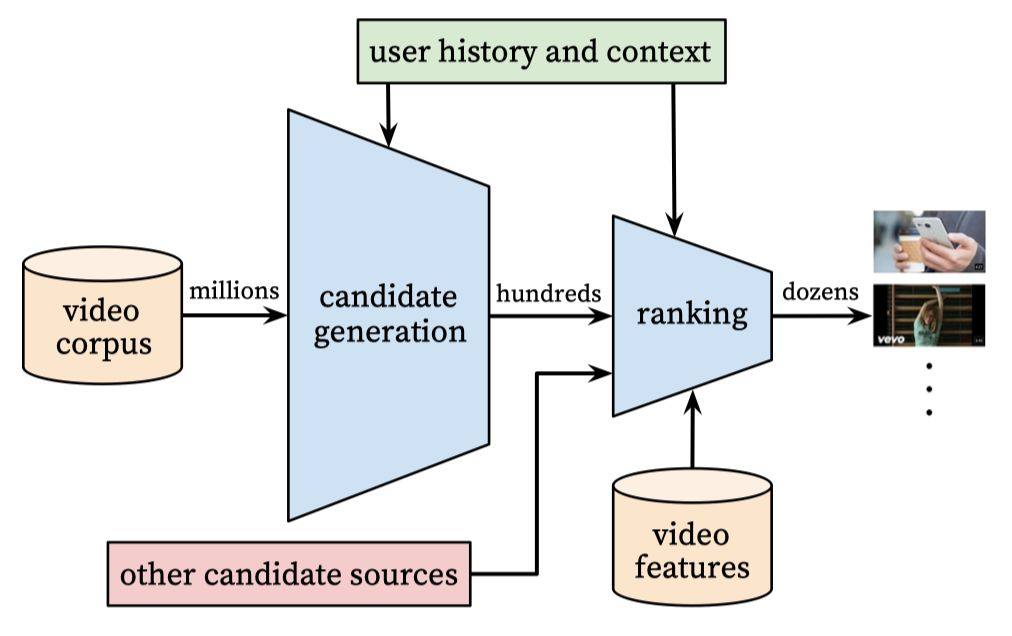
系统中有两个网络,分别用于召回(candidate generation)和排序。
召回网络从用户行为历史中拿到event作为输入,最终从一个巨大的video集中拿到几百个video。这一网络仅通过协同过滤来提供粗糙的个性化。用户之间的相似性通过观看video的id,查询token和一些人口统计学特征来表征。
在调整网络的过程中我们利用了一些离线指标,例如精度、召回、ranking loss等等。我们最终利用了A/B测试,通过观察点击率、video观看时长等指标来证明模型的有效性。
1.2 召回部分
将推荐视作一个巨多类别的多分类问题,即给出user U 和上下文C,从百万量级的video集V中确定时刻t的video取值 :
:
其中 表示(user, context)的高维度embedding,
表示(user, context)的高维度embedding, 表示每个候选video的embedding。这部分网络的任务就是学习到用户历史和上下文构成的用户embedding u。
表示每个候选video的embedding。这部分网络的任务就是学习到用户历史和上下文构成的用户embedding u。
尽管YouTube有很多显式反馈,我们还是选择了隐式反馈来训练模型,即用户看完一个video是一个正样本。这种选择有利于我们对于长尾video的推荐。
为有效地对模型进行训练,我们选择了candidate sampling并对权重进行了修正。对每个样本,目标是使正确label和采样到的负类别的交叉熵最小化。
召回模型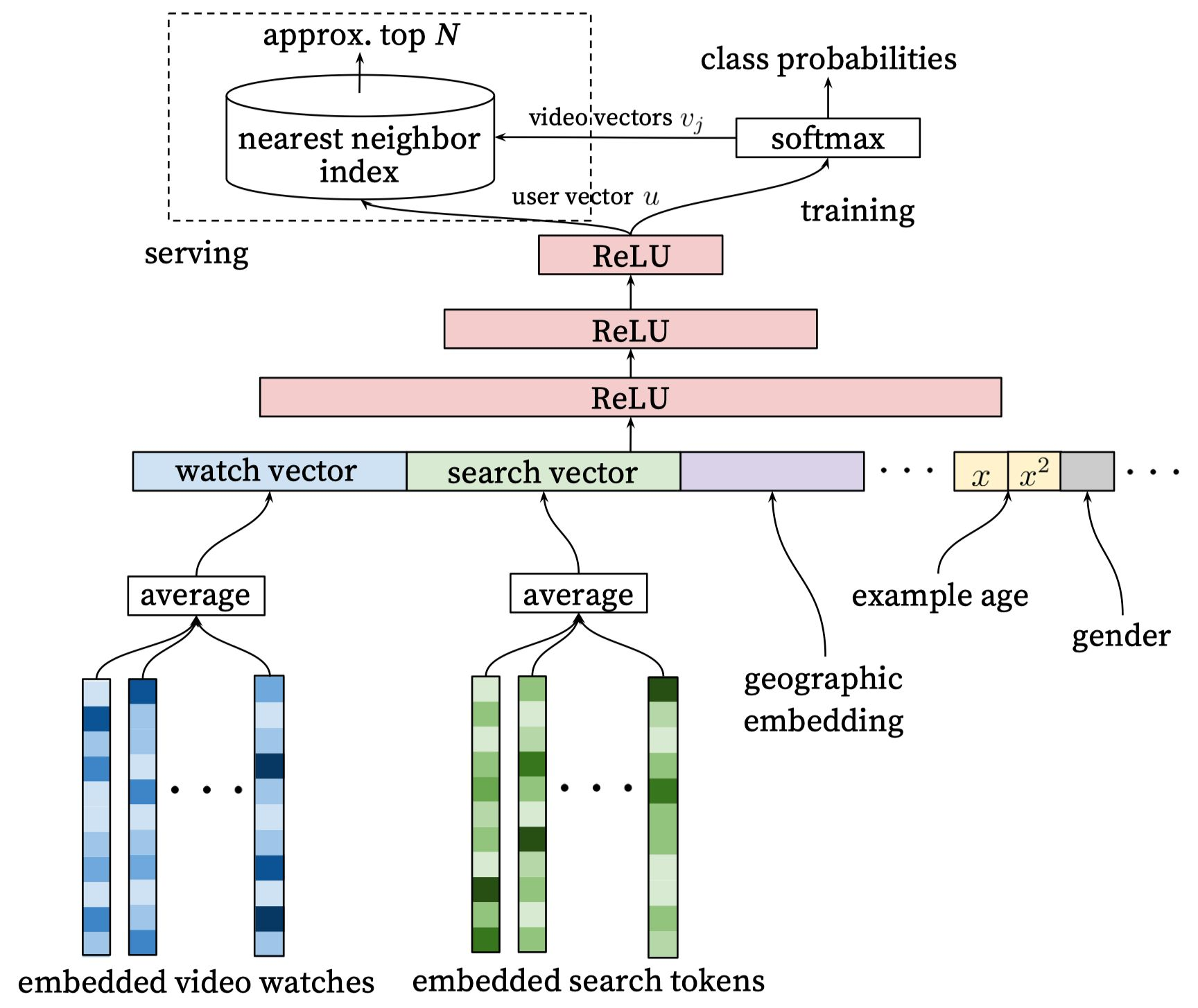
1.3 排序模型
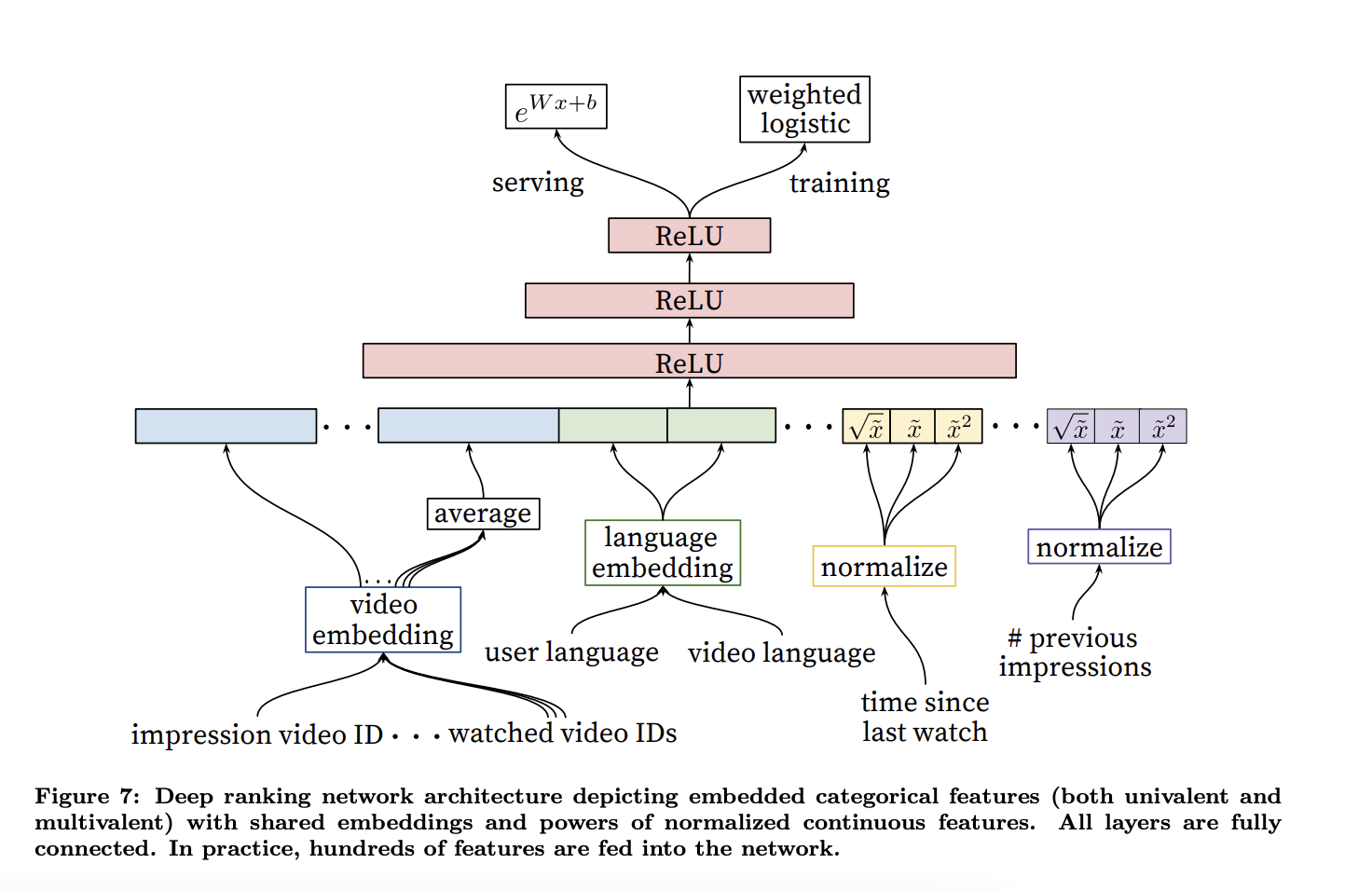
- 输入:video embedding,language embedding,上次观看时间等一系列特征
- 输出:利用逻辑回归进行打分,返回各个推荐的得分(根据得到的点击概率进行排名)
-
1.4 模型tricks
