在之前写过,Flink DataStream API 在进行实时计算的时候,需要先建立相应的DAG环境,然后进行DataStream的读取,进而进行相应的数据实时统计 !!!
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
参考: https://xieyuanpeng.com/2019/02/05/flink-learning-3/
一. 数据读取
1.1 fromElements
从批中读取数据
DataStream<SensorReading> stream = env.fromElements(new SensorReading("sensor_1", 1547718199, 35.80018327300259),new SensorReading("sensor_6", 1547718199, 15.402984393403084),new SensorReading("sensor_7", 1547718199, 6.720945201171228),new SensorReading("sensor_10", 1547718199, 38.101067604893444))// SensorReading 数据流的类型SensorReading('','','')
1.2 readTextFile
从文件中读取数据
// 直接通过相应的路径DataStream<String> stream = env.readTextFile(filePath);// 通过参数params传入carData = env.readTextFile(params.get("input")).map(new TopSpeedWindowing.ParseCarData())
1.3 addsource
addcource 添加数据源,可以添加自定义的数据源
DataStream<String> text = env.addSource(new DataSource())// DataSource为一个自定义的获取数据的函数,在进行自定义的时候,需要使用RichParallelSourceFunction这个方法
SensorSource类:
// 自定义数据源// 自定义数据源,需要完成run & cancel 方法// 示例1import org.apache.flink.streaming.api.functions.source.RichParallelSourceFunction;import java.util.Calendar;import java.util.Random;public class SensorSource extends RichParallelSourceFunction<SensorReading> {private boolean running = true;@Override// SensorReading 最后输出的数据流 类型, srcCtx 用来提交最后的数据流public void run(SourceContext<SensorReading> srcCtx) throws Exception {Random rand = new Random();String[] sensorIds = new String[10];double[] curFTemp = new double[10];for (int i = 0; i < 10; i++) {sensorIds[i] = "sensor_" + i;curFTemp[i] = 65 + (rand.nextGaussian() * 20);}while (running) {long curTime = Calendar.getInstance().getTimeInMillis();for (int i = 0; i < 10; i++) {curFTemp[i] += rand.nextGaussian() * 0.5;srcCtx.collect(new SensorReading(sensorIds[i], curTime, curFTemp[i]));}Thread.sleep(100);}}@Overridepublic void cancel() {this.running = false;}}// 示例2public class GroupedProcessingTimeWindowSample {// 模拟数据源 extends - 继承 数据源private static class DataSource extends RichParallelSourceFunction<Tuple2<String, Integer>> {private volatile boolean isRunning = true;@Override// Flink 在运行时对 Source 会直接调用该方法,该方法需要不断的输出数据,从而形成初始的流// 随机的产生商品类别和交易量的数据public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {Random random = new Random();while (isRunning) {//getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态Thread.sleep((getRuntimeContext().getIndexOfThisSubtask() + 1) * 1000 * 5); // 不知道 是否可以看作是windowString key = "类别" + (char) ('A' + random.nextInt(3));int value = random.nextInt(10) + 1;System.out.println(String.format("Emits\t(%s, %d)", key, value));// 将结果通过ctx.collect 方法进行发送ctx.collect(new Tuple2<String , Integer>(key, value));}}@Override// 当 Flink 需要 Cancel Source Task 的时候会调用该方法public void cancel() {isRunning = false;}}
