第11章 管道架构风格
城里的月光_欧阳关注
2020.11.17 00:26:15字数 2,546阅读 711
软件架构中反复出现的一种基本风格是管道架构(也称为管道和过滤器架构)。一旦开发人员和架构师决定将功能拆分为独立的部分,这种模式就随之而来了。大多数开发人员都知道这种架构是Unix终端shell语言(如Bash和Zsh)背后的基本原理。
许多函数式编程语言的开发人员将看到语言构造和这种架构元素之间的相似之处。实际上,许多使用MapReduce编程模型的工具都遵循这个基本拓扑结构。虽然这些示例展示了管道架构风格的底层实现,但它也可以用于更高级别的业务应用。
拓扑结构
管道架构的拓扑结构由管道和过滤器组成,如图11-1所示。
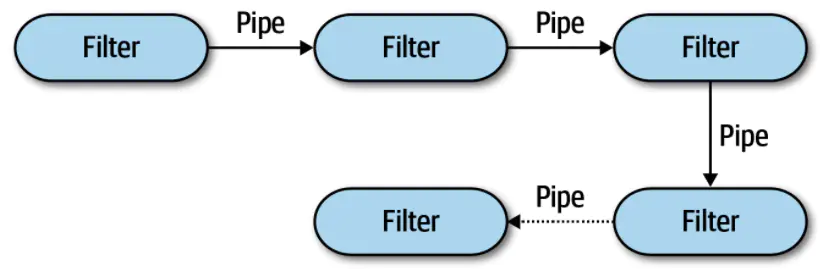
图11-1. 管道架构的基本拓扑结构
管道和过滤器以特定的方式协调,管道通常以点对点的方式在过滤器之间形成单向通信。
管道
这种架构中,管道构成了过滤器之间的通信通道。出于性能考虑的原因,每个管道通常是单向的、点对点的(而不是广播)的方式,接受来自一个源的输入并始终将输出定向到另一个源。管道上传输的载荷可以是任何数据格式的,但是架构师倾向于使用较小的数据量来实现高性能。
过滤器
过滤器是自主的,独立于其他过滤器,通常是无状态的。一个过滤器只能执行一个任务。复合任务应该由一系列过滤器而不是单个过滤器来处理。
此架构风格中存在四种类型的过滤器:
生产者
一个进程的起始点,仅向外输出,有时也称为源端。
转换器
接受输入,有选择地对部分或全部数据执行转换,然后将其转发到出站管道。函数式倡导者会将此特征看作为map。
测试者
接受输入,测试一个或多个条件,然后根据测试选择性地生成输出。函数式程序员将认为这与reduce类似。
消费者
管道流的终点。消费者有时会将管道过程的最终结果持久化到数据库中,或者它们可能会把最终结果显示在用户界面屏幕上。
每个管道和过滤器的单向性和简单性鼓励了组合重用。许多开发人员已经在使用shell的时候发现了这种能力。来自博客“More Shell,Less Egg”的一个著名的故事说明了这些抽象是多么的强大。Donald Knuth被要求编写一个程序来解决这样一个文本处理问题:读取一个文本文件,确定n个最常用的单词,并打印出这些单词及其频率的排序列表。他编写了一个由10多页Pascal组成的程序,设计(并记录)了一个新算法。然后,Doug McIlroy演示了一个shell脚本,它可以很容易地放入Twitter帖子中,从而更简单、更优雅、更易于理解地解决问题(如果您理解shell命令):
