张逸,架构编码实践者,IT 文艺工作者,大数据平台架构师,兼爱面向对象与函数式程序设计,热衷于编程语言学习与技艺提升,致力于将主流领域驱动设计(DDD)与函数式编程、响应式编程以及微服务架构完美结合。个人微信公众号:逸言。个人博客: (http://iamzhangyi.github.io)
复杂的事物让人着迷,繁复、多样、无序以及其中蕴含的无穷变化或许也是我觉得软件设计有趣的地方。由于设计的复杂性,我在每次面临不同的项目、不同的产品时,油然而生一种耳目一新的感觉,似乎重启了新的旅程,风景不同,心境自然也就不同了。
然而,复杂并不总是令人感到有趣,除非我们具有掌控复杂的能力。
那么,什么是复杂?
1什么是复杂
Jurgen Appelo 在分析复杂系统理论时,将 Complicated 与 Complex 分别放在理解力与预测能力两个迥然不同的维度上。Complicated 与 Simple(简单)相对,意指非常难以理解, 而 Complex 则介于 Ordered(有序的)与 Chaotic(混沌的)之间,意指在某种程度上可以预测,但会有很多出乎意料的事情发生,如图 4.1 所示。
大多数软件系统是难以理解的,虽然我们可以遵循一些设计原则来应对未来的变化,但由于未来是不可预测的,因而软件的演进其实存在不可预测的风险。如此看来,软件系统所谓的“复杂”其实覆盖了 Complicated 与 Complex 两个方面,等同于图 4.1 中城市所处的位置。凑巧的是,Sam Newman 也认为城市的变迁与软件的演化存在很大程度的相似性: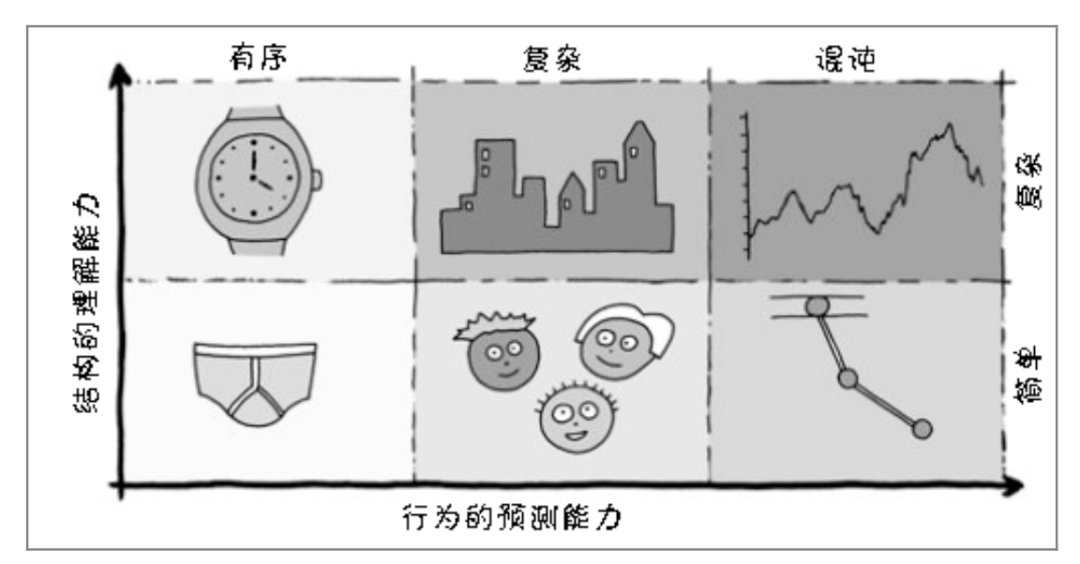 图 4.1
图 4.1
很多人把城市比作生物,因为城市会时不时地发生变化。当居民对城市的使用方式有所变化,或者受到外力的影响时,城市就会相应地演化。
上面描述的城市和软件的对应关系应该是很明显的。当用户对软件提出变更需求时,我们需要对其进行响应并做出相应的改变。未来的变化很难预见,所以与其对所有变化的可能性进行预测,不如做一个允许变化的计划。
城市与软件的复杂度有可比之处,还在于其结构的复杂性。不同风格与不同类型的建筑,杂乱如蜘蛛网一般的城市道路,还有居民生存的复杂生态圈,展现出形态各异的风貌,甚至每一条陋巷都背负了沧桑厚重的历史。
软件系统的代码行即砖瓦,通信端口即车辆行驶的道路,每个构建模块是建筑物,基础设施是排水系统,公共模块是医院、学校或者公园,软件架构就是对整个城市的规划和布局。
因而要理解软件系统的复杂度,也可以结合理解力与预测能力这两个因素来帮助我们思考。在软件系统中,是什么阻碍了开发人员对它的理解?想象一下,团队招入一位新人,这位新人就像一位游客来到了一座陌生的城市,他是否会迷失在阡陌交错的城市交通体系中不辨方向?倘若这座城市不过只有房屋数间,一条街道连通城市的两头,实则是乡野郊外的一座村落,那还会使他生出迷失之感吗?