二. 转换算子
DataStream API针对大多数数据转换操作提供了转换算子。如果你很熟悉批处理API、函数式编程语言或者SQL,那么你将会发现这些API很容易学习。我们会将DataStream API的转换算子分成四类:
- 基本转换算子:将会作用在数据流中的每一条单独的数据上。
- KeyedStream转换算子:在数据有key的情况下,对数据应用转换算子。
- 多流转换算子:合并多条流为一条流或者将一条流分割为多条流。
- 分布式转换算子:将重新组织流里面的事件。
2.1 基本转换算子
基本转换算子会针对流中的每一个单独的事件做处理,也就是说每一个输入数据会产生一个输出数据。单值转换,数据的分割,数据的过滤,都是基本转换操作的典型例子
2.1.1 Map
map算子通过调用DataStream.map()来指定。map算子的使用将会产生一条新的数据流。它会将每一个输入的事件传送到一个用户自定义的mapper,这个mapper只返回一个输出事件,这个输出事件和输入事件的类型可能不一样。
// 行内函数 map 函数 ,它使用 Lambda 表达式进行相应的计算// 1:1env.fromElements(1, 2, 3).map(i -> Tuple2.of(i, i)).returns(Types.TUPLE(Types.INT, Types.INT)).print();// 上面这段代码, 数据为1 2 3 ,map 进行映射处理 计算i->i*i , 最后进行返回,数据格式限制成int ,print打印结果
2.1.2 FILTER
filter转换算子通过在每个输入事件上对一个布尔条件进行求值来过滤掉一些元素,然后将剩下的元素继续发送。一个true的求值结果将会把输入事件保留下来并发送到输出,而如果求值结果为false,则输入事件会被抛弃掉。我们通过调用DataStream.filter()来指定流的filter算子,filter操作将产生一条新的流,其类型和输入流中的事件类型是一样的。
// 1:1DataStream<SensorReading> filteredReadings = readings.filter(r -> r.temperature >= 25);
2.1.3 FLATMAP
flatMap算子和map算子很类似,不同之处在于针对每一个输入事件flatMap可以生成0个、1个或者多个输出元素。事实上,flatMap转换算子是filter和map的泛化。所以flatMap可以实现map和filter算子的功能。
// T: the type of input elements// O: the type of output elements// 最后的输出是一个Collector集合FlatMapFunction[T, O]> flatMap(T, Collector[O]): Unit
public static class IdSplitter implements FlatMapFunction<String, String> {@Overridepublic void flatMap(String id, Collector<String> out) {String[] splits = id.split("_");for (String split : splits) {out.collect(split);}}}// 此时调用的时候DataStream.flatMap(new IdSplitter())// 匿名函数的写法DataStream<String> splitIds = sensorIds.flatMap((FlatMapFunction<String, String>) // 函数名,输入的格式(id, out) -> { for (String s: id.split("_")) { out.collect(s);}})// provide result type because Java cannot infer return type of lambda function// 提供结果的类型,因为Java无法推断匿名函数的返回值类型.returns(Types.STRING); // 返回结果
2.2 键控流转换算子
很多流处理程序的一个基本要求就是要能对数据进行分组,分组后的数据共享某一个相同的属性。DataStream API提供了一个叫做KeyedStream的抽象,此抽象会从逻辑上对DataStream进行分区,分区后的数据拥有同样的Key值,分区后的流互不相关。
针对KeyedStream的状态转换操作可以读取数据或者写入数据到当前事件Key所对应的状态中。这表明拥有同样Key的所有事件都可以访问同样的状态,也就是说所以这些事件可以一起处理。KeyedStream可以使用map,flatMap和filter算子来处理。接下来我们会使用keyBy算子来将DataStream转换成KeyedStream.
