Java之所以可以“一次编译,到处运行”,一是因为JVM针对各种操作系统、平台都进行了定制,二是因为无论在什么平台,都可以编译生成固定格式的字节码(.class文件)供JVM使用。因此,也可以看出字节码对于Java生态的重要性。之所以被称之为字节码,是因为字节码文件由十六进制值组成,而JVM以两个十六进制值为一组,即以字节为单位进行读取。在Java中一般是用javac命令编译源代码为字节码文件。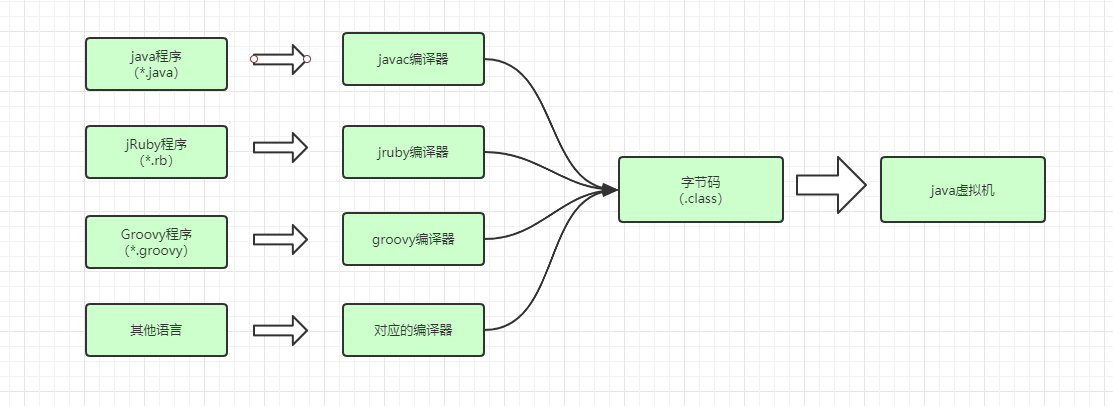
一、字节码结构
.java文件通过javac编译后将得到一个.class文件,class文件中的信息是一项一项排列的, 每项数据都有它的固定长度, 有的占一个字节, 有的占两个字节, 还有的占四个字节或8个字节, 数据项的不同长度分别用u1, u2, u4, u8表示, 分别表示一种数据项在class文件中占据一个字节, 两个字节, 4个字节和8个字节。
比如编写一个简单的ByteCodeDemo类
public class ByteCodeDemo {private int a = 1;public ByteCodeDemo() {}public int add() {int b = 2;int c = this.a + b;System.out.println(c);return c;}}
其16进制的字节码文件如下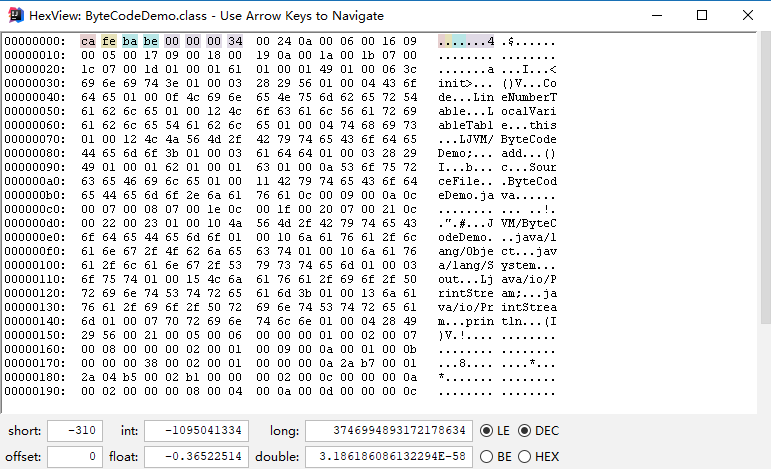
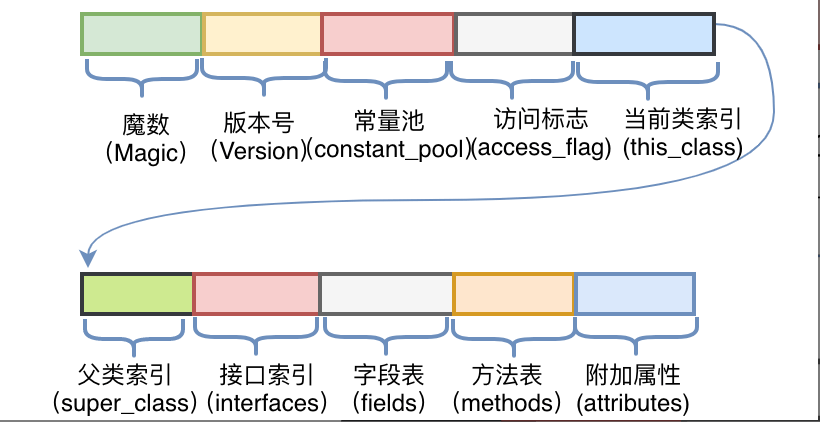
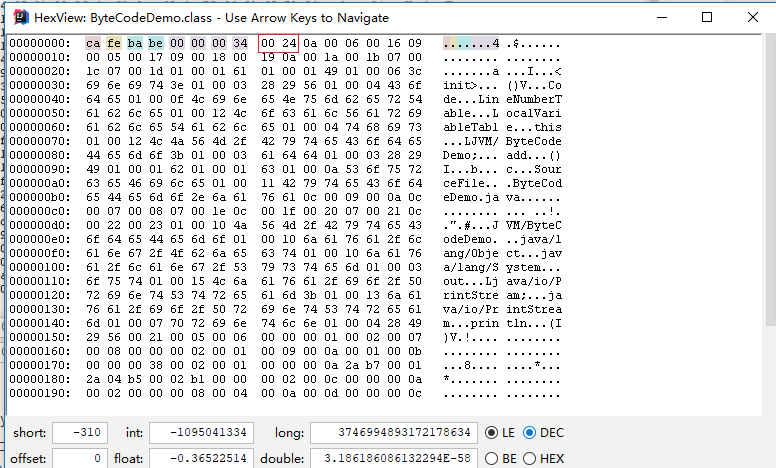
编译后生成ByteCodeDemo.class文件,打开后是一堆十六进制数,按字节为单位进行分割后展示如图2右侧部分所示。上文提及过,JVM对于字节码是有规范要求的,那么看似杂乱的十六进制符合什么结构呢?JVM规范要求每一个字节码文件都要由十部分按照固定的顺序组成,整体结构如图3所示。
二、魔数(Magic Number)
所有的.class文件的前四个字节都是魔数,魔数的固定值为:0xCAFEBABE。魔数放在文件开头,JVM可以根据文件的开头来判断这个文件是否可能是一个.class文件,如果是,才会继续进行之后的操作。
有趣的是,魔数的固定值是Java之父James Gosling制定的,为CafeBabe(咖啡宝贝),而Java的图标为一杯咖啡。很多文件存储标准中都用魔数进行身份标识,如图片gif,jpeg都在文件头部中存储着魔数。
三、版本号(Version)
版本号为魔数之后的4个字节,前两个字节表示次版本号(Minor Version),后两个字节表示主版本号(Major Version)。上图2中版本号为“00 00 00 34”,次版本号转化为十进制为0,主版本号转化为十进制为52,在Oracle官网中查询序号52对应的主版本号为1.8,所以编译该文件的Java版本号为1.8.0。
四、常量池(Constant Pool)
紧接着主版本号之后的字节为常量池入口。常量池中存储两类常量:字面量与符号引用。
- 字面量:为代码中声明为Final的常量值,文本字符串,8大基本数据类型
- 符号引用:如类和接口的全局限定名、字段的名称和描述符、方法的名称和描述符。
简单说明一下,字面量,变量、常量
int a; //变量final int b = 10; //b为常量,10为字面量string str = “hello world!”; // str 为变量,hello world!为字面量
符号引用:
常量池整体上分为两部分:常量池计数器以及常量池数据区,如下图所示:
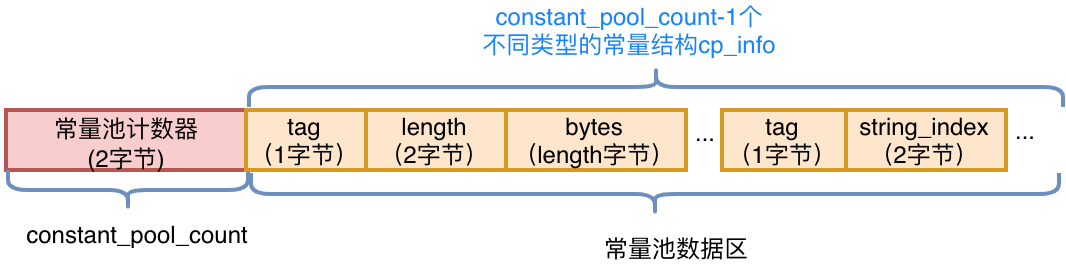
常量池计数器(constant_pool_count):由于常量的数量不固定,所以需要先放置两个字节来表示常量池容量计数值。图2中示例代码的字节码前10个字节如下图5所示,将十六进制的24转化为十进制值为36,排除掉下标“0”,也就是说,这个类文件中共有35个常量。
常量池数据区:数据区是由(constant_pool_count-1)个cp_info结构组成,一**个cp_info**结构对应一个常量。在字节码中共有14种类型的cp_info(如下图6所示),每种类型的结构都是固定的。