所以,影响理解力的第一要素是规模。
1.1规模
软件的需求决定了系统的规模。当需求呈现线性增长的趋势时,为了实现这些功能,软件规模也会以近似的速度增长。
由于需求不可能做到完全独立,这种相互影响相互依赖的关系使得修改一处就会牵一发而动全身。
就好似城市的一条道路因为施工需要临时关闭,此路不通,通行的车辆只得改道绕行,这又导致了其他原本已经饱和的道路因为涌入更多车辆,超出道路的负载从而变得更加拥堵,这种拥堵现象又会顺势向这些道路的其他分叉道路蔓延,形成一种辐射效应的拥堵现象。
以下几种情况都可能使软件开发产生拥堵现象,或许比道路堵塞更严重。
- 函数存在副作用,调用时可能对函数的结果作了隐含的假设。
- 类的职责繁多,不敢轻易修改,因为不知道这种变化会影响到哪些模块。
- 热点代码被频繁变更,职责被包裹了一层又一层,没有清晰的边界。
- 在系统的某个角落里,隐藏着伺机而动的 Bug,当诱发条件具备时,就会让整条调用链瘫痪。
- 在不同场景下,会产生不同的异常场景,每种异常场景的处理方式都各不相同。
- 同步处理与异步处理代码纠缠在一起,不可预知程序执行的顺序。
这是一个复杂的生态环境,新的需求变化就好似在南美洲亚马孙河流域热带雨林中的蝴蝶,轻轻扇动一下翅膀,就在美国得克萨斯州掀起了一场龙卷风。面对软件复杂度的“蝴蝶效应”,我们心存畏惧。
在我负责设计与开发的 BI(Business Intelligence)产品中,我们需要展现报表(Report) 下的所有视图(View)。这些视图的数据可能来自多个不同的数据集(Data Set),而视图的类型也多种多样,例如柱状图、折线图、散点图等。
在这个“逼仄”的报表问题域中,我们需要满足如下业务需求。
在编辑状态下,支持对每个视图进行拖曳以改变视图的位置。
- 在编辑状态下,允许通过拖曳边框调制视图的尺寸。
- 当单击视图的图形区域时,应当使当前图形的组成部分显示高亮。
- 当单击视图的图形区域时,应当获取当前值,对属于相同数据集的视图进行联动。
- 如果打开钻取开关,则应当在单击视图的图形区域时获取当前值,并根据事先设定的钻取路径对视图进行钻取。
- 能够创建筛选器这样的特殊视图,通过筛选器选择数据,对当前报表中所有相同数据集的视图进行筛选。
这些业务需求都是我们事先预见到的,无一例外,它们都是对视图进行操作,这就导致了多种操作之间的纠缠与冲突。例如,高亮与级联都需要响应相同的 Click 事件,钻取同样如此,与之不同的是它还要判断钻取开关是否已经打开。而在操作效果上,如果高亮与钻取仅针对当前视图本身,则联动与筛选就会因为当前视图的操作影响到同一张报表下其他属于相同数据集的视图。对于拖曳操作,虽然它监听的是 MouseDown 事件,但该事件却与 Click 事件冲突。显然,实现这些功能的复杂度不能仅以功能点的增加来衡量。