tr -cs A-Za-z ‘\n’ |
tr A-Z a-z |
sort |
uniq -c |
sort -rn |
sed ${1}q
即使是Unix Shell的设计者也经常对开发人员使用他们简单但强大的组合抽象所实现的创新性用途感到惊讶。
示例
管道架构模式出现在各种应用程序中,尤其是便于简单、单向处理的任务。
例如,许多电子数据交换(EDI)工具都使用这种模式,使用管道和过滤器构建从一种文档类型到另一种文档类型的转换。ETL工具(提取、转换和加载)也利用管道架构将数据从一个数据库或数据源流向另一个数据库或数据源。ETL工具(提取、转换和加载)也利用管道架构将数据从一个数据库或数据源到另一个数据库或数据源进行传输和修改。像Apache Camel这样的协调器和中介器利用管道架构将信息从业务流程的一个步骤传递到另一个步骤。
为了说明如何使用管道架构,请考虑下面的示例,如图11-2所示,其中各种服务遥测信息通过流式传输从服务发送到Apache Kafka。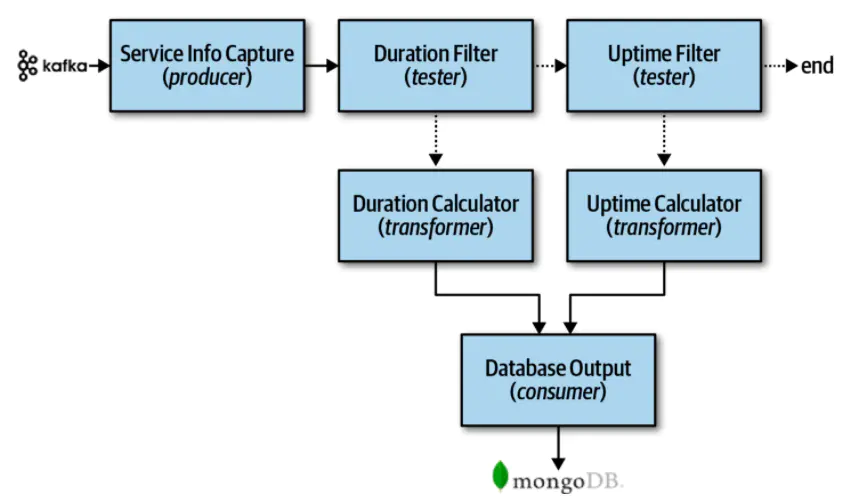
图11-2. 管道架构示例
注意在图11-2中,使用管道架构风格来处理流到Kafka的不同类型的数据。Service Info Capture过滤器(生产者过滤器)订阅Kafka主题并接收服务信息。然后,它将捕获的数据发送到一个名为Duration Filter的测试过滤器,以确定从Kafka捕获的数据是否与服务请求的持续时间(以毫秒为单位)有关。注意过滤器之间的关注点的分离;Service Info Capture过滤器只关心如何连接到Kafka主题并接收流数据,而Duration Filter过滤器只关心选取符合资格的数据并选择性地将其路由到下一个管道。如果数据与服务请求的持续时间(以毫秒为单位)有关,则Duration Filter过滤器将数据传递给Duration Calculator转换过滤器进行过滤。否则,它会将其传递给Uptime Filter测试过滤器,以检查数据是否与正常运行时间指标相关。如果不是,则管道结束,数据与此特定处理流无关。否则,如果是正常运行时间指标,那么它会将数据传递给Uptime Calculator,以计算服务的正常运行时间指标。然后,这些转换器将修改后的数据传递给Database Output消费者,然后将数据保存在MongoDB数据库中。
