0x0 总览
Datapath包括两部分:
- 内核态,也叫fast path,是用户态的一个高速缓存,用于加快查找。
- Microflow:全匹配,包括l2,l3,l4的所有字段。一次查找,对于长连接性能较好。
- Megaflow:模糊匹配,由用户态根据openflow流表生成。多次查找,对于短连接较好。
- 用户态,即vswitchd部分,也叫slow-path,这部分采用openflow的流表查找,性能较差。
每个连接的第一个报文,在Megaflow Cache还没生成前,都会上报到应用层,之后应用层下发Megaflow cache,之后该连接的所有报文都在内核态完成转发。一次学习,多次转发。理论上的性能如下:
- Microflow命中:要两次hash查找,一次查mircroflow(只能获取到megaflow的hash表索引),一次查megaflow。
- Megaflow命中:需要n/2次hash查找(依次查询所有的hash表)。
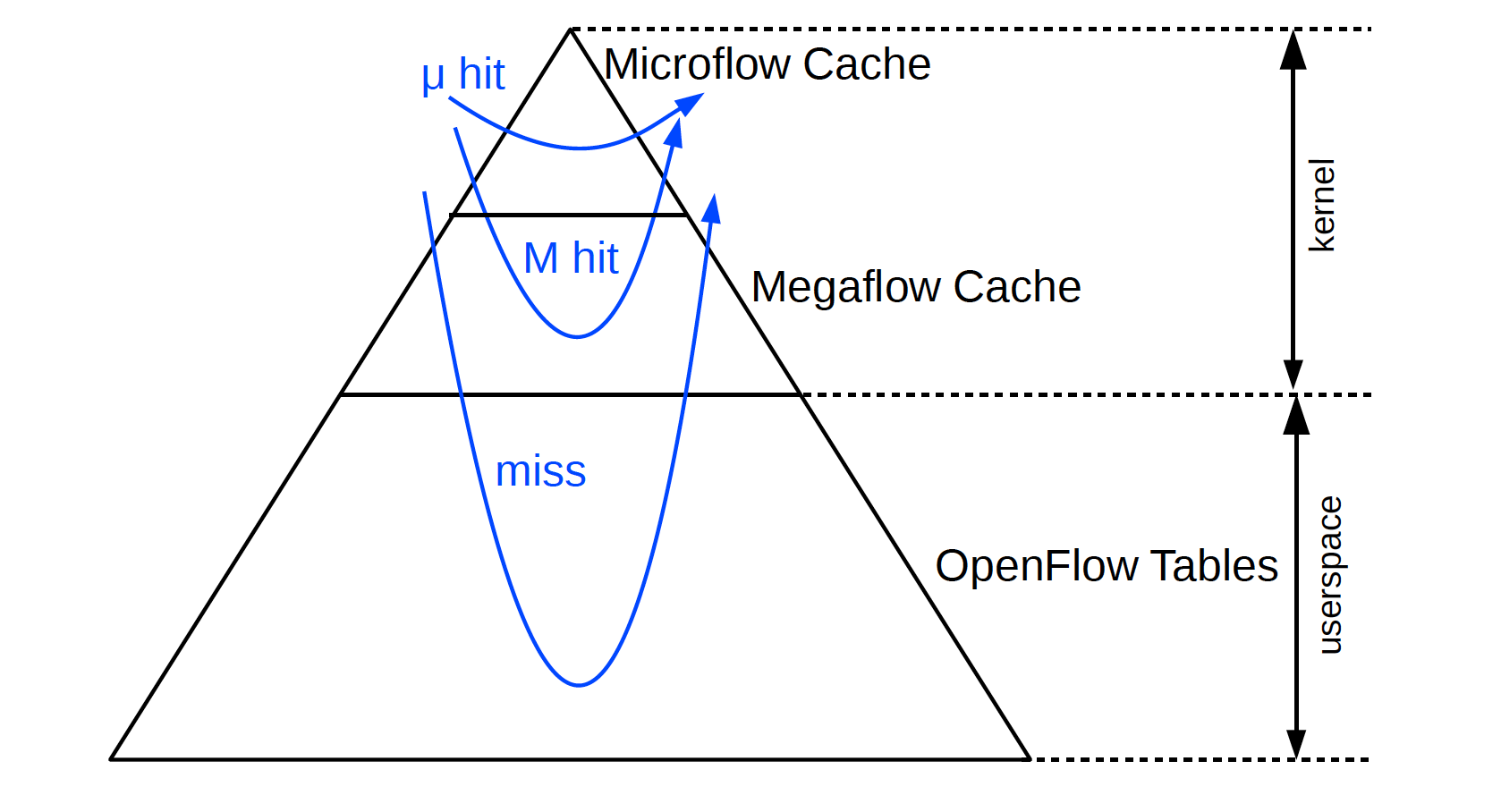
0x1 Microflow
实现
skb_hash:每个skb会根据l2/l3/l4计算一个hash(内核原来就有)。- hash表:MicroCache的hash表大小为128个,采用再哈希的方法解决冲突问题,一共有4个函数,分别取其中一个字节,作为hash值。
缓存淘汰:在发生冲突的时候,选取4个hash函数中冲突节点skb_hash的最小值进行淘汰。
为什么要选择小的淘汰?
- WHY,这样子的好处是什么?因为小的冲突比较多吗?难道是为了找一个空的(因为空的值为0)