具体以CONSTANT_utf8_info为例,它的结构如下图7左侧所示。首先一个字节“tag”,它的值取自上图6中对应项的Tag,由于它的类型是utf8_info,所以值为“01”。接下来两个字节标识该字符串的长度Length,然后Length个字节为这个字符串具体的值。从图2中的字节码摘取一个cp_info结构,如下图7右侧所示。将它翻译过来后,其含义为:该常量类型为utf8字符串,长度为一字节,数据为“a”。

4.1 字面量
字面量为为代码中声明为Final的常量值,文本字符串,8大基本数据类型
举例:**
int a; //变量final int b = 10; //b为常量,10为字面量string str = “hello world!”; // str 为变量,hello world!为字面量
4.2 符号引用
然后我们现在来看,具体的上面的例子中的第一个常量池
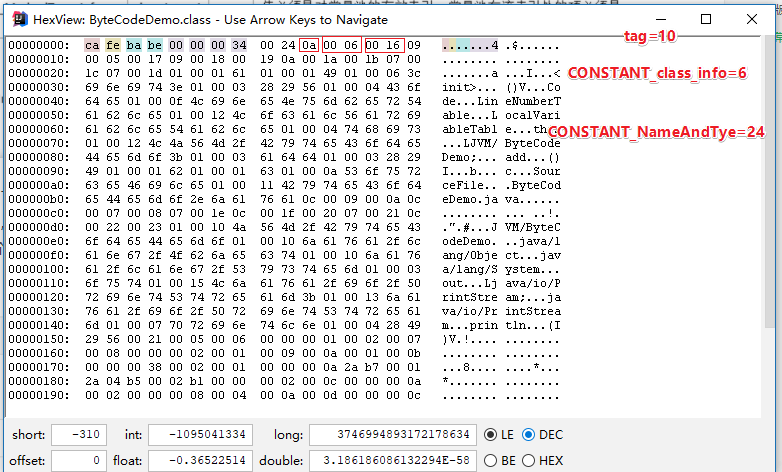
- 0x0A的十进制值为10 ,代表的是CONSTANT_Methodref_info的tag
- 0x0003和0x0011是该常量池项的两个部分:class_index和name_and_type_index。这两部分分别都是常量池下标,引用着另外两个常量池项。
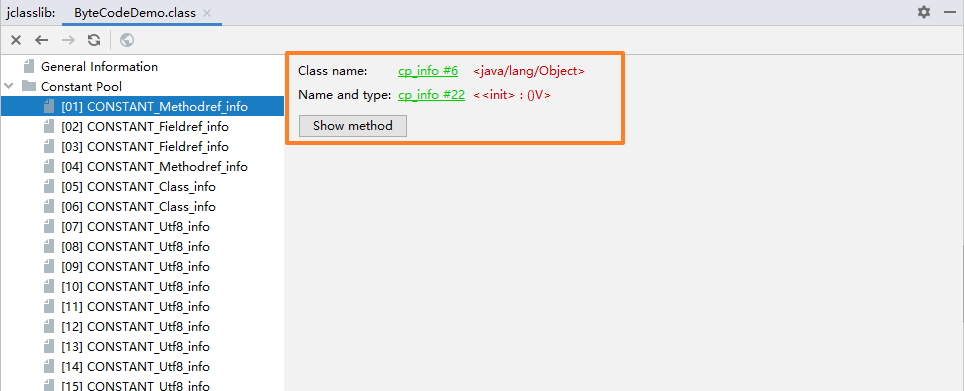
顺着这条线索把能传递引用到的常量池项都找出来,会看到(按深度优先顺序排列):
#1 = Methodref #6.#22 // java/lang/Object."<init>":()V#6 = Class #29 // java/lang/Object#9 = Utf8 <init>#10 = Utf8 ()V#22 = NameAndType #9:#10 // "<init>":()V#29 = Utf8 java/lang/Object
把引用关系画成一棵树的话:
#1 = Methodref java/lang/Object."<init>":()V/ \#6 = Class #22 = NameAndType <init>:()V| / \#29 = Utf8 #9 = Utf8 <init> #10 = Utf8 ()Vjava/lang/Object
由此可以看出,Class文件中指令操作数经过几层间接之后,最后都是由字符串来表示的。这就是Class文件里的“符号引用”的实态:带有类型(tag) / 结构(符号间引用层次)的字符串。
依据知乎上的优质的回答,用通俗的语言解释一下符号引用:
第一次运行的时候,发现指令没有被解析,根据指令去把常量池中有关系的所有项找出来,得到以“UTF-8”编码描述的此方法所属的“类,方法名,描述符”的常量池项,这就是“符号引用”。
符号引用就是字符串,这个字符串包含足够的信息:以供实际使用时可以找到相应的位置。你比如说某个方法的符号引用,如:“java/io/PrintStream.println:(Ljava/lang/String;)V”。里面有类的信息,方法名,方法参数等信息。
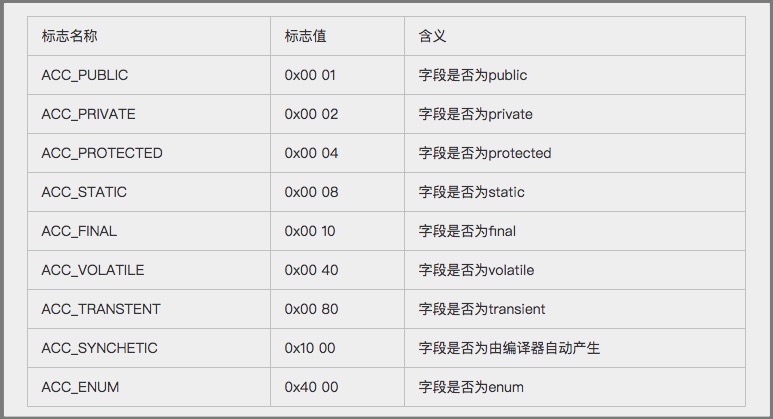
五、访问标志(access_flag)
访问标志: 常量池结束之后的两个字节,描述该Class是类还是接口,以及是否被Public、Abstract、Final等修饰符修饰。
JVM规范规定了如下图9的访问标志(Access_Flag)。需要注意的是,JVM并没有穷举所有的访问标志,而是使用按位或操作来进行描述的,比如某个类的修饰符为Public Final,则对应的访问修饰符的值为ACC_PUBLIC | ACC_FINAL,即0x0001 | 0x0010=0x0011。
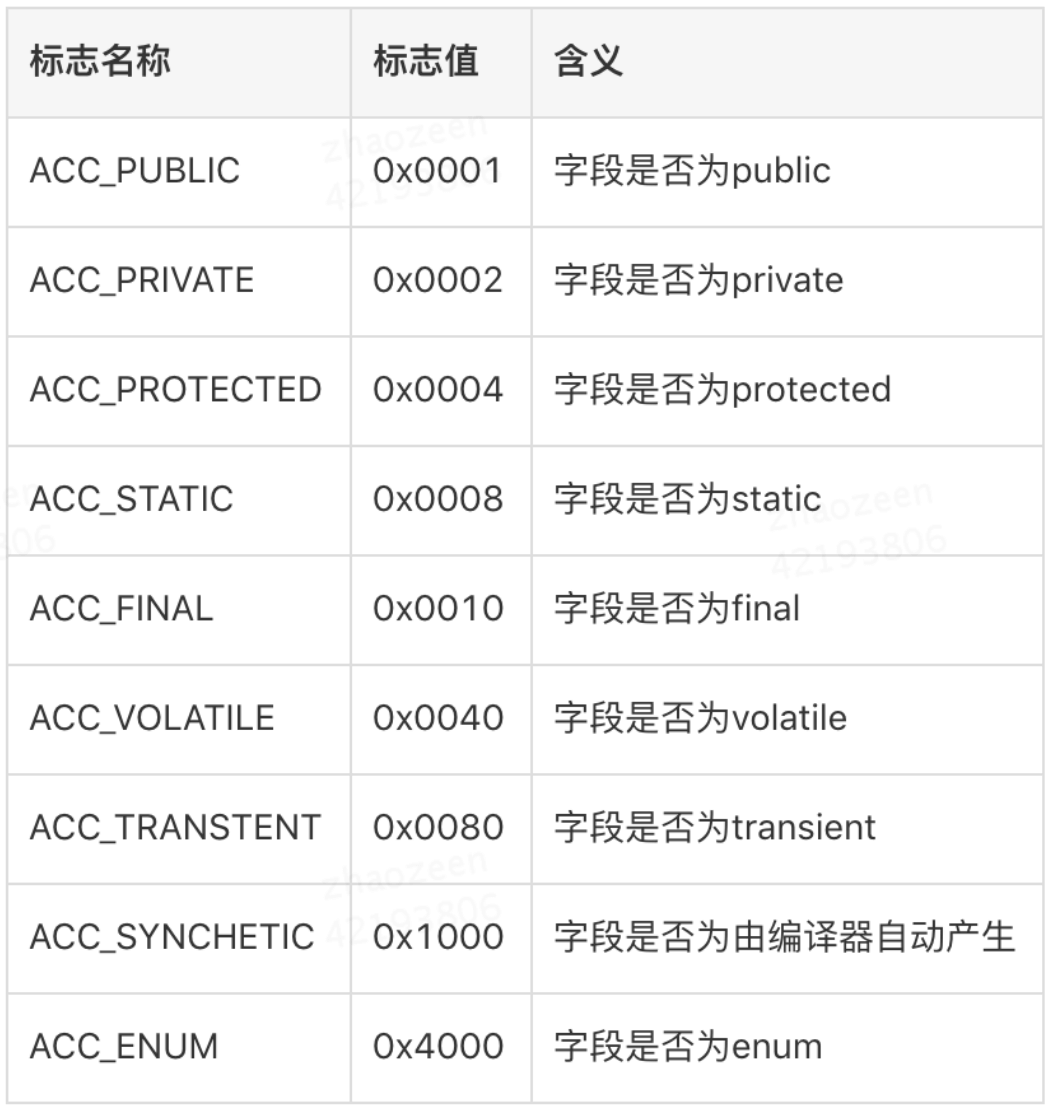
5.1 访问标志转为16进制解释
访问标志:实际上就是一系列组合,因为有16位所以共有16个标志可以使用,但是目前就定义了8个,剩下的估计是给jdk9和10……预留的吧。这8个如图所示。

5.2 测试代码
java代码还是ByteCodeDemo:
package JVM;public class TestDemo {}
反编译的class文件: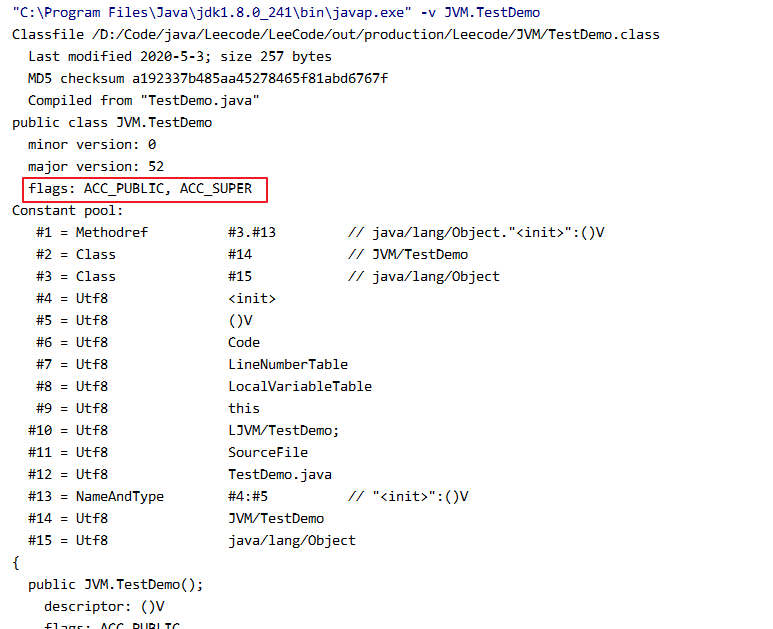
我们发现这里flags为: ACC_PUBLIC, ACC_SUPER,那这么推算那么十六进制应该是0021,占用2个字节。查看16进行数据。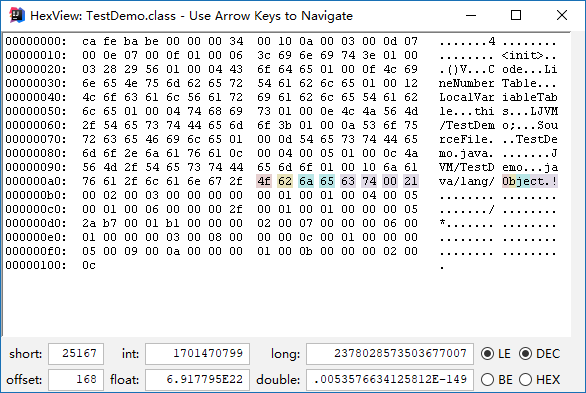