软件复杂度会受到需求与规模的正向影响,但它的增长趋势要比需求与规模更加陡峭。
倘若需求还产生了事先未曾预料到的变化,我们又没有足够的风险应对措施,那么在时间 紧迫的情况下,难免会对设计做出妥协,头疼医头,脚疼医脚,在系统的各个地方打上补丁,从而欠下技术债。当技术债务越欠越多,累计到某个临界点时,量变就会引起质变, 整个软件系统的复杂度达到巅峰,步入衰亡的老年期。许多遗留系统(Legacy System)就 挣扎在濒临死亡的悬崖边上。这些遗留系统符合饲养场的奶牛原则:
奶牛逐渐衰老,最终无奶可挤;然而与此同时,饲养成本却在上升。
这意味着遗留系统会逐渐随着时间的推移,不断地增加维护成本。
一方面,随着需求 的变化,对遗留系统的维护变得越来越捉襟见肘;
另一方面,系统的知识又逐渐被腐蚀。团队成员变动了,留存在他们大脑中的系统知识随之而去。文档呢?勤奋而尊重流程的团队或许编写了可谓圣经一般完整而翔实的文档,可惜我们却只能参考,而不可尽信,因为这些文档不过是刻在船舷上的印迹,虽然刻下了当时宝剑落下的位置,然而舟船已经随着桨声欸乃滑向了彼岸。似乎只有代码才是最忠实的,然而当遭遇佶屈聱牙、晦涩难懂的代码时,当需要解开如一团乱麻般的依赖关系时,我们又该何去何从?
需求的变化,知识的流逝,正是遗留系统之殇!
我曾经参与过某大型金融机构客户系统的技术栈迁移。为了保证我们的技术栈迁移没有破坏系统的原有功能,需要为系统的核心功能编写自动化测试以形成保护网。
当时,曾经参与过该系统开发的人员已经“遗失”殆尽,我们除了得到少数团队人员的有限支持, 还可以参考和借鉴的只有这个系统的数百页 Word 文档以及千万行级的 Java 代码库。Java 代码库经历了大约七八年的变迁,并主要由外包团队开发,涉及的平台与框架包括 EJB 2、 Spring 3.0、Struts,乃至 JDK 5 之前的 Java 代码;
除此之外,还有部分我们完全搞不懂的 COBOL 代码(COBOL 语言? 是在远古时代吧!)。阅读代码库时,我们常常震惊于庞大臃肿的类,许多类的代码行数超过一万行以上,而数千行的方法体也是屡见不鲜,并沿袭了原始时代的编程传统,常常在方法的首端定义了数十个变量,并在整个方法中被重复赋值、 修改。系统通过 IBM MQ 实现分布式系统之间的集成。子系统之间传递的消息被定义为各式没有任何业务意义的消息编码,诸如 S01、S02、P01、P02。我们需要查阅文档了解这些 消息代码代表的业务含义,还需要明确消息之间传递的流程以及处理逻辑。
我们在为合并客户账户场景编写自动化测试时,发现文档中描述的异常消息 S05 的处理逻辑与实际的运行结果不一致。无奈之下,我们只有通过阅读源代码寻找业务的真相。