2.2.1 keyby — 分流
keyBy通过指定key来将DataStream转换成KeyedStream,基于不同的key,流中的事件将被分配到不同的分区中去。所有具有相同key的事件将会在接下来的操作符的同一个子任务槽中进行处理。拥有不同key的事件可以在同一个任务中处理。但是算子只能访问当前事件的key所对应的状态。keyBy()方法接收一个参数,这个参数指定了key或者keys,有很多不同的方法来指定key。
KeyedStream<SensorReading, String> keyed = readings.keyBy(r -> r.id); // 指定按照r.id为分组依据st = stream.flatMap().keyby()// 对stream进行flatmap中相应的处理之后,利用keyby分组 这个分组指的是对于进来的数据流进行分流 分到不同的流中进行计算
基于key的两种操作:滚动聚合和reduce算子,滚动聚合算子由KeyedStream调用,并生成一个聚合以后的DataStream,例如:sum,minimum,maximum。一个滚动聚合算子会为每一个观察到的key保存一个聚合的值。
2.2.2 滚动聚合算子 — 聚合
常用的滚动聚合算子有:
- sum():在输入流上对指定的字段做滚动相加操作。
- min(): 在输入流上对指定的字段求最小值。
- max(): 在输入流上对指定的字段求最大值。
- minBy():在输入流上针对指定字段求最小值,并返回包含当前观察到的最小值的事件。
- maxBy():在输入流上针对指定字段求最大值,并返回包含当前观察到的最大值的事件。
滚动聚合算子无法组合起来使用,每次计算只能使用一个单独的滚动聚合算子。
DataStream<Tuple3<Integer, Integer, Integer>> inputStream = env.fromElements(new Tuple3(1, 2, 2), new Tuple3(2, 3, 1), new Tuple3(2, 2, 4), new Tuple3(1, 5, 3));// 数据流:// 1, 2, 2// 2, 3, 1// 2, 2, 4// 1,5,3DataStream<Tuple3<Integer, Integer, Integer>> resultStream = inputStream.keyBy(0) // key on first field of the tuple 经过这一步之后,1 2 2 / 1 5 3进入了同一个算子代码槽中进行计算.sum(1); // sum the second field of the tuple in place最后的结果为:key , sum ,elsekey = 1 时的结果: 1 2 2 ,1 7 2 随着数据流不断地进入 不断地进行累加key = 2 时的结果: 2 3 1 , 2 5 1 第三个字段未定义
滚动聚合操作会对每一个key都保存一个状态。因为状态从来不会被清空,所以我们在使用滚动聚合算子时只能使用在含有有限个key的流上面。
2.2.3 REDUCE — 泛化滚动聚合
reduce算子是滚动聚合的泛化实现。它将一个ReduceFunction应用到了一个KeyedStream上面去。reduce算子将会把每一个输入事件和当前已经reduce出来的值做聚合计算。reduce操作不会改变流的事件类型。输出流数据类型和输入流数据类型是一样的。reduce函数可以通过实现接口ReduceFunction来创建一个类。ReduceFunction接口定义了reduce()方法,此方法接收两个输入事件,输入一个相同类型的事件。
// T: the element typeReduceFunction[T]> reduce(T, T): T
DataStream<SensorReading> maxTempPerSensor = keyestream.reduce((r1, r2) -> {if (r1.temperature > r2.temperature) {return r1;} else {return r2;}});
2.3 多流转换算子
许多应用需要摄入多个流并将流合并处理,还可能需要将一条流分割成多条流然后针对每一条流应用不同的业务逻辑
2.3.1 UNION
DataStream.union()方法将两条或者多条DataStream合并成一条具有与输入流相同类型的输出DataStream。事件合流的方式为FIFO方式。操作符并不会产生一个特定顺序的事件流。union操作符也不会进行去重。每一个输入事件都被发送到了下一个操作符。
DataStream<SensorReading> parisStream = ...DataStream<SensorReading> tokyoStream = ...DataStream<SensorReading> rioStream = ...DataStream<SensorReading> allCities = parisStream.union(tokyoStream, rioStream)
2.3.2 CONNECT, COMAP和COFLATMAP