六、 类索引、父类索引、接口索引
6.1 概念
在 .class 文件中由这三项数据来确定这个类的继承关系。
1、类索引:u2 数据类型,用于确定这个类的全限定名(包名+类名)。
2、父类索引:u2 数据类型,用于确定这个类的父类的全限定名(包名+类名)。
3、接口索引:u2 数据类型的集合,用于描述类实现了哪些接口,这些被实现的接口将按照 implements 语句后的顺序从左至右排列在接口索引集合中。
接口索引集合分为两部分,第一部分表示接口计数器(interfaces_count),是一个 u2 类型的数据,第二部分是接口索引表表示接口信息,紧跟在接口计数器之后。
若一个类实现的接口为 0,则接口计数器的值为 0,接口索引表不占用任何字节。
6.2 测试代码
package JVM;public class TestDemo {}
同样生成class文件,然后查看16进制数据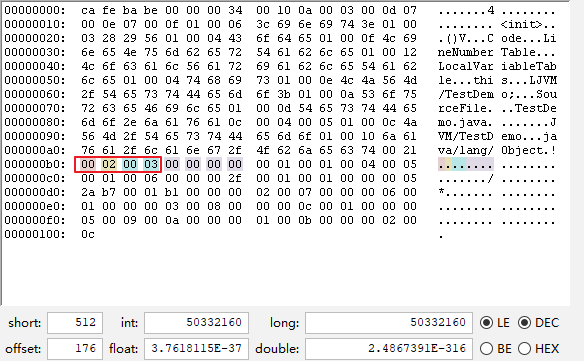
我们看到该类的类索引在常量池0002位置 ,父类索引在常量池0003位置,接口为0000代表该类没有实现任何接口。
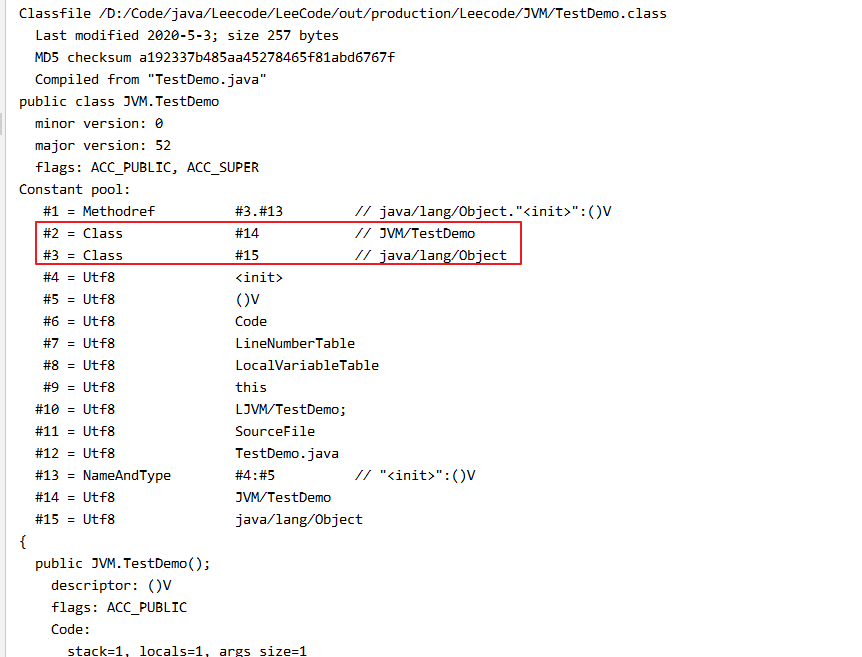
常量池0002就是当前类,0003父类为默认继承了老祖宗Object。
七、字段表(fields)
字段表:用于描述接口或者类中声明的变量,字段包括类级(static)以及实例级变量,但是不包括局部变量(方法内部变量)。字段表的范围需要注意
7.1 概念
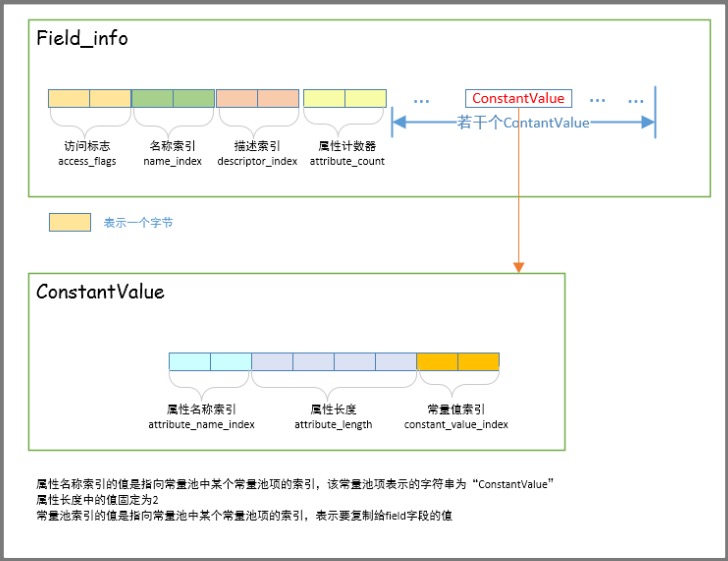
字段表集合:包括了字段计数器和字段数据区如图:
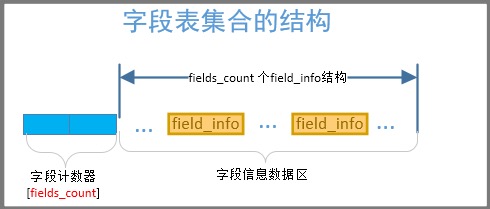
Field_info: 依次包含访问标志(access_flags)、名称索引(name_index)、描述符索引(descriptor_index)、属性表集合(attributes)几项。
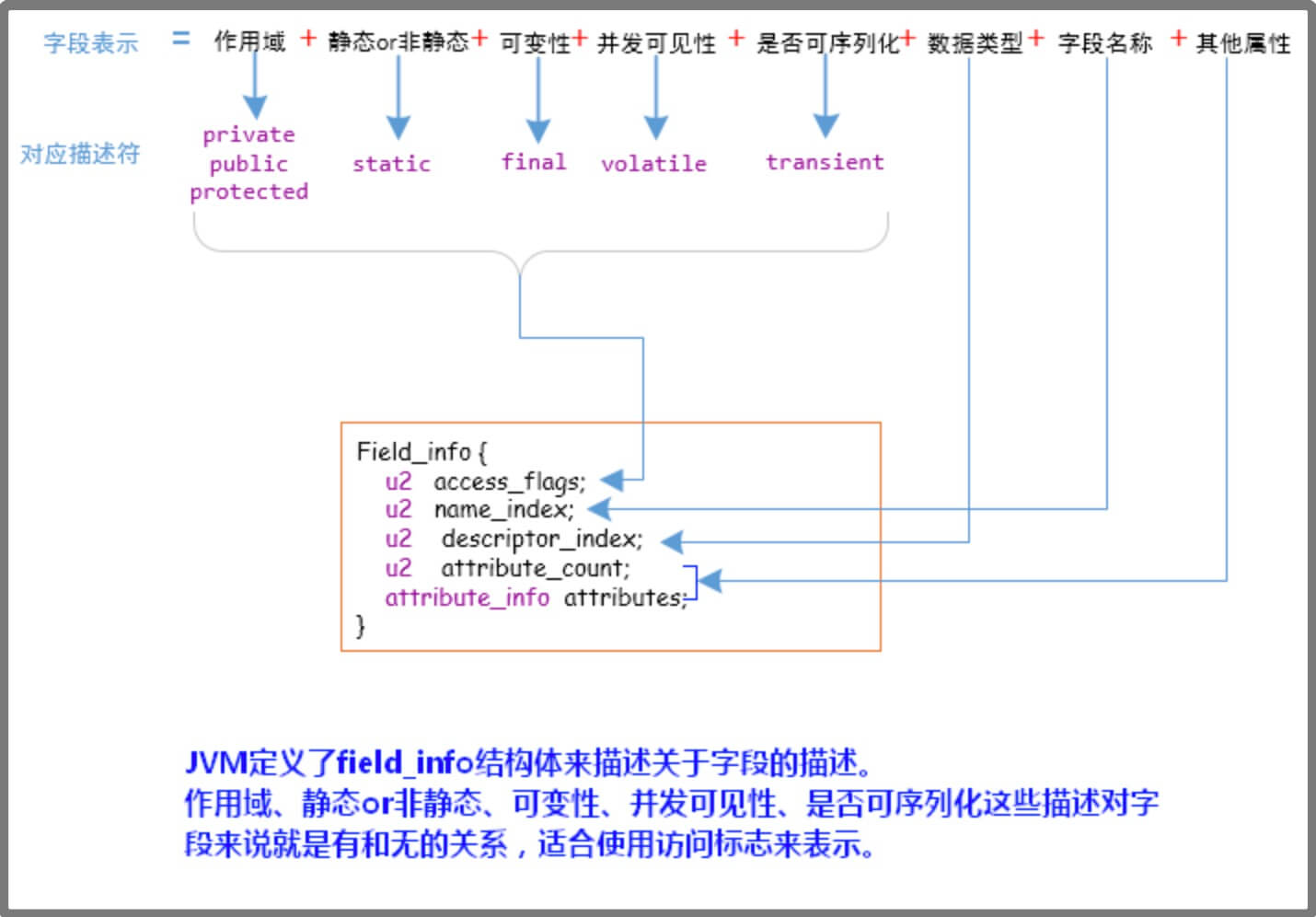
字段修饰符放在access_flags项目中,它与类中的access_flags项目是非常相似的,都是一个u2的数据类型.
跟随access_flags标志的是两项索引值:name_index和descriptor_index,它们都是对常量池的引用,分别代表着字段的简单名称以及字段方法和方法的描述符。
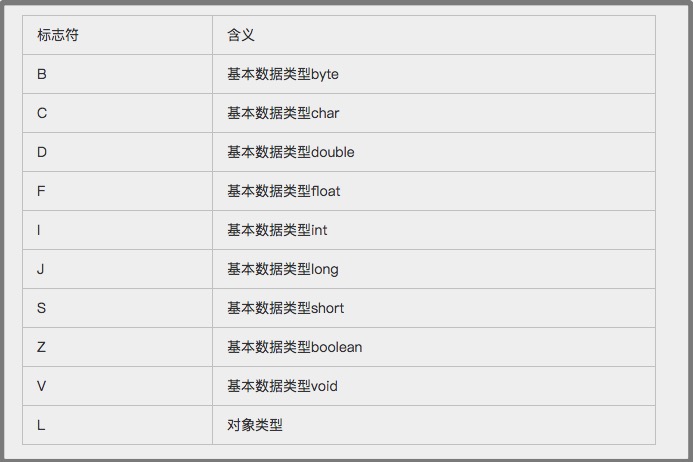
描述符的作用:是用来描述字段的数据类型,方法的参数列表(包括数量,类型以及顺序)和返回值。描述符规则: 基本数据类型以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符加L加对象名的全限定名来表示:
7.2 属性表集合——-静态field字段的初始化
在定义属性字段的过程中,我们有时候会很自然地对 属性字段 直接赋值,如下所示:
public static final int MAX=100;public int count=0;
对于虚拟机而言,上述的两个属性字段赋值的时机是不同的:
- 对于非静态(即无static修饰)的属性字段的赋值将会出现在实例构造方法()中
- 对于静态的属性字段,有两个选择:1、在静态构造方法()中进行;2 、使用ConstantValue属性进行赋值。
Sun javac编译器对于 静态属性字段 的初始化赋值策略
- 如果使用final和static**同时修饰一个属性字段,并且这个字段是基本类型或者String类型的,那么编译器在编译这个字段的时候,会在对应的field_info**结构体中增加一个
ConstantValue类型的结构体,在赋值的时候使用这个ConstantValue进行赋值。 - 如果该属性字段并没有被final修饰,或者不是基本类型或者String类型,那么将在类构造方法()中赋值。
对于上述的public static final init MAX=100; javac编译器在编译此属性字段构建field_info结构体时,除了访问标志、名称索引、描述符索引外,会增加一个ConstantValue类型的属性表。
7.3 测试代码
public class Simple {private transient static final String str ="This is a test";}