这个过程仿佛福尔摩斯探案,我们不能放过代码中任何可能揭示真相的蛛丝马迹。运行已经编写好的自动化测试,结合跨进程的调试手法,通过打印控制台日志来复现消息的走向, 从而通盘了解业务流程的运行轨迹。最后,真相水落石出,而我们发现为了编写这个自动化测试,足足耗费了两个人日的时间。
软件规模的一个显著特征是代码行数。然而,代码行数常常具有欺骗性。如果需求与代码行数之间呈现出不成比例的关系,则说明该系统的生命体征可能出现了异常,例如代码行数的庞大其实可能是一种肥胖症,它可能包含了大量的重复代码,这或许传递了一个需要改进的信号。
我在做一个咨询项目时,曾经利用 Sonar 工具对该项目中的一个模块进行了代码静态 分析,如图 4.2 所示。 图 4.2
图 4.2
这个模块的代码行数达到了四十多万行,其中重复代码竟然达到了惊人的 33.9%,超 过一半的代码文件混入了重复代码。显然,这里估算的代码行数并没有真实地体现软件规模,相反,因为重复代码的缘故,可能还额外增加了软件的复杂度。
Neal Ford 在文章 Emergent design through metrics 中谈到了如何通过指标来指导设计。文中提及的 iPlasma 是一个用于面向对象设计的质量评估平台,或许我们可以通过该工具的指标(见表 4.1)来找到评价软件规模的要素。
表 4.1 iPlasma 的指标及说明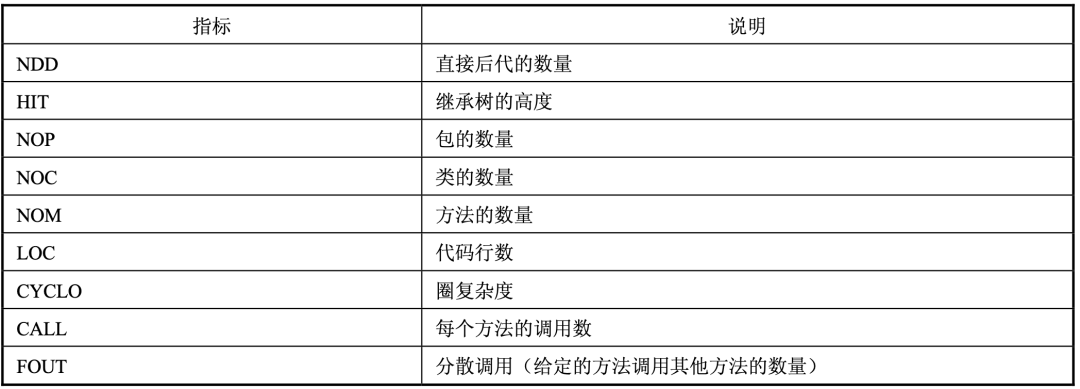
在面向对象设计的软件项目里,除了代码行数,包、类、方法的数量,继承的层次以及方法的调用数,还有常常提及的圈复杂度,都或多或少会影响到整个软件系统的规模。
1.2 结构
你去过迷宫吗?相似而回旋繁复的结构使得本来封闭狭小的空间被魔法般地扩展为一个无限的空间,变得无穷大,仿佛这空间被安置了一个循环,倘若没有找到正确的退出条件,循环就会无休无止,永远无法退出。
许多规模较小却格外复杂的软件系统,就好似这样一座迷宫。此时,结构成了决定系统复杂度的关键因素。
结构之所以变得复杂,多数情况下还是系统的质量属性决定的。例如,我们需要满足高性能、高并发的需求,就需要考虑在系统中引入缓存、并行处理、CDN、异步消息以及支持分区的可伸缩结构。倘若我们需要支持对海量数据的高效分析,就得考虑这些海量的数据该如何分布存储,并如何有效地利用各个节点的内存与 CPU 资源执行运算。
从系统结构的视角看,单体架构一定比微服务架构更简单,更便于掌控,正如单细胞生物比人体的生理结构要简单数百倍一样。
那么,为何还有这么多软件组织开始清算自己的软件资产,花费大量人力物力对现有的单体架构进行重构,走向微服务化呢?
