GenericAPIView继承APIView类,支持APIView视图的所有功能,还支持过滤、排序、分页等功能。
- 指定queryset类属性,表示当前接口需要使用到的查询集(查询集对象)
- 指定serializer_class类属性,表示当前接口需要使用到的序列化器类
- 在对应的请求方法中,使用self.get_queryset()方法,获取查询集对象,建议不要直接使用self.queryset
- 可以使用self.get_serializer()方法调用序列化器类,建议不要直接使用self.serializer_class
- GenericAPIView提供get_object方法。其作用与下面的代码类似
try:project_obj = Projects.objects.get(id=pk)except Projects.DoesNotExist:raise Http404
过滤
项目列表页通常有个搜索框,搜索框中我们可以输入内容进行搜索,这里说的过滤就是我们常说的搜索。我们根据name和desc进行搜索。导入filters
from rest_framework import filters
指定过滤引擎和过滤字段
# 指定过滤引擎filter_backends = [filters.SearchFilter]# 过滤的字段search_fields = ['name', 'desc']
完整代码
修改project\views.py```python from django.http import JsonResponse from rest_framework.generics import GenericAPIView from .models import Projects from .serializers import ProjectsModelSerializer from rest_framework.response import Response from rest_framework import status from rest_framework import filters
class ProjectView(GenericAPIView):
# 一般需要指定queryset、serializer_class类属性queryset = Projects.objects.all()serializer_class = ProjectsModelSerializer# 指定过滤引擎filter_backends = [filters.SearchFilter]# 过滤的字段search_fields = ['name', 'desc']# 查询所有数据def get(self, request):# 使用get_queryset()方法获取查询集对象,一般不会写成self.querysetqueryset = self.get_queryset()# filter_queryset对查询对象进行过滤操作queryset = self.filter_queryset(queryset)# 使用get_serializer()方法获取序列化器类,一般不会写成self.serializer_classserializer = self.get_serializer(instance=queryset, many=True)return