对应的字节码文件: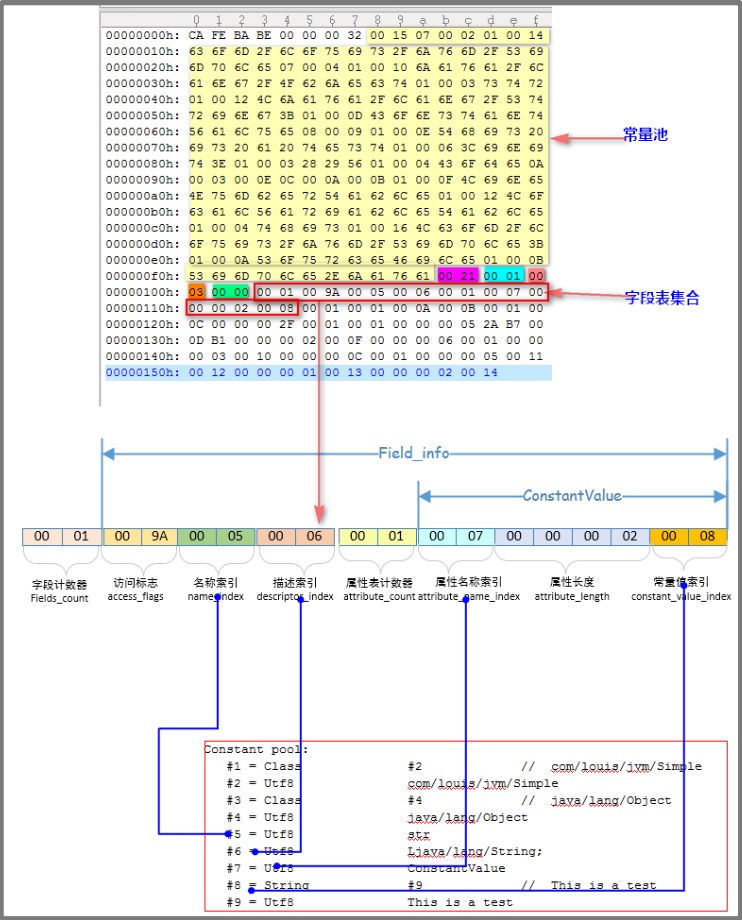
说明:
1、字段计数器中的值为0x0001,表示这个类就定义了一个属性字段 2、 字段的访问标志是0x009A,这个字段的标志符有:ACC_TRANSIENT、ACC_FINAL、ACC_STATIC、ACC_PRIVATE; 3、 名称索引中的值为0x0005,指向了常量池中的第5项,为“str”,表明这个属性字段的名称是str; 4、描述索引中的值为0x0006,指向了常量池中的第6项,为”Ljava/lang/String;“,表明这个field字段的数据类型是java.lang.String类型; 5、属性表计数器中的值为0x0001,表明field_info还有一个属性表; 6、属性表名称索引中的值为0x0007,指向常量池中的第7项,为“ConstantValue”,表明这个属性表的名称是ConstantValue,即属性表的类型是ConstantValue类型的; 7、属性长度中的值为0x0002,因为此属性表是ConstantValue类型,它的值固定为2; 8、常量值索引 中的值为0x0008,指向了常量池中的第8项,为CONSTANT_String_info类型的项,表示“This is a test” 的常量。在对此field赋值时,会使用此常量对field赋值。
第二个例子:
public class HuangHe {public String name = "huanghe";private Integer age = 18;public static final String sex = "男";}
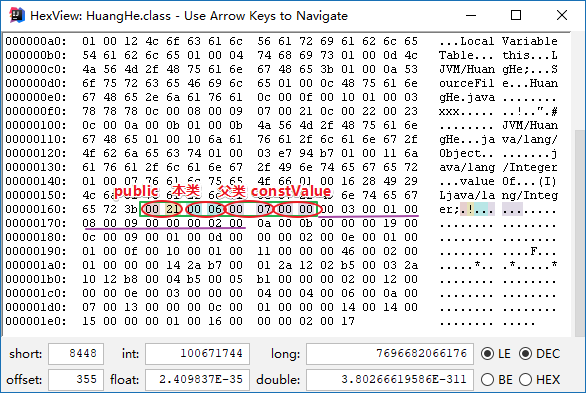
其中紫色的下划线的是字段集合相关的
点击查看【processon】
八、方法集合(methods)
8.1 概念
方法表集合:方法表集合和属性表集合其实很相似,都是由一个计数器(方法)和若干个方法表构成,只不过方法表的结构相对复杂很多。方法表的结构体:访问标志(access_flags)、名称索引(name_index)、描述索引(descriptor_index)、属性表(attribute_info)集合组成。
method_info {u2 access_flags;u2 name_index;u2 descriptor_index;u2 attributes_count;attribute_info attributes[attributes_count];}
1)、访问标志
不多说了,和属性中的其实差不多,只是有些修饰符不一样。

2)、名称索引
就是指这个方法的名称。如:’public void getXX()’中,getXX就是名称索引。名称索引占两个字节,这个方法的名称以UTF-8格式的字符串存储在这个常量池项中。
3)、描述索引
指这个方法的返回值,方法内参数信息。一个方法的描述包含若干个参数的数据类型和返回值的数据类型。
4)、 属性表(attribute_info)集合
下面讲
8.2 属性表集合
1、概述
在Class文件、字段表(在第7小节刚刚阐述了的)、方法表都可以携带自己的属性表集合**,用于描述某些场景专有的信息。
在方法表中, 属性表集合记录了某个方法的一些属性信息,这些信息包括:
- 这个方法的代码实现,即
方法的可执行的机器指令 - 这个方法声明的要
抛出的异常信息 - 这个方法是否
被@deprecated注解表示 - 这个方法是否是
编译器自动生成的
属性表(attribute_info)结构体的一般结构如下所示:
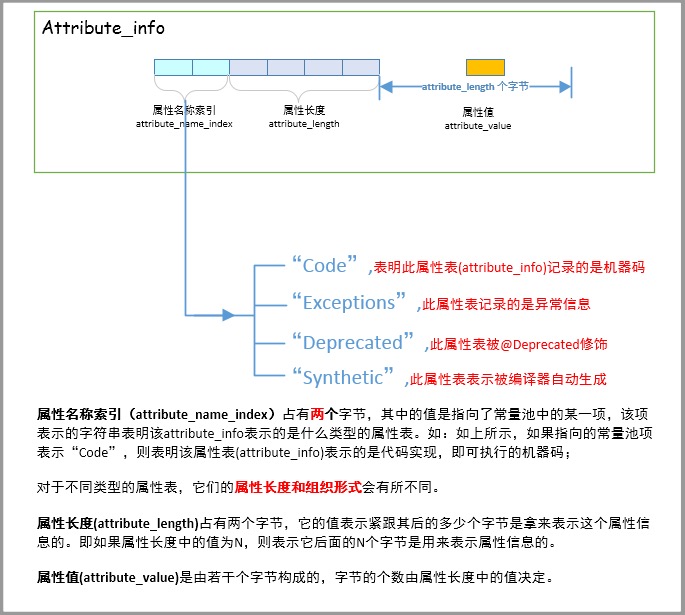
属性表占着非常大的一部分且定义了众多属性,上面只列举了4个,查看完成的:JDK1.7版本中21项属性表集合简要介绍
下面介绍两个重要的属性
8.3 Code属性
code属性比较复杂,它是经过编译器编译成字节码指令之后的数据。就是说java程序中的方法体经过javac编译器处理后,最终变成字节码存储在Code属性内。
并非所有方法表都有这个属性,接口和抽象类就没有【没有方法体】。 Code属性是Class文件中最重要的一个属性,在Class文件中,Code属性用于描述代码,所有的其它数据项目都用来描述元数据,了解code属性对了解字 节码执行引擎来说是必要基础。