联合两条流的事件是非常常见的流处理需求。例如监控一片森林然后发出高危的火警警报。报警的Application接收两条流,一条是温度传感器传回来的数据,一条是烟雾传感器传回来的数据。当两条流都超过各自的阈值时,报警。DataStream API提供了connect操作来支持以上的应用场景。DataStream.connect()方法接收一条DataStream,然后返回一个ConnectedStreams类型的对象,这个对象表示了两条连接的流。
// first streamDataStream<Integer> first = ...// second streamDataStream<String> second = ...// connect streams 后面<>里添加的是 两个连接的 数据流的类型ConnectedStreams<Integer, String> connected = first.connect(second);
ConnectedStreams提供了map()和flatMap()方法,分别需要接收类型为CoMapFunction和CoFlatMapFunction的参数。以上两个函数里面的泛型是第一条流的事件类型和第二条流的事件类型,以及输出流的事件类型。还定义了两个方法,每一个方法针对一条流来调用。map1()和flatMap1()会调用在第一条流的元素上面,map2()和flatMap2()会调用在第二条流的元素上面。
// IN1: 第一条流的事件类型// IN2: 第二条流的事件类型// OUT: 输出流的事件类型CoMapFunction[IN1, IN2, OUT]> map1(IN1): OUT> map2(IN2): OUTCoFlatMapFunction[IN1, IN2, OUT]> flatMap1(IN1, Collector[OUT]): Unit> flatMap2(IN2, Collector[OUT]): Unit
对两条流做连接查询通常需要这两条流基于某些条件被确定性的路由到操作符中相同的并行实例里面去。在默认情况下,connect()操作将不会对两条流的事件建立任何关系,所以两条流的事件将会随机的被发送到下游的算子实例里面去。这样的行为会产生不确定性的计算结果,显然不是我们想要的。为了针对ConnectedStreams进行确定性的转换操作,connect()方法可以和keyBy()或者broadcast()组合起来使用。
- 与keyby()
```java
DataStream
// keyBy two connected streams keyby算子操作ConnectStream
ConnectedStreams
// alternative: connect two keyed streams connect 连接 两条keystream
ConnectedStreams
无论使用keyBy()算子操作ConnectedStreams还是使用connect()算子连接两条KeyedStreams,**connect()算子会将两条流的含有相同Key的所有事件都发送到相同的算子实例。两条流的key必须是一样的类型和值**,就像SQL中的JOIN。在connected和keyed stream上面执行的算子有访问keyed state的权限。- **broadcast**```javaDataStream<Tuple2<Integer, Long>> one = ...DataStream<Tuple2<Int, String>> two = ...// connect streams with broadcastConnectedStreams<Tuple2<Int, Long>, Tuple2<Int, String>> keyedConnect = first// broadcast second input stream.connect(second.broadcast());
一条被广播过的流中的所有元素将会被复制然后发送到下游算子的所有并行实例中去。未被广播过的流仅仅向前发送。所以两条流的元素显然会被连接处理。
2.4 分布式转换算子
分区操作对应于我们之前讲过的“数据交换策略”这一节。这些操作定义了事件如何分配到不同的任务中去。当我们使用DataStream API来编写程序时,系统将自动的选择数据分区策略,然后根据操作符的语义和设置的并行度将数据路由到正确的地方去。有些时候,我们需要在应用程序的层面控制分区策略,或者自定义分区策略。例如,如果我们知道会发生数据倾斜,那么我们想要针对数据流做负载均衡,将数据流平均发送到接下来的操作符中去。又或者,应用程序的业务逻辑可能需要一个算子所有的并行任务都需要接收同样的数据。再或者,我们需要自定义分区策略的时候。在这一小节,我们将展示DataStream的一些方法,可以使我们来控制或者自定义数据分区策略。
keyBy()方法不同于分布式转换算子。所有的分布式转换算子将产生DataStream数据类型。而keyBy()产生的类型是KeyedStream,它拥有自己的keyed state。
2.4.1 Random
随机数据交换由DataStream.shuffle()方法实现。shuffle方法将数据随机的分配到下游算子的并行任务中去。
2.4.2 Round-Robin
rebalance()方法使用Round-Robin负载均衡算法将输入流平均分配到随后的并行运行的任务中去。下图为round-robin分布式转换算子的示意图。
2.4.3 Rescale