这个例子显示了管道架构的可扩展性属性。例如,在图11-2中,可以很容易地在Uptime Filter之后添加一个新的测试者过滤器,将数据传递到另一个新收集的指标上,比如数据库连接等待时间。
架构特性评级
特性评级表中的一星级评级(如图11-3所示)意味着特定的架构特性在某种架构中没有得到很好的支持,而五星评级意味着架构特性是某种架构风格中最强大的特性之一。记分卡中确定的每个特性的定义见第4章。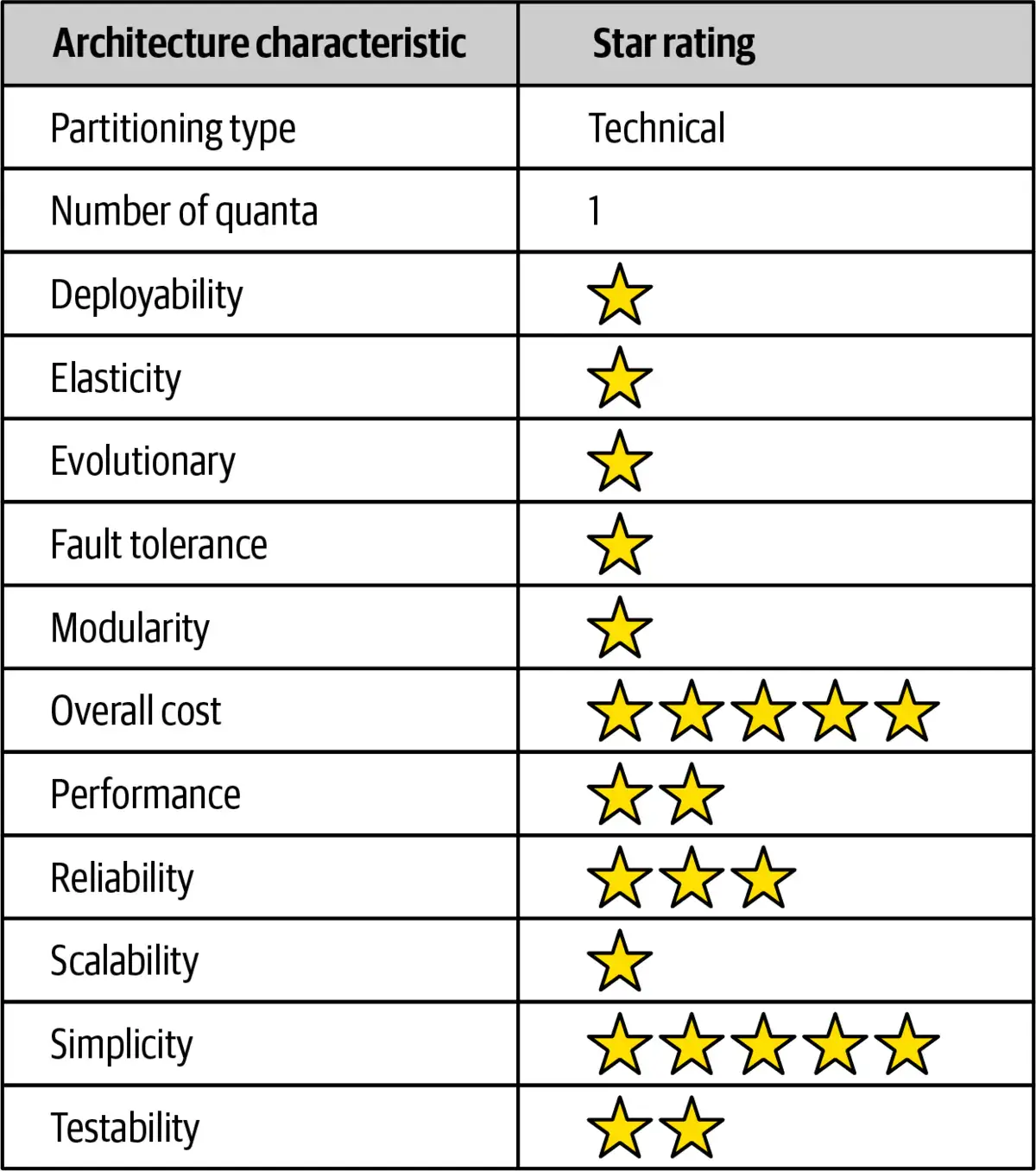
图11-3. 管道架构特性评级
总体成本低和简单性以及模块化是管道架构风格的主要优势。管道架构本质上是单体的,它不具有与分布式架构风格相关联的复杂性,它简单易懂,并且建设和维护的成本相对较低。架构模块化是通过不同类型的过滤器和转换器的关注点分离来实现的。这些过滤器中的任何一个都可以在不影响其他过滤器的情况下进行修改或更换。例如,在图11-2所描述的Kafka例子当中,Duration Calculator可以进行修改而不对其他过滤器造成影响。
可部署性和可测试性,虽然只有平均水平,但由于通过过滤器实现的模块化水平,其评级略高于分层架构。也就是说,这种架构风格仍然是单体的,因此,部署的成本、风险、频率和测试的完成性仍然会对管道架构产生影响。
与分层架构类似,管道架构的总体可靠性为中等(三星级),主要是由于没有在大多数分布式架构中存在的网络流量、带宽和延迟问题。我们只给了它三颗星的可靠性,因为这种架构风格的单体部署的本质,以及存在可测试性和可部署性问题(例如,必须测试整个整体,并为任何给定的更改部署整个整体)。
管道架构的弹性和可扩展性非常低(一星),主要是由于单体部署。虽然在一个单体应用内实现某些功能的扩展是可能的,但这种工作通常需要非常复杂的设计技术,如多线程、内部消息传递和其他在这种架构中不适合使用的并行处理实践和技术。然而,由于用户界面、后端处理和数据库的单一性,管道架构始终是一个单一的系统量子,因此应用只能在单个量子的基础上扩展到一定的程度。
由于单体部署和缺乏架构模块性,管道架构不支持容错。如果管道架构的一小部分发生内存不足问题,则整个应用单元将受到影响并崩溃。此外,由于大多数单体应用普遍存在较高的平均恢复时间(MTTR),总体可用性受到影响,启动时间从小型应用的2分钟,到大多数大型应用的15分钟或更长。
原文参考:https://www.jianshu.com/p/e14ec0a3d67b
全书翻译目录:https://www.jianshu.com/p/05711d172dfa

若有收获,就点个赞吧
0 人点赞