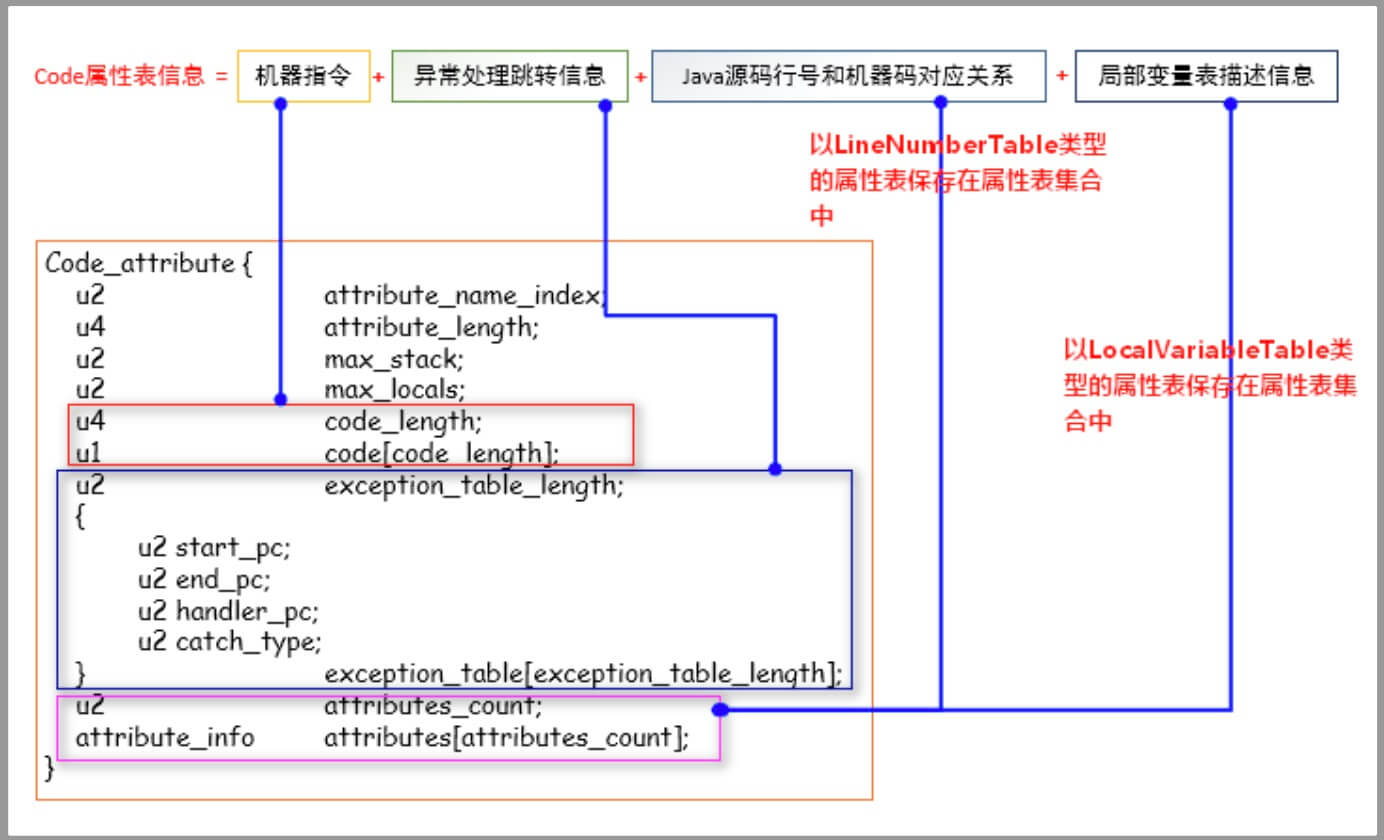
上图中的局部变量表是指class文件的一个属性,而不是上文中所说的 java 栈中的每个栈帧的局部变量表,在class文件的局部变量表中,显示了每个变量的作用域范围,所在槽位的索引(index列)、变量名(name列)和数据类型列(J表示long型)。
Code属性表的组成部分:
1、机器指令code**
目前的JVM使用一个字节表示机器操作码,即对JVM底层而言,它能表示的机器操作码不多于2的 8 次方,即 256个。class文件中的机器指令部分是class文件中最重要的部分,并且非常复杂。
2、异常处理跳转信息
**
如果代码中出现了
try{}catch{}块,那么try{}块内的机器指令的地址范围记录下来,并且记录对应的catch{}块中的起始机器指令地址,当运行时在try块中有异常抛出的话,JVM会将catch{}块对应懂得其实机器指令地址传递给PC寄存器,从而实现指令跳转;
3、Java源码行号和机器指令的对应关系—-LineNumberTable属性表
编译器在将java源码编译成class文件时,会将源码中的语句行号跟编译好的机器指令关联起来,这样的class文件加载到内存中并运行时,如果抛出异常,JVM可以根据这个对应关系,抛出异常信息,告诉我们我们的源码的多少行有问题,方便我们定位问题。
4、Code属性表结构体
1、attribute_name_index : 属性名称索引,占有2个字节,其内的值指向了常量池中的某一项,该项表示字符. 串“Code”;
2、attribute_length : 属性长度,占有 4个字节,其内的值表示后面有多少个字节是属于此Code属性表的;
3、max_stack : 操作数栈深度的最大值,占有 2 个字节,在方法执行的任意时刻,操作数栈都不应该超过这个值,虚拟机的运行的时候,会根据这个值来设置该方法对应的栈帧(Stack Frame)中的操作数栈的深度;
4、max_locals最大局部变量数目,占有 2个字节,其内的值表示局部变量表所需要的存储空间大小;
5、code_length : 机器指令长度,占有 4 个字节,表示跟在其后的多少个字节表示的是机器指令;
6、code 机器指令区域,该区域占有的字节数目由 code_length中的值决定。JVM最底层的要执行的机器指令就存储在这里;
7、exception_table_length : 显式异常表长度,占有2个字节,如果在方法代码中出现了try{} catch()形式的结构,该值不会为空,紧跟其后会跟着若干个exception_table结构体,以表示异常捕获情况;
8、exception_table : 显式异常表,占有8 个字节,start_pc,end_pc,handler_pc中的值都表示的是PC计数器中的指令地址。exception_table表示的意思是:如果字节码从第start_pc行到第end_pc行之间出现了catch_type所描述的异常类型,那么将跳转到handler_pc行继续处理。
9、attribute_count : 属性计数器,占有 2 个字节,表示Code属性表的其他属性的数目
10、attribute_info : 表示Code属性表具有的属性表,它主要分为两个类型的属性表:“LineNumberTable”类型和“LocalVariableTable”类型。“LineNumberTable”类型的属性表记录着Java源码和机器指令之间的对应关系“LocalVariableTable”类型的属性表记录着局部变量描述
8.4 StackMapTable属性
StackMapTable属性属于Code属性的attributes表。它用于class文件的验证过程中的类型检查中。一个Code属性的attributes表中最多只可能有一个StackMapTable属性。
StackMapTable_attribute {u2 attribute_name_index;u4 attribute_length;u2 number_of_entries;stack_map_frame entries[number_of_entries];}
- attribute_name_index:对应的是常量池表的一个有效索引。也即CONSTANT_Utf8_info结构中表示“StackMapTable”的索引。
