1. 基本的开发流程
流处理系统一般采用一种数据驱动的处理方式。它会提前设置一些算子,然后等到数据到达后对数据进行处理。为了表达复杂的计算逻辑,包括 Flink 在内的分布式流处理引擎一般采用 DAG 图来表示整个计算逻辑,其中 DAG 图中的每一个点就代表一个基本的逻辑单元,也就是前面说的算子。由于计算逻辑被组织成有向图,数据会按照边的方向,从一些特殊的 Source 节点流入系统,然后通过网络传输、本地传输等不同的数据传输方式在算子之间进行发送和处理,最后会通过另外一些特殊的 Sink 节点将计算结果发送到某个外部系统或数据库中。
但是实际的情况可能会比较复杂一点,一个算子可能有多个实例,因此在真实的计算的时候,不同算子之间的不同实例间会进行数据交换。只有当算子实例分布到不同进程上时,才需要通过网络进行数据传输,而同一进程中的多个实例之间的数据传输通常是不需要通过网络的。
基于 Apache Storm 用户需要在图中添加 Spout 或 Bolt 这种算子,并指定算子之前的连接方式。这样,在完成整个图的构建之后,就可以将图提交到远程或本地集群运行。与之对比,Apache Flink 的接口虽然也是在构建计算逻辑图,但是 Flink 的 API 定义更加面向数据本身的处理逻辑,它把数据流抽象成为一个无限集,然后定义了一组集合上的操作,然后在底层自动构建相应的 DAG 图。
// 构造表达DAG1. 创建 StreamExecutionEnvironment设置运行环境 + 可以用来设置参数和创建数据源以及提交任务StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();2. 配置数据源读取数据DataStream<String> text = env.readTextFile ("input");DataStream<String> text = env.addSource(new DataSource()) // 参数为 自定义的模拟数据源的方法或者DataStreamSource<String> stream = env.socketTextStream(hostname, port);3.处理数据 进行一系列转换DataStream<Tuple2<String, Integer>> counts = text.flatMap(new Tokenizer()).keyBy(0).sum(1);SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);(这个地方的处理数据的函数 , 可以自定义 也可以 使用 API)4. 配置数据汇写出数据counts.writeAsText("output");5. 提交执行env.execute("Java WordCount from SocketTextStream Example");
// WordCountfinal StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();DataStreamSource<String> stream = env.socketTextStream(hostname, port);SingleOutputStreamOperator<Tuple2<String, Integer>> sum = stream.flatMap(new LineSplitter()).keyBy(0).sum(1);
在 Word Count 例子中,我们首先将每一条记录(即文件中的一行)分隔为单词,这是通过 FlatMap 操作来实现的。调用 FlatMap 将会在底层的 DAG 图中添加一个 FlatMap 算子。然后,我们得到了一个记录是单词的流。我们将流中的单词进行分组(keyBy),然后累积计算每一个单词的数据(sum(1))。计算出的单词的数据组成了一个新的流,我们将它写入到输出文件中。
Flink调用算子机会在DAG图中建立添加相应的算子节点。
前面我们调用的所有方法,都不是在实际处理数据,而是在构通表达计算逻辑的 DAG 图。只有当我们将整个图构建完成并显式的调用 Execute 方法后,框架才会把计算图提供到集群中,接入数据并执行实际的逻辑。
Flink 累计计算, Flink 在进行处理的时候,每一次按照设定的时间窗口进行相应的算子,当新的数据进来之后,在原来的基础上进行相应的计算,达到累计的效果。window主要达到了切分的效果,通过过 Window 操作对流可以按时间或者个数进行一些切分,从而将流切分成一个个较小的分组。具体的切分逻辑可以由用户进行选择。当一个分组中所有记录都到达后,用户可以拿到该分组中的所有记录,从而可以进行一些遍历或者累加操作。这样,对每个分组的处理都可以得到一组输出数据,这些输出数据形成了一个新的基本流。
2. DataStream操作分类
Flink DataStream API 的核心,就是代表流数据的 DataStream 对象。整个计算逻辑图的构建就是围绕调用 DataStream 对象上的不同操作产生新的 DataStream 对象展开的。DataStream 上的操作可以分为四类 :
- 对于单条记录的操作,比如筛除掉不符合要求的记录(Filter 操作),或者将每条记录都做一个转换(Map 操作)
- 对多条记录的操作。比如说统计一个小时内的订单总成交量,就需要将一个小时内的所有订单记录的成交量加到一起。通过 Window 将需要的记录关联到一起进行处
- 对多个流进行操作并转换为单个流,例如,多个流可以通过 Union、Join 或 Connect 等操作合到一起。这些操作合并的逻辑不同,但是它们最终都会产生了一个新的统一的流,从而可以进行一些跨流的操作。
- DataStream 还支持与合并对称的操作,即把一个流按一定规则拆分为多个流(Split 操作),每个流是之前流的一个子集,这样我们就可以对不同的流作不同的处理
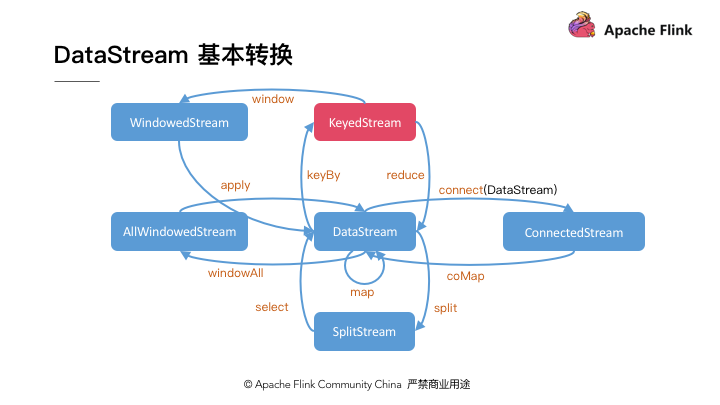
对于普通的 DataStream,我们必须使用 allWindow 操作,它代表对整个流进行统一的 Window 处理,因此是不能使用多个算子实例进行同时计算的。针对这一问题,就需要我们首先使用 KeyBy 方法对记录按 Key 进行分组,然后才可以并行的对不同 Key 对应的记录进行单独的 Window 操作。KeyBy 操作是我们日常编程中最重要的操作之一。