Response(serializer.data, status=status.HTTP_200_OK)def post(self, request):# request.data:从request中获取请求数据serializer_obj = self.get_serializer(data=request.data)# 调用is_valid(raise_exception=True),校验失败时抛出异常serializer_obj.is_valid(raise_exception=True)serializer_obj.save()return Response(serializer_obj.data, status=status.HTTP_201_CREATED)
class ProjectDetailView(GenericAPIView): queryset = Projects.objects.all() serializer_class = ProjectsModelSerializer
# 查询单个数据def get(self, request, pk):# get_object可以获取模型对象,不需要传入前端传入的外键project_obj = self.get_object()serializer_obj = self.get_serializer(instance=project_obj)return Response(serializer_obj.data, status=status.HTTP_200_OK)# 更新数据def put(self, request, pk):project_obj = self.get_object()serializer_obj = self.get_serializer(data=request.data, instance=project_obj)# 调用is_valid(raise_exception=True),校验失败时抛出异常serializer_obj.is_valid(raise_exception=True)serializer_obj.save()return JsonResponse(serializer_obj.data, status=status.HTTP_201_CREATED)# 删除数据def delete(self, request, pk):project_obj = self.get_object()project_obj.delete()return Response(data={"msg": "刪除成功"}, status=status.HTTP_204_NO_CONTENT)
**增删改查测试过程略**<br />**postman 测试搜索,前端需要传?search=xxx**<br />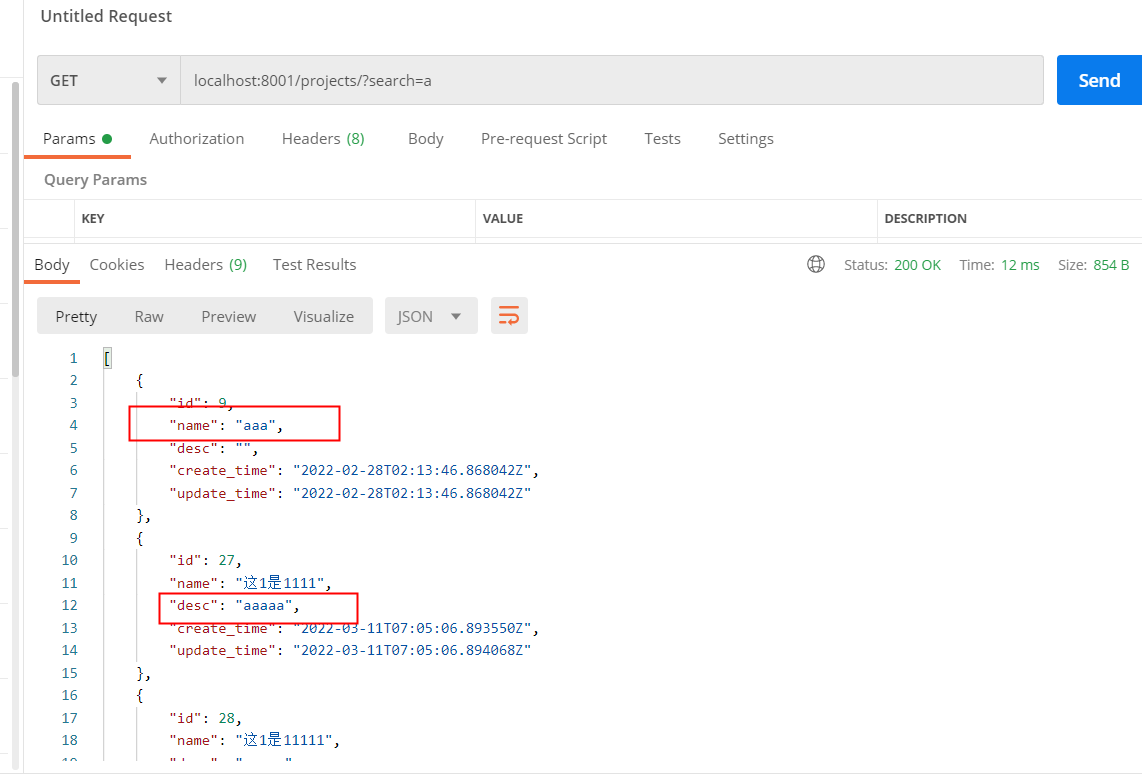<a name="c360e994"></a>## 排序<a name="82cad3f4"></a>### 指定排序引擎和排序字段打开`project\views.py`,修改代码```python# 指定排序引擎filter_backends = [filters.SearchFilter, filters.OrderingFilter]# 指定字段默认升序排序# 如果在字段名称前添加“-”,代表改字段降序# 可以指定多个字段排序ordering_fields = ['name']# ordering_fields = ['name', 'desc']
postman 测试排序,前端需要传ordering=字段名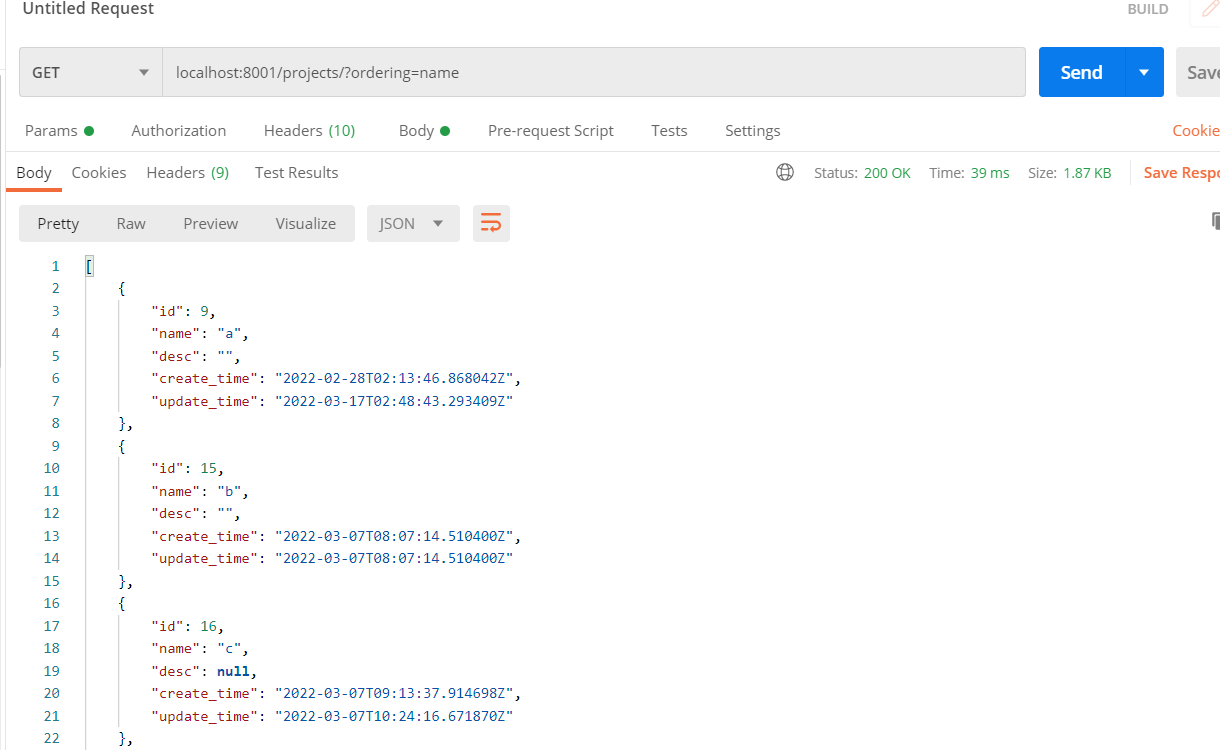