- attribute_length:标识当前属性的长度(排除前六个字节)
- number_of_entries:表示entries表的成员数量。entries表中的所有成员都是一个stack_map_frame结构。
- 每一个entry元素都代表了一个方法的StackMapFrame。其包含了字节码的偏移量和局部变量表、操作数栈的验证类型
- 其实第一个StackMapFrame是隐式的,并且是通过类型检查器的方法描述计算出来。
该表中的每个
entry表示方法的一个栈映射帧(stack map frame)。表中栈映射帧的顺序是有意义的。
一个栈映射帧指定了它所应用处的字节码偏移量,以及偏移量对应的局部变量和操作数栈条目的验证类型。
每个栈映射帧依赖于它前面的帧,方法的第一个栈映射帧是隐含的,由类型检查器根据方法描述符进行计算,因此stack_map_frame结构的entries[0]描述了方法的第二个栈映射帧。
一个栈映射帧对应的字节码偏移采用帧中指定的偏移增量offset_delta,并且通过将offset_delta + 1加到前一个帧的字节码偏移量中计算出。除非前一个帧是初始化帧,这种情况下,该栈映射帧对应的字节码偏移就是帧中指定的offset_delta。
java代码:
public class Coffee {int bean;public void getBean(int var) {if (var > 0) {this.bean = var;} else {throw new IllegalArgumentException();}}}
编译后的字节码:
public void getBean(int);Code:Stack=2, Locals=2, Args_size=20: iload_11: ifle 124: aload_05: iload_16: putfield #2; //Field bean:I9: goto 2012: new #3; //class java/lang/IllegalArgumentException15: dup16: invokespecial #4; //Method java/lang/IllegalArgumentException."<init>":()V19: athrow20: returnLineNumberTable:line 11: 0line 12: 4line 14: 12line 16: 20StackMapTable: number_of_entries = 2frame_type = 12 /* same */frame_type = 7 /* same */
最后三行,看到了StackMapTable,没错这个就是栈图。StackMapTable包含了:
8.4 ConstantValue属性
之所以学习这个,是因为后面类加载机制有联系到这个属性
这个属性的作用是通知虚拟机为静态变量赋值,只要被static修饰的变量才有这个属性,【有该属性的字段必须有ACC_STATIC访问标志,反过来不一定】。
对于 “int x = 123” 和 “static int x =123”这类代码在日常编写中很常见,但虚拟机对这两种变量赋值的时刻却不同。
对于非static变量[实例变量],是在实例构造器
进行 对于类变量,有两种方式选择 ①在类构造器
方法中赋值 ②使用ConstantValue属性初始化 目前Sun javac编译器是这么做的【具体咋做不知道 = =】,
如果同时使用final和static修饰一个变量[这种修饰就相当于个常量],并且是String或基本类型,就使用②, 如果没有被final修饰或不是基本类型和String,就选择①在方法中初始化。最后几句话也对这个解释的很清楚。
8.4 示例代码
public class Simple {public static synchronized final void greeting(){int a = 10;}}
1、访问标志
greeting()方法的修饰符有:public、static、synchronized、final 这几个修饰符修饰,那么相对地,
greeting()方法的访问标志中的ACC_PUBLIC、ACC_STATIC、ACC_SYNCHRONIZED、ACC_FINAL标志位都应该是1
从上面第一张图可以得出,该访问标志的值应该是十六进制0x0039**。
2、名称索引和描述符索引