模型特征:即使神经网络已经在一定程度上解决了特征工程的问题,本篇文章仍然花费经历建立大量有效的特征,如:用户从这个频道观看的video个数;用户最后一次浏览该话题的时间;推荐的来源;推荐来源的得分;是否推荐过但是没看;用户是否登录;用户看的最后N个视频embedding;用户上次搜索序列embedding;用户特征、商品特征等
- 分类变量映射到embedding
- 连续特征[0,1]归一化
- 目标变量:观看时间;利用加权逻辑回归,正例(观看)用观看时间加权,负例(未点击)用单位权重加权,则逻辑回归几率(odds)为
 ,其中N是样本数量,k是正样本个数,Ti是样本i的观看时间
,其中N是样本数量,k是正样本个数,Ti是样本i的观看时间 -
1.5 代码实现
```python class YoutubeDNN(torch.nn.Module): def init(self, user_features, item_features, neg_item_feature, user_params, temperature=1.0):
super().__init__()self.user_features = user_featuresself.item_features = item_featuresself.neg_item_feature = neg_item_featureself.temperature = temperatureself.user_dims = sum([fea.embed_dim for fea in user_features])self.embedding = EmbeddingLayer(user_features + item_features)self.user_mlp = MLP(self.user_dims, output_layer=False, **user_params)self.mode = None
def forward(self, x):
user_embedding = self.user_tower(x)item_embedding = self.item_tower(x)if self.mode == "user":return user_embeddingif self.mode == "item":return item_embedding# 计算相似度y = torch.mul(user_embedding, item_embedding).sum(dim=2)y = y / self.temperaturereturn y
def user_tower(self, x):
# 用于inference_embedding阶段if self.mode == "item":return Noneinput_user = self.embedding(x, self.user_features, squeeze_dim=True)user_embedding = self.user_mlp(input_user).unsqueeze(1)user_embedding = F.normalize(user_embedding, p=2, dim=2)if self.mode == "user":return user_embedding.squeeze(1)return user_embedding
def item_tower(self, x):
if self.mode == "user":return Nonepos_embedding = self.embedding(x, self.item_features, squeeze_dim=False)pos_embedding = F.normalize(pos_embedding, p=2, dim=2)if self.mode == "item":return pos_embedding.squeeze(1)neg_embeddings = self.embedding(x, self.neg_item_feature, squeeze_dim=False).squeeze(1)neg_embeddings = F.normalize(neg_embeddings, p=2, dim=2)return torch.cat((pos_embedding, neg_embeddings), dim=1)
```

若有收获,就点个赞吧
0 人点赞