```c
/*
- mask_cache maps flow to probable mask. This cache is not tightly
- coupled cache, It means updates to mask list can result in inconsistent
- cache entry in mask cache.
- This is per cpu cache and is divided in MC_HASH_SEGS segments.
- In case of a hash collision the entry is hashed in next segment.
/
struct sw_flow ovs_flow_tbl_lookup_stats(struct flow_table *tbl,
{ struct mask_array ma = rcu_dereference(tbl->mask_array); struct table_instance ti = rcu_dereference(tbl->ti); struct mask_cache_entry entries, ce; struct sw_flow *flow; u32 hash; int seg;const struct sw_flow_key *key,u32 skb_hash,u32 *n_mask_hit)
*n_mask_hit = 0; if (unlikely(!skb_hash)) { u32 mask_index = 0;
return flow_lookup(tbl, ti, ma, key, n_mask_hit, &mask_index); }
/* Pre and post recirulation flows usually have the same skb_hash
- value. To avoid hash collisions, rehash the ‘skb_hash’ with
- ‘recirc_id’. */ if (key->recirc_id) skb_hash = jhash_1word(skb_hash, key->recirc_id);
ce = NULL; hash = skb_hash; entries = this_cpu_ptr(tbl->mask_cache);
/ Find the cache entry ‘ce’ to operate on. / for (seg = 0; seg < MC_HASH_SEGS; seg++) { int index = hash & (MC_HASH_ENTRIES - 1); struct mask_cache_entry *e;
e = &entries[index]; if (e->skb_hash == skb_hash) {
flow = flow_lookup(tbl, ti, ma, key, n_mask_hit, &e->mask_index); if (!flow) e->skb_hash = 0; return flow;}
if (!ce || e->skb_hash < ce->skb_hash)