紧接着访问标志(access_flags)后面的两个字节,叫做名称索引(name_index),这两个字节中的值是指向了常量池中某个常量池项的索引,该常量池项表示这这个方法名称的字符串**。
方法描述符索引(descrptor_index**)是紧跟在名称索引后面的两个字节,这两个字节中的值跟名称索引中的值性质一样,都是指向了常量池中的某个常量池项。这两个字节中的指向的常量池项,是表示了方法描述符的字符串**。

3、Simple.class文件
**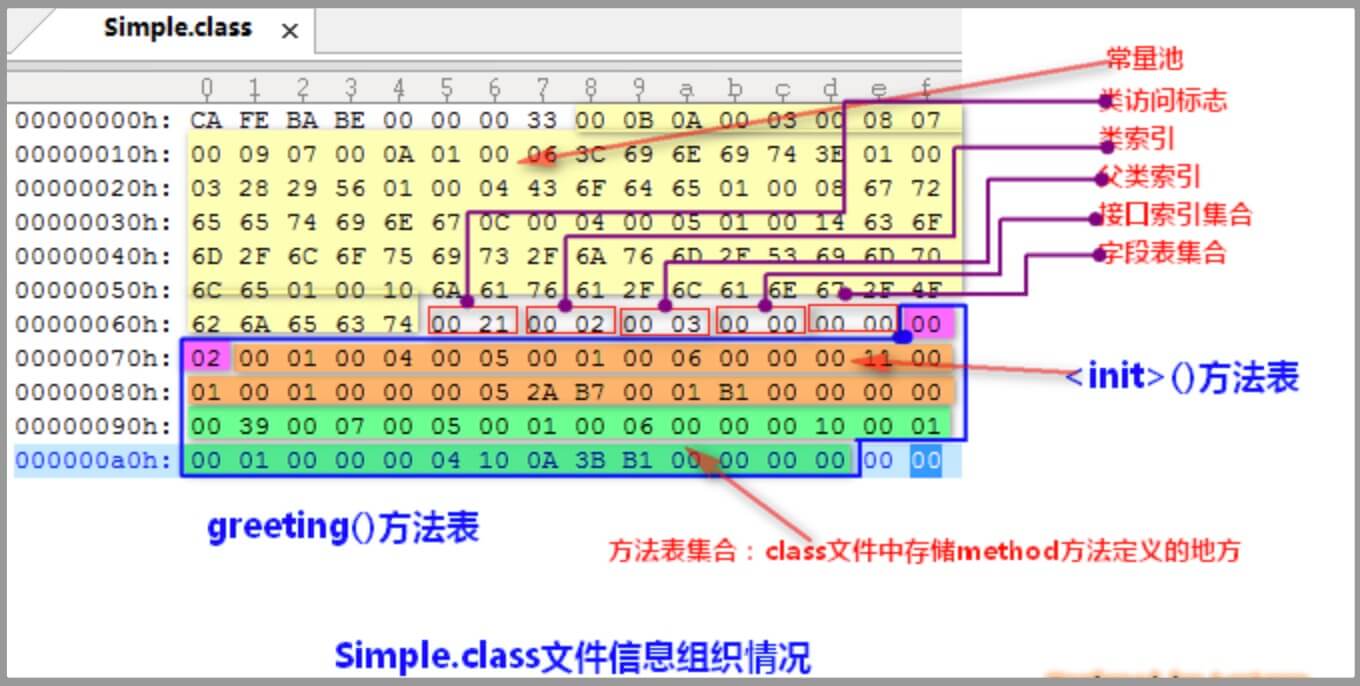
注意 :方法表集合的头两个字节,即方法表计数器(method_count)的值是0x0002,它表示该类中有2 个方法。注意到,我们的Simple.java中就定义了一个greeting()方法,为什么class文件中会显示有两个方法呢?
如果我们在类中没有定义实例化构造方法,JVM编译器在将源码编译成class文件时,会自动地为这个类添加一个不带参数的实例化构造方法,这种添加是字节码级别的,JVM对所有的类实例化构造方法名采用了相同的名称:“”。如果我们显式地如下定义Simple()构造函数,这个类编译出来的class文件和上面的不带Simple构造方法的Simple类生成的class文件是完全相同的。
4、**Simple.class 中的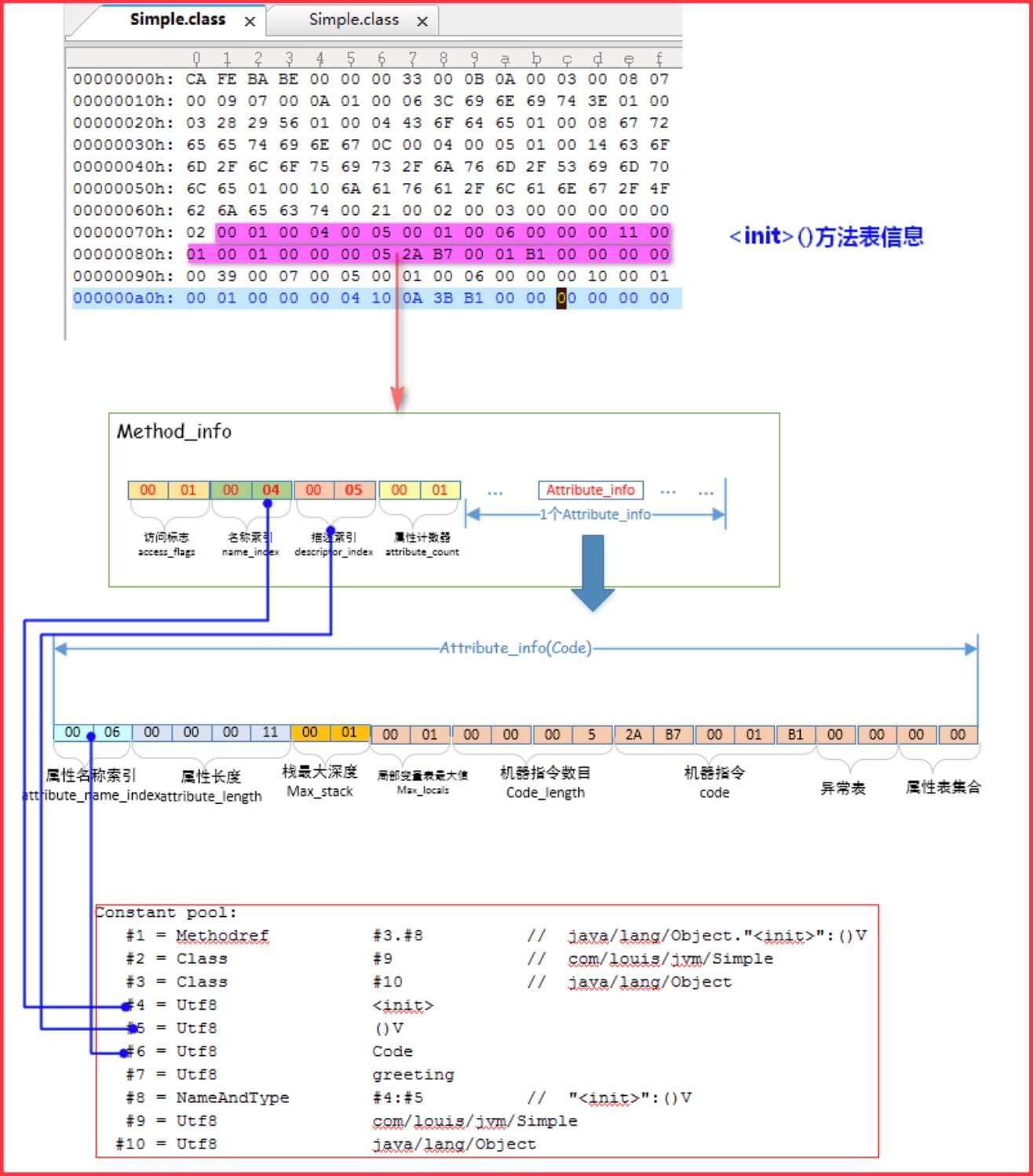
解释:
1、方法访问标志(access_flags) : 占有 2个字节,值为0x0001,即标志位的第 16 位为 1,所以该
2、 名称索引(name_index): 占有 2 个字节,值为 0x0004,指向常量池的第 4项,该项表示字符串’
3、描述符索引(descriptor_index):占有 2 个字节,值为0x0005,指向常量池的第 5 项,该项表示字符串“()V”,即表示该方法不带参数,并且无返回值(构造函数确实也没有返回值);
4、属性计数器(attribute_count) :占有 2 个字节,值为0x0001,表示该方法表中含有一个属性表,后面会紧跟着一个属性表;
5、属性表的名称索引(attribute_name_index) :占有 2 个字节,值为0x0006,指向常量池中的第6 项,该项表示字符串“Code”,表示这个属性表是Code类型的属性表;
6、 属性长度(attribute_length):占有4个字节,值为0x0000 0011,即十进制的 17,表明后续的 17 个字节可以表示这个Code属性表的属性信息;
7、 操作数栈的最大深度(max_stack):占有2个字节,值为0x0001,表示栈帧中操作数栈的最大深度是1;
8、局部变量表的最大容量(max_variable):占有2个字节,值为0x0001, JVM在调用该方法时,根据这个值设置栈帧中的局部变量表的大小;
9、 机器指令数目(code_length) :占有4个字节,值为0x0000 0005,表示后续的5 个字节 0x2A 、0xB7、 0x00、0x01、0xB1表示机器指令;
10、机器指令集(code[code_length]):这里共有 5个字节,值为0x2A 、0xB7、 0x00、0x01、0xB1;
11、显式异常表集合(exception_table_count): 占有2 个字节,值为0x0000,表示方法中没有需要处理的异常信息;
12、Code属性表的属性表集合(attribute_count): 占有2 个字节,值为0x0000,表示它没有其他的属性表集合,因为我们使用了-g:none 禁止编译器生成Code**属性表的 LineNumberTable 和LocalVariableTable**;
解释下机器指令集:
`第一个字节 0x2A`:查询Java 虚拟机规范中关于操作码的解释,0x2A 对应的操作是”aload_0“,作用是将第一个引用类型局部变量推送至栈顶;
第二个字节 0xB7 :0xB7 对应的操作是:”invokespecial“,作用是调用超类构造方法、实例初始化方法或私有方法;它带有2个字节的参数,即后面的 0x00、0x01 是它的参数,这个参数是某个常量池中的索引,指向了常量池的第一项,该项表示一个方法引用项CONSTANT_Methodref_info结构体,表示java.lang.Object 类中的