分页
添加DEFAULT_PAGINATION_CLASS
打开caseplatform\setting.py文件,添加如下代码
REST_FRAMEWORK = {DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',# 指定每页显示多少'PAGE_SIZE': 42}
打开project\views.py,修改代码
class ProjectView(GenericAPIView):# 一般需要指定queryset、serializer_class类属性queryset = Projects.objects.all()serializer_class = ProjectsModelSerializer# 指定过滤引擎filter_backends = [filters.SearchFilter, filters.OrderingFilter]# 过滤的字段search_fields = ['name', 'desc']# 指定字段默认升序排序# 如果在字段名称前添加“-”,代表改字段降序# 可以指定多个字段排序ordering_fields = ['name']# ordering_fields = ['name', 'desc']# 查询所有数据def get(self, request):# 使用get_queryset()方法获取查询集对象,一般不会写成self.querysetqueryset = self.get_queryset()# filter_queryset对查询对象进行过滤操作queryset = self.filter_queryset(queryset)# 使用paginate_queryset方法,进行分页操作page = self.paginate_queryset(queryset)if page is not None:# 调用get_serializer,将page作为参数传给instanceserializer = self.get_serializer(instance=page, many=True)# 分页必须调用get_paginated_response方法返回return self.get_paginated_response(serializer.data)# 使用get_serializer()方法获取序列化器类,一般不会写成self.serializer_classserializer = self.get_serializer(instance=queryset, many=True)return Response(serializer.data, status=status.HTTP_200_OK)
注意,如果前端不传page,默认为第一页
使用postman测试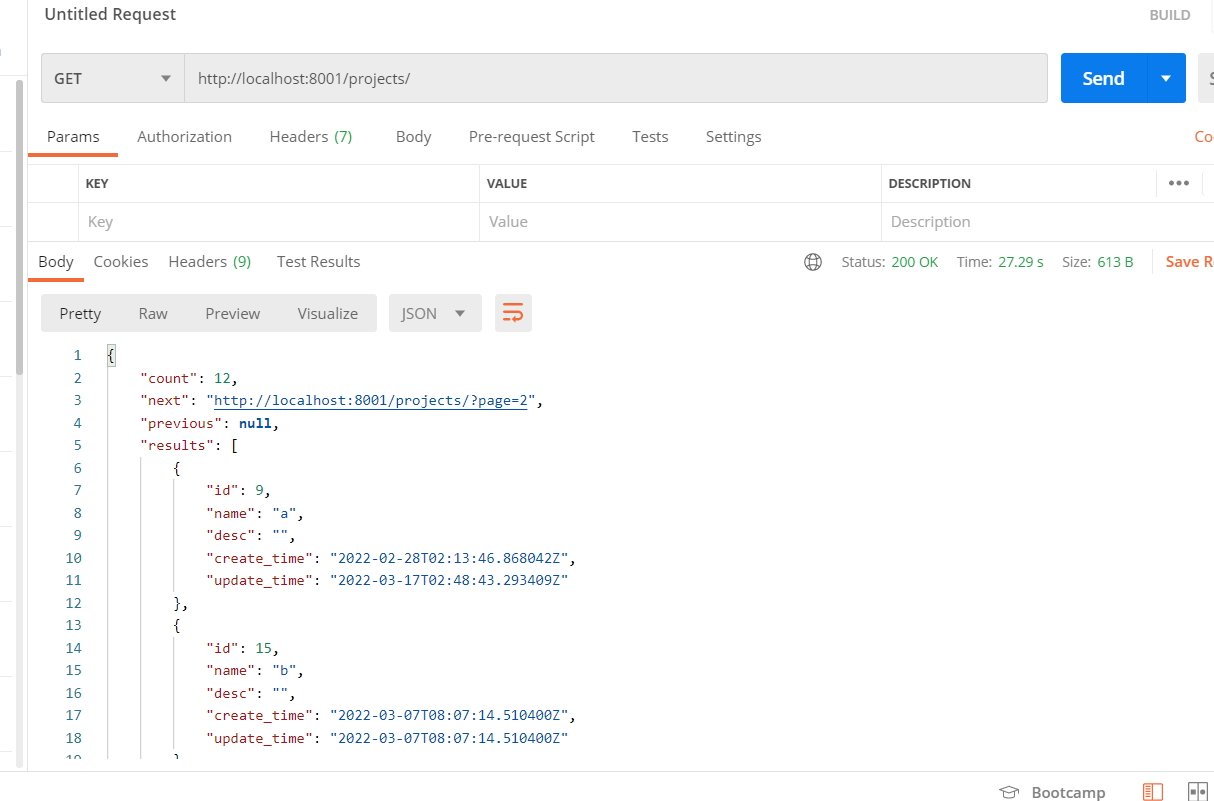

若有收获,就点个赞吧
0 人点赞
