数据库面试题:
1、关系型数据库和非关系型数据库区别?
①数据存储方式不同。关系型和非关系型数据库的主要差异是数据存储的方式。
关系型数据存储是表格式的。因此存储在数据表的行和列中。数据表可以彼此关联协作存储,也容易提取数据。
非关系型数据不适合在存储在数据表的行和列中,而是大块组合在一起。
非关系数据通常存储在数据集中,就像文档、键值对或者图结构。你的数据及其特性是选择数据存取和提取方式的首要影响因素。
②扩展方式不同。
③对事务性的支持不同
如果数据操作需求高事务性或者复杂数据查询控制执行计划,那么传统的SQL数据 库从性能和稳定性方面考虑是你的最佳选择。SQL数据库支持对事物原子性细粒度控制,并且易于回滚事务。
虽然NoSQL数据库也可以使用事务操作,但稳定性方面没法和关系型数据库比较,所以他们真正善良的价值是在操作的扩展性和大数据量处理方面。
2、关系型数据库和非关系型数据库都有哪些?
- 关系型数据库:Oracle、SQL Server、Mysql、Access
- 非关系型数据库:NoSql,redis,Hbase
3、数据库引擎:
数据库存储引擎是数据底层软件组织,数据库管理系统(DBMS)使用数据引擎进行创建、查询、更新和删除数据。
不同的存储引擎提供不同的存储机制、索引技巧、锁定水平等功能、使用不同的存储引擎,还可以获得特定的功能。
现在许多不同的数据管理系统都支持多种不同给的数据引擎。
常见的四种数据库引擎:MyIsam,Memory、InnoDB、Archive;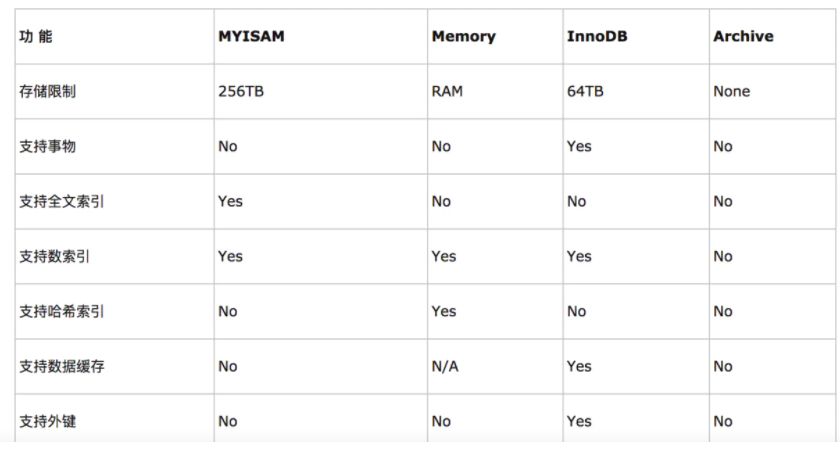
4、触发器的作用?
触发器是一种特殊的存储过程,主要是通过事件来触发而被执行的。他可以强化约束,来维护数据的完整性和一致性,可以跟踪数据库内的操作从而不允许未经许可的更新和变化。可以联级运算。如,某表上的触发器上包含对另一个表的数据操作,而该操作又会导致该表触发器被触发。
5、什么是存储过程?用什么来调用?
存储过程时一个预编译的SQL语句,有点是允许模块化的设计,就是说值需创建一次,以后在该程序中就可以调用多次。如果某次操作需要执行多次SQL,使用存储过程比单纯SQL语句执行要快。
调用:
- 可以通过一个命令对象来调用存储过程。
- 可以供外部程序调用,比如:Java程序。
6、视图
定义:是一种虚拟的表,具有和物理表相同的功能。可以对视图进行增、改、查、操作,视图通常是有一个表或者多个表的行或列的子集。对视图的修改会影响基本表。它使得我们获取数据更容易,相比多表查询。
视图的优缺点:
优点:
①对数据库的访问,因为视图可以有选择性的选取数据库里的一部分。
②用户通过简单的查询可以从复杂查询中得到结果。
③维护数据的独立性,视图可以从多个表检索数据。
④对于相同的数据可以产生不同的视图。
缺点:
①性能:查询视图时,必须把视图的查询转换成对基本表的查询,如果这个视图是由一个复杂的多表查询定义,那么,就无法更改数据。
7、drop,truncate、delete区别:
最基本:
①drop表直接删除表。
②truncate:删除表中的数据,在插入是自增长ID又从1开始。
③delete:删除表中数据。
8、什么是临时表?临时表什么时候删除?
①临时表可以手动删除:
Drop temporary table if exists temp_tb;
②临时表只在当前连接可见,当关闭连接时,MySQL自动回删除表并释放所有空间。因此在不同的连接中可以创建同名的临时表,并且操作属于本连接的临时表。
9、SQL语言分类:
主要分为四大类:
①数据查询语言:DQL
基本结构:select子句、from子句、where子句组成的查询块。
②数据操作语言DML
主要有三种形式:插入:insert、更新:update、删除:delete。
③数据定义语言:DDL
一般用来创建数据库中各种对象:如表、视图、索引、同义词、聚簇等。
Create table/view/index/syn/cluster
④数据控制语言:DCL
一般用来授予权限或回收访问数据库的某种特权,并控制数据库操纵事务发生的时间及效果,对数据库实行监视等。
①授权:grant
②rollback [work] to [savepoInt]:回退到某一点。回滚:tollback;
③commit:提交。
10、count(*)、count(1)、count(column)的区别:
①count():对行的数目进行计算包含null
②count(column):对特定的列的值具有行数进行计算,不包含null值。
③count(),还有一种使用方式,count(1)这个用法和count()的结果是一样的。
11、事务:
定义:事务是对数据库中一系列操作进行统一的回滚或者提交的操作,主要用来保证数据的完整性和一致性。
①事务四大特性:ACID
原子性、一致性、隔离性、持久性
②事务并发问题:
脏读、不可重复读、幻读
注意:不可以重复读和幻读跟容易混淆,不可以重复读侧重于修改,幻读侧重于新增或删除。
解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
③事务隔离级别:
未提交读、不可重复读、可重复读、串行化

若有收获,就点个赞吧
0 人点赞