第5个字符是0xB1 : 对应操作是:“Ireturn”,作用是表示无返回值的方法返回,结束方法调用,这条语句放在方法的机器码最后,表示方法结束调用,返回。
我们可以使用javap -v Simple > Simple.txt**,查看反编译信息是怎样显示这一信息的:**

Simple.class 中的greeting() 方法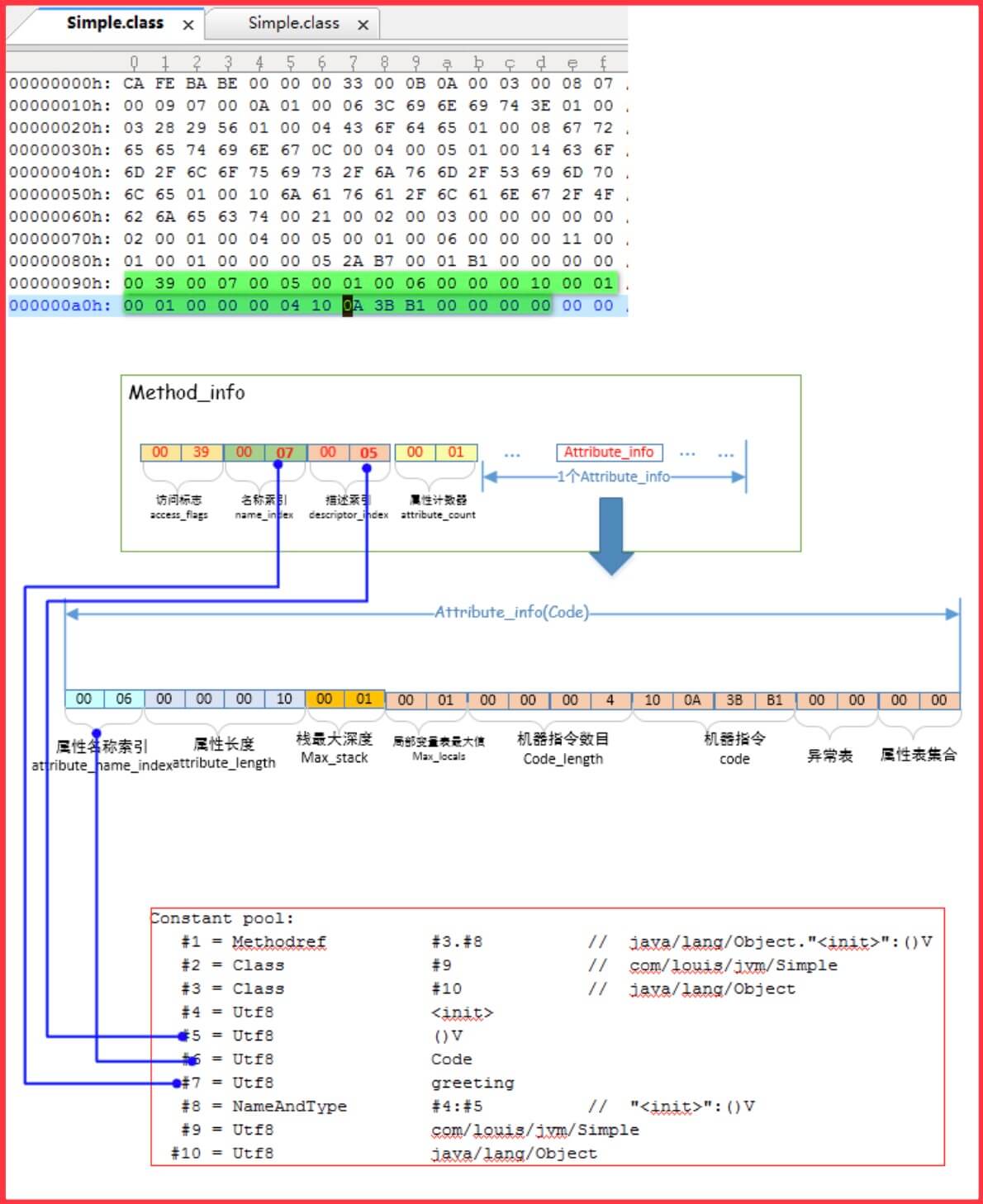
1、方法访问标志(access_flags): 占有 2个字节,值为 0x0039 ,即二进制的00000000 00111001,即标志位的第11、12、13、16位为1,根据上面讲的方法标志位的表示,可以得到该greeting()方法的修饰符有:ACC_SYNCHRONIZED、ACC_FINAL、ACC_STATIC、ACC_PUBLIC;
2、 名称索引(name_index): 占有 2 个字节,值为 0x0007,指向常量池的第 7 项,该项表示字符串“greeting”,即该方法的名称是“greeting”;
3、描述符索引(descriptor_index): 占有 2 个字节,值为0x0005,指向常量池的第 5 项,该项表示字符串“()V”,即表示该方法不带参数,并且无返回值;
4、属性计数器(attribute_count): 占有 2 个字节,值为0x0001,表示该方法表中含有一个属性表,后面会紧跟着一个属性表;
5、属性表的名称索引(attribute_name_index) :占有 2 个字节,值为0x0006,指向常量池中的第6 项,该项表示字符串“Code”,表示这个属性表是Code类型的属性表;
6、属性长度(attribute_length):占有4个字节,值为0x0000 0010,即十进制的16,表明后续的16个字节可以表示这个Code属性表的属性信息;
6、属性长度(attribute_length):占有4个字节,值为0x0000 0010,即十进制的16,表明后续的16个字节可以表示这个Code属性表的属性信息;
7、操作数栈的最大深度(max_stack) :占有2个字节,值为0x0001,表示栈帧中操作数栈的最大深度是1;
8、 局部变量表的最大容量(max_variable):占有2个字节,值为0x0001, JVM在调用该方法时,根据这个值设置栈帧中的局部变量表的大小;
9、器指令数目(code_length):占有4 个字节,值为0x0000 0004,表示后续的4个字节0x10、 0x0A、 0x3B、0xB1的是表示机器指令;
10、机器指令集(code[code_length]):这里共有4 个字节,值为0x10、 0x0A、 0x3B、0xB1 ;
11、显式异常表集合(exception_table_count): 占有2 个字节,值为0x0000,表示方法中没有需要处理的异常信息;
12 Code属性表的属性表集合(attribute_count): 占有2 个字节,值为0x0000,表示它没有其他的属性表集合,因为我们使用了-g:none 禁止编译器生成Code**属性表的 LineNumberTable 和LocalVariableTable**;
指令集解释第一个字节 0x10 : 查询Java虚拟机规范中关于操作码的解释,0x10 对应的操作是”bipush”,” 作用是将单字节的常量值(-128~127) 推送至栈顶,它要求一个参数,后面的 0x0A 即是需要推送到栈顶的单字节,注意这里的 0x0A 是16进制,就是我们在代码里写的”a=10”中的10。
第三个字节"3B" : “3B”对应的操作是:”istore_0”,作用是将栈顶int 型数值存入第一个局部变量。我们在greeting() 方法中就声明了一个局部变量a,JVM的运行的时候,将这个局部变量a解析,并放置到局部变量表中的第一个位置;上述的0x10 0x0A 指令已经将0x0A 推送到了栈顶了,然后 0x3B指令便将栈顶的0x0A 取出,赋值给局部变量表中的第一个参数,即局部变量a,这样就完成了对局部变量a的赋值;
第4个字符是0xB1 : 对应操作是:“Ireturn”,作用是表示无返回值的方法返回,结束方法调用,这条语句放在方法的机器码最后,表示方法结束调用,返回。

参考文章
字节码增强技术探索—-《美团技术团队》 https://www.cnblogs.com/qdhxhz/p/10676337.html

若有收获,就点个赞吧
0 人点赞