ce = e; /* A better replacement cache candidate. */hash >>= MC_HASH_SHIFT; }
/ Cache miss, do full lookup. / flow = flow_lookup(tbl, ti, ma, key, n_mask_hit, &ce->mask_index); if (flow) ce->skb_hash = skb_hash;
优点
- WHY,这样子的好处是什么?因为小的冲突比较多吗?难道是为了找一个空的(因为空的值为0)
```c
/*
在长连接的情况下,需要查找2个hash表,可以得到较好的性能。




0x2 Megaflow
通过掩码来实现模糊匹配,每一个掩码对应一个hash表,查找的时候依次查询每一个hash表。Megaflow事实上就是microflow的聚合,将所有具有相同动作的mircroflow聚合在一起。
- 时间复杂度:O(n)的复杂度,其中n为hash表的个数。
- megaflow需要解决几个问题:
- 如何保证匹配准确,防止出错
- 如何最优化模糊匹配
0x3 OpenFlow
流表的匹配采用一个叫做Classifier的分类器进行匹配,一个flow-table对应一个classifier。
数据结构
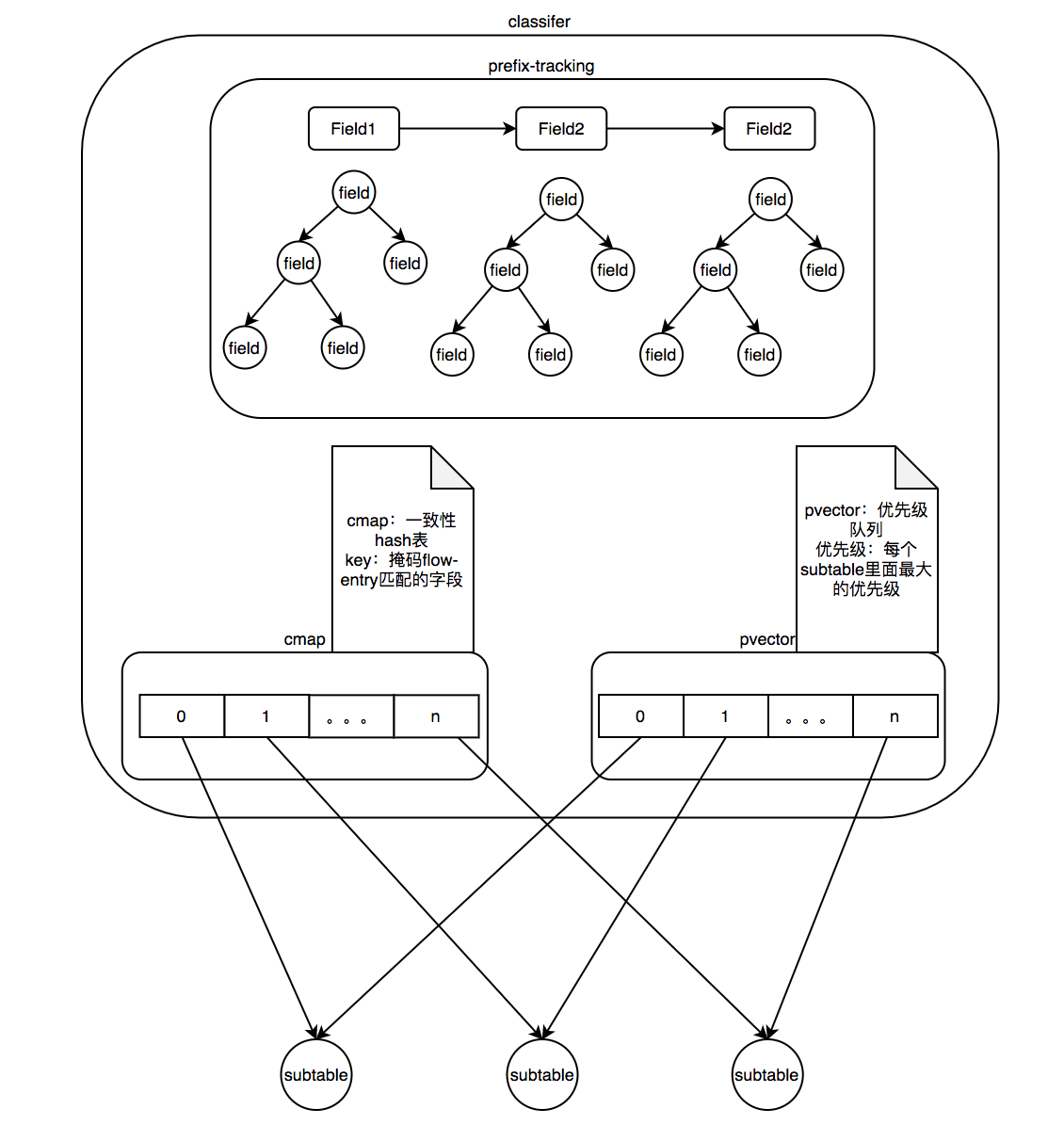
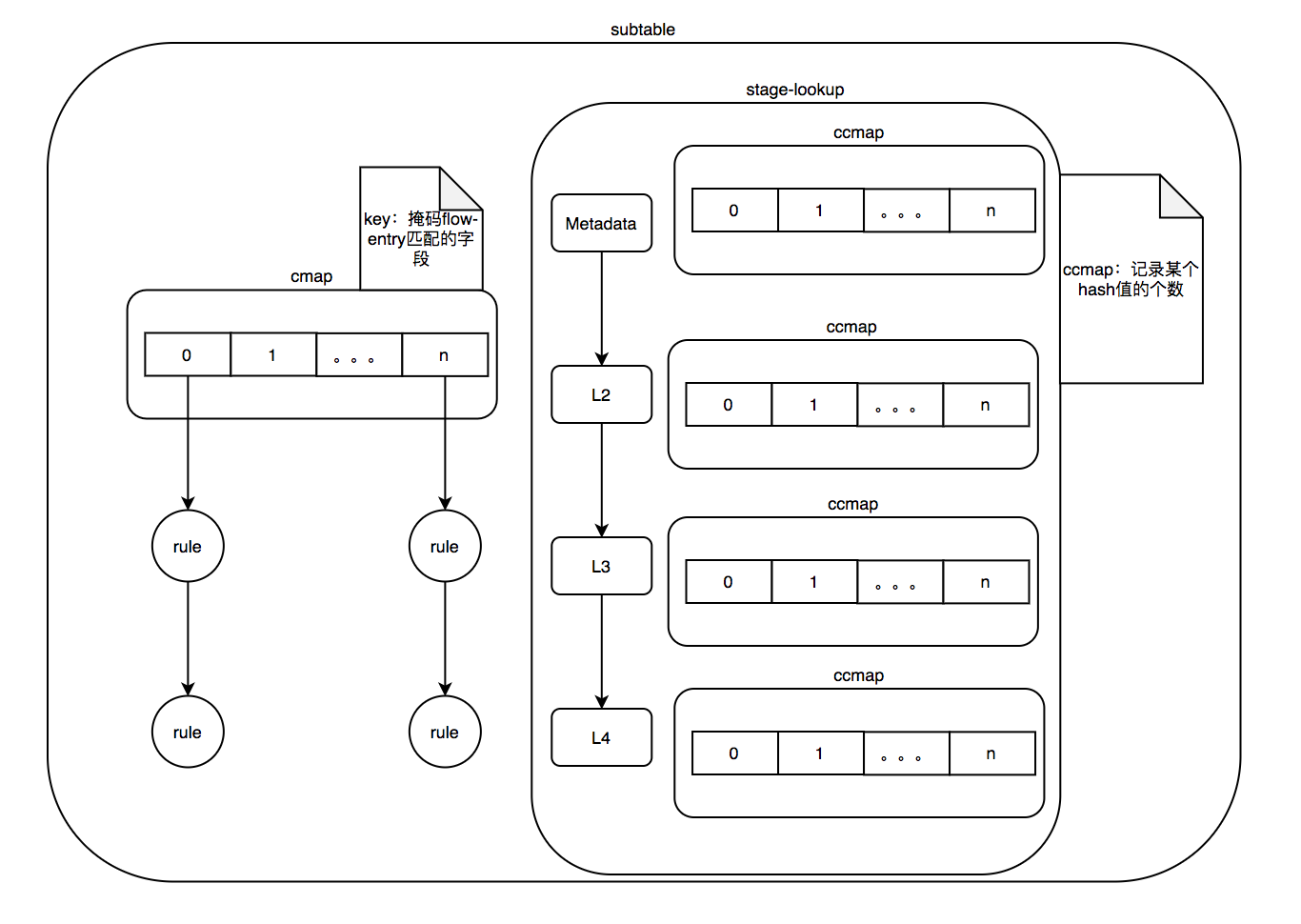
流程图
0x4 资源
- datapath的设计说明书

若有收获,就点个赞吧
0 人点赞
