1.Requests库
该第三方库提供了丰富的访问连接,爬取数据的方法,建立连接的基本方式:
import requestsfrom fake_useragent import UserAgent# requests.get('',params='') # get方法用于发送get请求,有三个参数 url必填,param选项:get请求中的参数?,**kwargs选项:控制访问的参数# 应用get()方法连接网站,抓取豆瓣top250页面代码的前380个字符url = "https://movie.douban.com/top250" # 豆瓣电影top250headers = {"User-Agent": UserAgent().chrome}req = requests.get(url,headers=headers) # 更加简洁,不再需要Request构造一次请求,再传给urlopenreq.encoding = req.apparent_encodingprint(req.text[:380]) # 列表或者字典的截取方法: [a:b]表示截取从a到b-1,如果一项不写表示从头或从尾开始截取。
requests.text
爬取的数据作为文本通过该变量保存,可以打印该变量,text字符串类型可以通过[ ]中括号方式截取部分内容,[a:b]表示从a截取到b-1,比如[0:380]就是从0开始截取到379个字符。参数为0或为结尾时可以省略不写。
text = '123455678'text[ :5]表示从头到4 ,text[2: ]则表示从2到结尾。
2.BeautifulSoup 4 (bs4) 库
在爬取了网页代码之后就需要数据解析,来查找我们需要的标签体以及里面的内容,类似JS的jQuery查询和操作DOM,python中也有专门解析、遍历标签的库模块BeautifulSoup简称bs4。BeautifulSoup 是 bs4库中的一个类,主要使用的类。
该模块提供两个方法:find 和 find_all , 一个只找第一个标签,另一个查找全部标签并返回一个列表。可以根据标签的名字,属性,内容进行查找。
find方法的参数
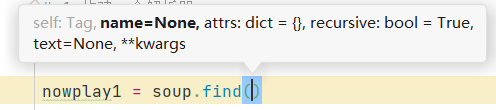
从左到右依次是:标签名name,标签属性attrs:字典类型,标签内容text。
使用步骤:
1.在网页开发者工具中,找到我们需要解析的标签名或属性名,反正是任何可以定位到该标签的内容都可以。下图中就是 div 和 class = “nowplaying”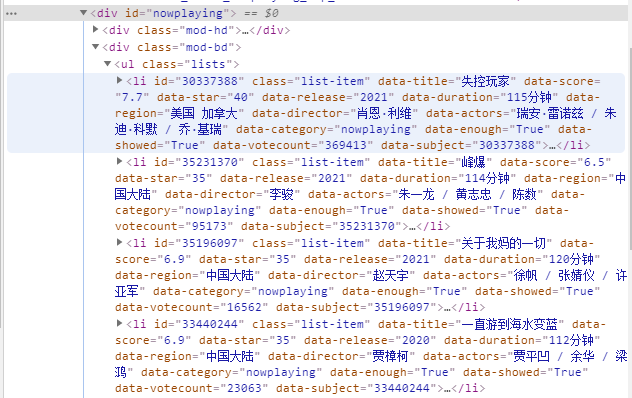
2.在python中用bs4创建解析器对象,并用request建立连接
以
# bs4全名BeautifulSoup 4 专门用于解析、遍历、维护网页’标签‘的功能库,类似jQuery# bs4的两个方法 find() 和 find_all(),可以根据html标签名,标签属性,标签内容查询,类比jQuery的Selector# 导入 bs4 模块中的BeautifulSoup类 as 后可以起别名from bs4 import BeautifulSoup as bsfrom fake_useragent import UserAgentimport requestsurl = "https://movie.douban.com/cinema/nowplaying/maoming/" # 豆瓣电影首页headers = {"User-Agent": UserAgent().chrome # 伪装成浏览器}req = requests.get(url,headers=headers) # 建立连接,修改请求头html_data = req.text # 获取网页代码# 开始解析网页代码# 构建一个解析器soup = bs(html_data, "html.parser")nowplay1 = soup.find("ul",class_= "lists") # 解析区域 <ul class="lists"></ul>中的<li>列表# 注意class为关键字,如果要作为匹配参数需要加个下划线nowplay2 = nowplay1.find_all("li",class_ = "list-item") # 可以在上一次解析的结果上再次解析,解析ul标签下的li标签print(nowplay2) # 输出后发现,电影名是li标签的data-title属性的值,所以之后遍历nowplay2只要取出data-title的值即可
3.遍历查询出的标签树,将数据装入一个字典列表(对象数组)
nowplay_list = [] # 用来装遍历的电影信息for item in nowplay2: # 在nowplay2中 一个li标签作为一个item对象nowplay_dict = {} # 用来装当此遍历结果的字典,键值对形式nowplay_dict['id'] = item['id'] # 获得电影idnowplay_dict['name'] = item['data-title'] # 获得电影名nowplay_dict['img_src'] = item.find("img")['src'] # 解析li标签下的img图片标签的地址srcnowplay_list.append(nowplay_dict) # 将结果加入到外部的列表中# nowplay_list.append(item['data-title']) # 也可以只加入电影名print(nowplay_list)
完整的python程序:
# bs4全名BeautifulSoup 4 专门用于解析、遍历、维护网页’标签‘的功能库,类似jQuery# bs4的两个方法 find() 和 find_all(),可以根据html标签名,标签属性,标签内容查询,类比jQuery的Selector# 导入 bs4 模块中的BeautifulSoup类 as 后可以起别名from bs4 import BeautifulSoup as bsfrom fake_useragent import UserAgentimport requestsurl = "https://movie.douban.com/cinema/nowplaying/maoming/" # 豆瓣电影首页headers = {"User-Agent": UserAgent().chrome # 伪装成浏览器}req = requests.get(url,headers=headers) # 建立连接,修改请求头html_data = req.text # 获取网页代码# 开始解析网页代码# 构建一个解析器soup = bs(html_data, "html.parser")nowplay1 = soup.find("ul",class_= "lists") # 解析区域 <ul class="lists"></ul>中的<li>列表# 注意class为关键字,如果要作为匹配参数需要加个下划线nowplay2 = nowplay1.find_all("li",class_ = "list-item") # 可以在上一次解析的结果上再次解析,解析ul标签下的li标签print(nowplay2) # 输出后发现,电影名是li标签的data-title属性的值,所以之后遍历nowplay2只要取出data-title的值即可nowplay_list = [] # 用来装遍历的电影信息for item in nowplay2: # 在nowplay2中 一个li标签作为一个item对象nowplay_dict = {} # 用来装当此遍历结果的字典,键值对形式nowplay_dict['id'] = item['id'] # 获得电影idnowplay_dict['name'] = item['data-title'] # 获得电影名nowplay_dict['img_src'] = item.find("img")['src'] # 解析li标签下的img图片标签的地址srcnowplay_list.append(nowplay_dict) # 将结果加入到外部的列表中# nowplay_list.append(item['data-title']) # 也可以只加入电影名print(nowplay_list)

若有收获,就点个赞吧
0 人点赞