rescale()方法使用的也是round-robin算法,但只会将数据发送到接下来的并行运行的任务中的一部分任务中。本质上,当发送者任务数量和接收者任务数量不一样时,rescale分区策略提供了一种轻量级的负载均衡策略。如果接收者任务的数量是发送者任务的数量的倍数时,rescale操作将会效率更高。rebalance()和rescale()的根本区别在于任务之间连接的机制不同。 rebalance()将会针对所有发送者任务和所有接收者任务之间建立通信通道,而rescale()仅仅针对每一个任务和下游算子的一部分子并行任务之间建立通信通道。rescale的示意图如下。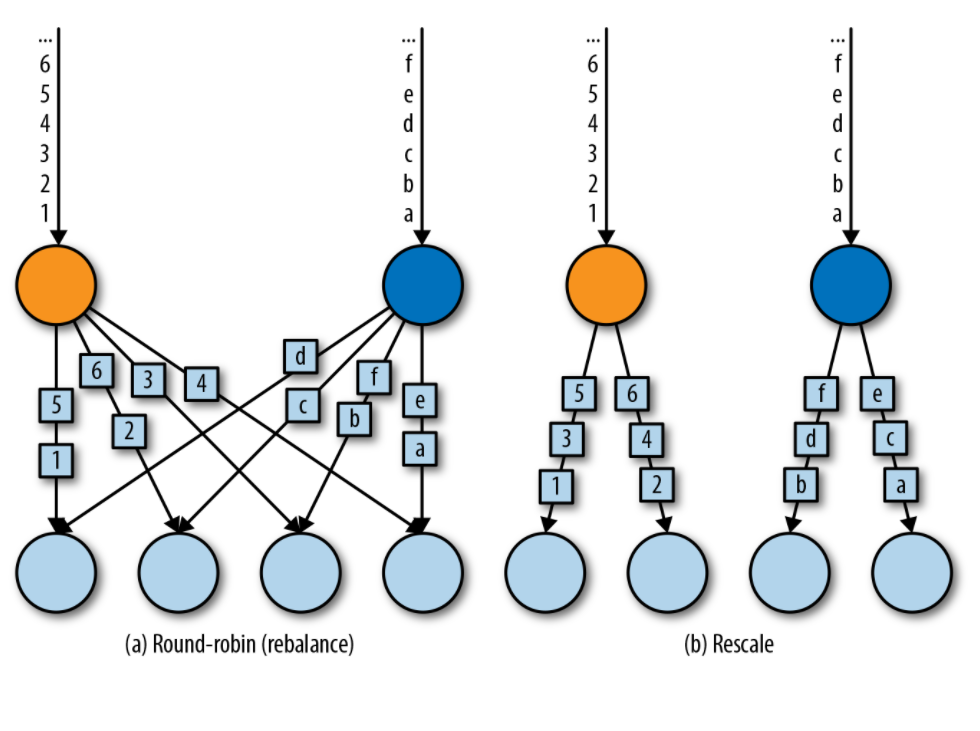
2.4.4 broadcast
broadcast()方法将输入流的所有数据复制并发送到下游算子的所有并行任务中去。
2.4.5 Global
global()方法将所有的输入流数据都发送到下游算子的第一个并行任务中去。这个操作需要很谨慎,因为将所有数据发送到同一个task,将会对应用程序造成很大的压力。
2.4.6 Custom
当Flink提供的分区策略都不适用时,我们可以使用partitionCustom()方法来自定义分区策略。这个方法接收一个Partitioner对象,这个对象需要实现分区逻辑以及定义针对流的哪一个字段或者key来进行分区。
三. 示例
警告类:
public class Alert {
public String message;
public long timestamp;
public Alert() { }
public Alert(String message, long timestamp) {
this.message = message;
this.timestamp = timestamp;
}
public String toString() {
return "(" + message + ", " + timestamp + ")";
}
}
烟雾传感器读数类:
public enum SmokeLevel {
LOW,
HIGH
}
产生烟雾传感器读数的自定义数据源:
public class SmokeLevelSource implements SourceFunction<SmokeLevel> {
private boolean running = true;
@Override
public void run(SourceContext<SmokeLevel> srcCtx) throws Exception {
Random rand = new Random();
while (running) {
if (rand.nextGaussian() > 0.8) {
srcCtx.collect(SmokeLevel.HIGH);
} else {
srcCtx.collect(SmokeLevel.LOW);
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
this.running = false;
}
}
public class MultiStreamTransformations {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<SensorReading> tempReadings = env
.addSource(new SensorSource());
DataStream<SmokeLevel> smokeReadings = env
.addSource(new SmokeLevelSource())
.setParallelism(1);
KeyedStream<SensorReading, String> keyedTempReadings = tempReadings
.keyBy(r -> r.id);
DataStream<Alert> alerts = keyedTempReadings
.connect(smokeReadings.broadcast())
.flatMap(new RaiseAlertFlatMap());
alerts.print();
env.execute("Multi-Stream Transformations Example");
}
public static class RaiseAlertFlatMap implements CoFlatMapFunction<SensorReading, SmokeLevel, Alert> {
private SmokeLevel smokeLevel = SmokeLevel.LOW;
@Override
public void flatMap1(SensorReading tempReading, Collector<Alert> out) throws Exception {
// high chance of fire => true
if (this.smokeLevel == SmokeLevel.HIGH && tempReading.temperature > 100) {
out.collect(new Alert("Risk of fire! " + tempReading, tempReading.timestamp));
}
}
@Override
public void flatMap2(SmokeLevel smokeLevel, Collector<Alert> out) {
// update smoke level
this.smokeLevel = smokeLevel;
}
}
}

若有收获,就点个赞吧
0 人点赞