3. DataStream的分组方式
keyby —— 为了能够在多个并发实例上并行的对数据进行处理,我们需要通过 KeyBy 将数据进行分组 ,KeyBy 是在水平分向对流进行切分。使用 KeyBy 进行数据切分之后,后续算子的每一个实例可以只处理特定 Key 集合对应的数据Global: 上游算子将所有记录发送给下游算子的第一个实例。Broadcast: 上游算子将每一条记录发送给下游算子的所有实例。Forward:只适用于上游算子实例数与下游算子相同时,每个上游算子实例将记录发送给下游算子对应的实例。Shuffle:上游算子对每条记录随机选择一个下游算子进行发送。Rebalance:上游算子通过轮询的方式发送数据。Rescale:当上游和下游算子的实例数为 n 或 m 时,如果 n < m,则每个上游实例向ceil(m/n)或floor(m/n)个下游实例轮询发送数据;如果 n > m,则 floor(n/m) 或 ceil(n/m) 个上游实例向下游实例轮询发送数据。PartitionCustomer:当上述内置分配方式不满足需求时,用户还可以选择自定义分组方式。
4. DataStream的类型
Flink DataStream 对像都是强类型的,每一个 DataStream 对象都需要指定元素的类型,Flink 自己底层的序列化机制正是依赖于这些信息对序列化等进行优化。具体来说,在 Flink 底层,它是使用 TypeInformation 对象对类型进行描述的,TypeInformation 对象定义了一组类型相关的信息供序列化框架使用。

public class GroupedProcessingTimeWindowSample {// 模拟数据源 extends - 继承 数据源private static class DataSource extends RichParallelSourceFunction<Tuple2<String, Integer>> {private volatile boolean isRunning = true;@Override// Flink 在运行时对 Source 会直接调用该方法,该方法需要不断的输出数据,从而形成初始的流// 随机的产生商品类别和交易量的数据public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {Random random = new Random();while (isRunning) {//getRuntimeContext()方法提供了函数的RuntimeContext的一些信息,例如函数执行的并行度,任务的名字,以及state状态Thread.sleep((getRuntimeContext().getIndexOfThisSubtask() + 1) * 1000 * 5); // 不知道 是否可以看作是windowString key = "类别" + (char) ('A' + random.nextInt(3));int value = random.nextInt(10) + 1;System.out.println(String.format("Emits\t(%s, %d)", key, value));// 将结果通过ctx.collect 方法进行发送ctx.collect(new Tuple2<>(key, value));}}@Override// 当 Flink 需要 Cancel Source Task 的时候会调用该方法public void cancel() {isRunning = false;}}// 构建图public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(2);// 添加数据源// 基本数据源DataStream<Tuple2<String, Integer>> ds = env.addSource(new DataSource());// 分组数据源 按照第一个字段进行分组KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = ds.keyBy(0);// keyedStream 按照第二个字段进行求和keyedStream.sum(1).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {@Overridepublic Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {return "";}}).fold(new HashMap<String, Integer>(), new FoldFunction<Tuple2<String, Integer>, HashMap<String, Integer>>() {// 利用flod 来维持数据的真实性@Overridepublic HashMap<String, Integer> fold(HashMap<String, Integer> accumulator, Tuple2<String, Integer> value) throws Exception {// hashmap 对于当前的数据进行维护,当有新的记录进来之后进行更新accumulator.put(value.f0, value.f1);return accumulator;}}).addSink(new SinkFunction<HashMap<String, Integer>>() {// 最终结果输出@Overridepublic void invoke(HashMap<String, Integer> value, Context context) throws Exception {// 每个类型的商品成交量System.out.println(value);// 商品成交总量System.out.println(value.values().stream().mapToInt(v -> v).sum());}});env.execute();}}
在此之上还有更上一层的API接口,基于table和SQL

若有收获,就点个赞吧
0 人点赞