究其主因, 不还是系统的质量属性在作祟吗? 纵观软件设计的历史,不是分久必合,合久必分,而是不断拆分、继续拆分、持续拆分的微型化过程。
分解的软件元素不可能单兵作战。怎么协同,怎么通信,就成了系统分解后面临的主要问题。如果没有控制好,这些问题固有的复杂度甚至会在某些场景下超过因为分解给我们带来的收益。如图 4.3 所示,由于对系统进行了分解,各个子系统或模块之间形成了复杂的通信网结构。 图 4.3
图 4.3
要理清这种通信网结构的脉络,就得弄清楚子系统之间的消息传递方式,明确消息格式的定义;同时,这种分布式的部署结构,在实现这些功能的同时,还必须额外考虑跨进程通信可能出现的异常场景,例如如何确保消息的可靠传递,如何保证数据结果的一致性。换言之,系统因为结构的繁复而增加了复杂度。
微服务的最终一致性
基于 CAP 理论,微服务这种分布式架构在满足 A(Availability)与 P(Partition Toralence) 的前提下,至少要保证数据的最终一致性,即系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
分布式架构的通信特点让我们必须要认为网络通信是不可靠的,这就导致在实现一致性上,微服务比传统的单体架构要复杂得多。假如采用补偿模式来实现数据的最终一致性, 就需要引入一个额外的协调服务,它负责协调各个需要保证一致性的微服务,其职责为协调服务并按顺序调用各个微服务,如果某个微服务调用异常(包括业务异常和技术异常), 就取消之前所有已经调用成功的微服务。同时,还需要考虑取消操作也可能失败的情况, 即补偿过程本身也需要满足最终一致性,这就要求在服务调用出现异常后,取消服务至少要被调用一次,而取消服务操作本身则必须是幂等的。
为了实现补偿模式,我们需要记录每次业务操作,同时还要确定失败的步骤与状态, 以便于定位补偿的范围。为了提高正常业务操作的成功率,还需要在设计时考虑引入重试 机制。服务执行失败的原因各有不同,重试机制也需要提供与之对应的策略。例如对于系 统繁忙的异常,我们应采用等待重试机制;对于一些出现概率非常小的罕见异常,可以考虑立刻重试;如果失败原因是由于某种业务原因导致的,那么即使重试也不可能保证操作成功,应采取终止重试策略。显然,这些机制都会因为微服务的分解而带来设计上的额外成本,它必然会导致整个系统的结构变得更加复杂。有得必有失,软件世界的自然规律其实是公平的。
在考虑微服务设计时,业界普遍认为服务分解与组织结构要保持一致,即遵循康威定律:
任何组织在设计一套系统(广义概念上的系统)时,所交付的设计方案在结构上都与该组织的沟通结构保持一致。
Sam Newman 认为是“适应沟通路径”使康威原则在软件结构与组织结构中生效 1 的。他分析了一种典型的分处异地的分布式团队,整个团队共享单个服务的代码所有权。由于分布式团队的地域和时区界限,使得沟通成本变高,团队之间只能进行粗粒度的沟通。当协调变化的成本增加后,人们就会想方设法降低协调/沟通成本。直截了当的做法就是分解代码,分配代码所有权,分处异地的团队各自负责一部分代码库,从而更容易地修改代码。团队之间会有更多关于如何集成两部分代码的粗粒度的沟通,最终,与组织结构内的沟通路径匹配所形成的粗粒度 API 形成了代码库中两部分之间的边界。
注意,匹配设计方案的团队是负责开发的团队,而非使用软件产品的客户团队。在软件开发中,常常会遇见分布式的客户团队,例如不同的部门会在不同的地理位置,他们的使用场景也不尽相同,甚至用户的角色也不相同,但在对软件系统进行架构设计时,却不能想当然地按照用户角色、地理位置或部门组织来分解模块(服务),并以为这遵循了康威定律。设计人员错误地把客户的组织结构视为系统模块(服务)的分解依据。
我曾经参与过一款通信产品的改进与维护工作。这款产品为通信运营商提供对宽带网的授权、认证与计费工作。该产品的终端用户主要有两种角色:营业厅的营业员与购买宽带网服务的消费者。
该产品的最初设计就自然而然地按照这两种不同的角色划分为后台管理系统与服务门户两个完全独立的子系统,而在这两个子系统中都存在资费套餐管理、客户信息维护等业务。
这种不合理的软件系统结构划分,属于典型的职责分配不合理,不仅会产生大量重复代码,还会因为结构失当而带来许多不必要的通信与集成,增加软件系统的复杂度。
国际报税系统的架构演进
在我参与的一个国际报税系统中,就根据用户的角色进行了系统分解。针对报税人, 设计了 Front End 模块提供报税等终端业务,而 Office End 模块则面向业务人员和系统管理者,如图 4.4 所示。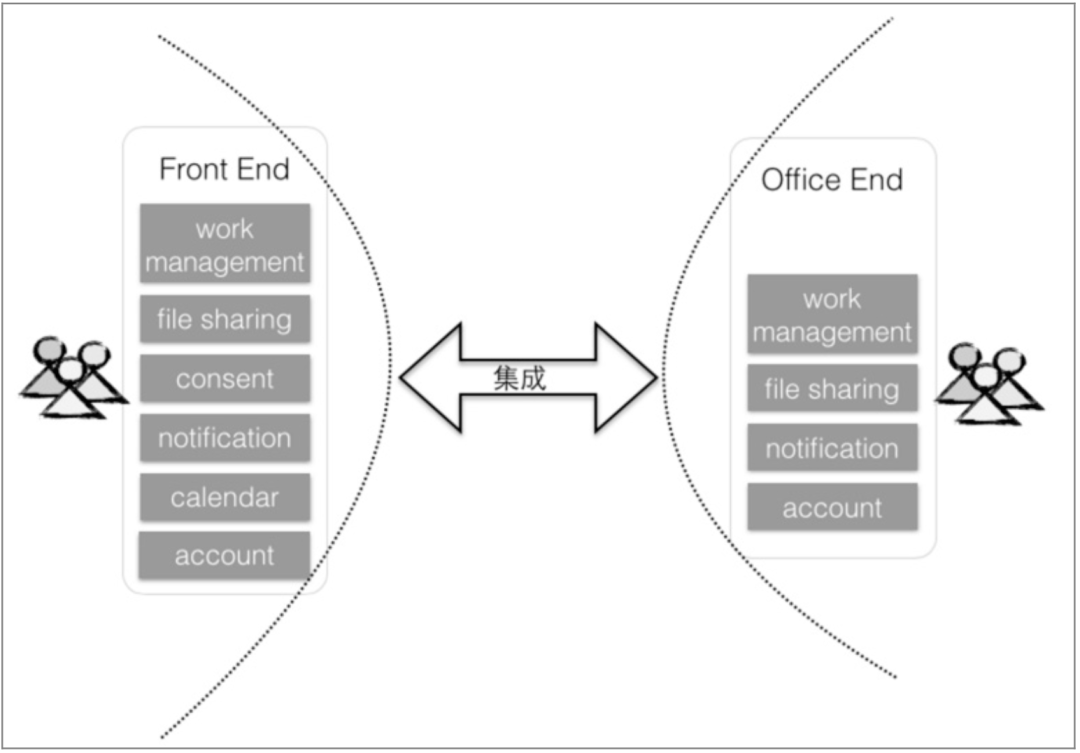 图 4.4
图 4.4
随着需求增多,功能越来越复杂,系统各个模块的边界开始变得越来越模糊,形成了一个逻辑散乱的庞大代码库。重复代码与重复数据俯拾皆是,而 Front End 与 Office End 之间的集成也非常复杂。负责开发这两个模块的团队虽然属于同一个项目组,但团队之间存在极大的技术和业务壁垒,团队成员对整个系统缺乏整体认识,知识没有能够在团队之间传递起来。
当通过引入 Bounded Context 来划分模块的边界,建立公开统一的 REST 服务后,遵循康威定律为分解开的服务建立特性团队(Feature Team)就演变为顺其自然的结果。整个系统中各个服务的重用性和可扩展性得到了更好的保障,服务与 UI 之间的集成也变得更加简单。整个架构清晰可见,如图 4.5 所示。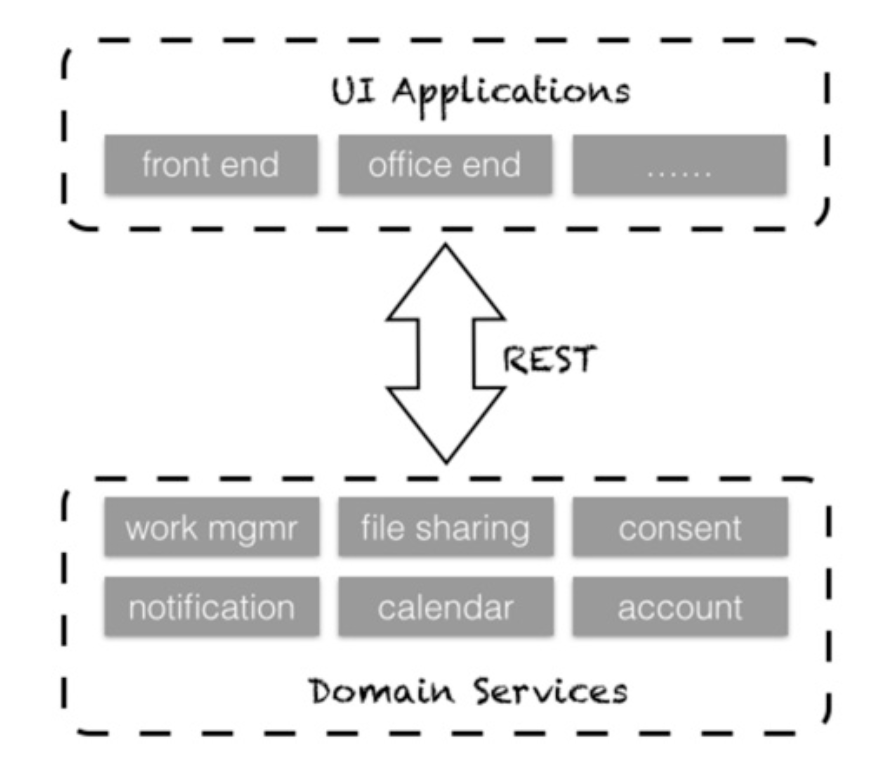 图 4.5
图 4.5
无论是优雅的设计,还是拙劣的设计,都可能因为某种设计权衡而导致系统结构变得复杂。唯一的区别在于前者是主动地控制结构的复杂度,而后者带来的复杂度是偶发的,是错误的滋生,是一种技术债,它可能会随着系统规模的增大而导致一种无序设计。
在 Pete Goodliffe 讲述的“两个系统的故事:现代软件神话” 中详细地罗列了无序设计系统的几种警告信号:
- 代码中没有显而易见的进入系统中的路径。
- 不存在一致性,不存在风格,也没有统一的概念能够将不同的部分组织在一起。
- 系统中的控制流让人觉得不舒服,无法预测。
- 系统中有太多的“坏味道”,整个代码库散发着腐烂的气味,是在大热天里散发着刺激气体的一个垃圾堆。
- 数据很少被放在使用它的地方。
- 经常引入额外的巴罗克式缓存层,目的是试图让数据停留在更方便的地方。看一个设计无序的软件系统,就好像隔着一层半透明的玻璃观察事物一般,系统中的软件元素都变得模糊不清,充斥着各种技术债。细节层面,代码污浊不堪,违背了“高内 聚、松耦合”的设计原则,导致许多代码要么放错了位置,要么出现重复的代码块;架构层面缺乏清晰的边界,各种通信与调用依赖纠缠在一起,同一问题域的解决方案各式各样, 让人眼花缭乱,仿佛进入了没有规则的无序社会。
架构与代码评审
我曾经为一个制造业客户开发的业务工具项目提供架构与代码评审的咨询服务。当时,该工具产品的代码库只有不到三万六千行代码,是一个简单的基于 ASP.NET 开发的 BS (Brower/Server)架构系统。虽然项目规模并不大,但是在经历了约半年的开发周期后,项 目质量与交付周期都不能得到足够的保证。在之前交付的版本中,位于欧洲的销售代表普遍对这个工具不满意,所以客户希望我们能够在技术层面上提供一些咨询建议。
该工具产品的开发存在诸多问题,例如在领域层充斥着大量的贫血对象,对框架的强依赖导致“供应商锁定”,在技术选型上也多有不当之处。但最大的问题还是系统缺乏清晰的边界,如图 4.6 所示。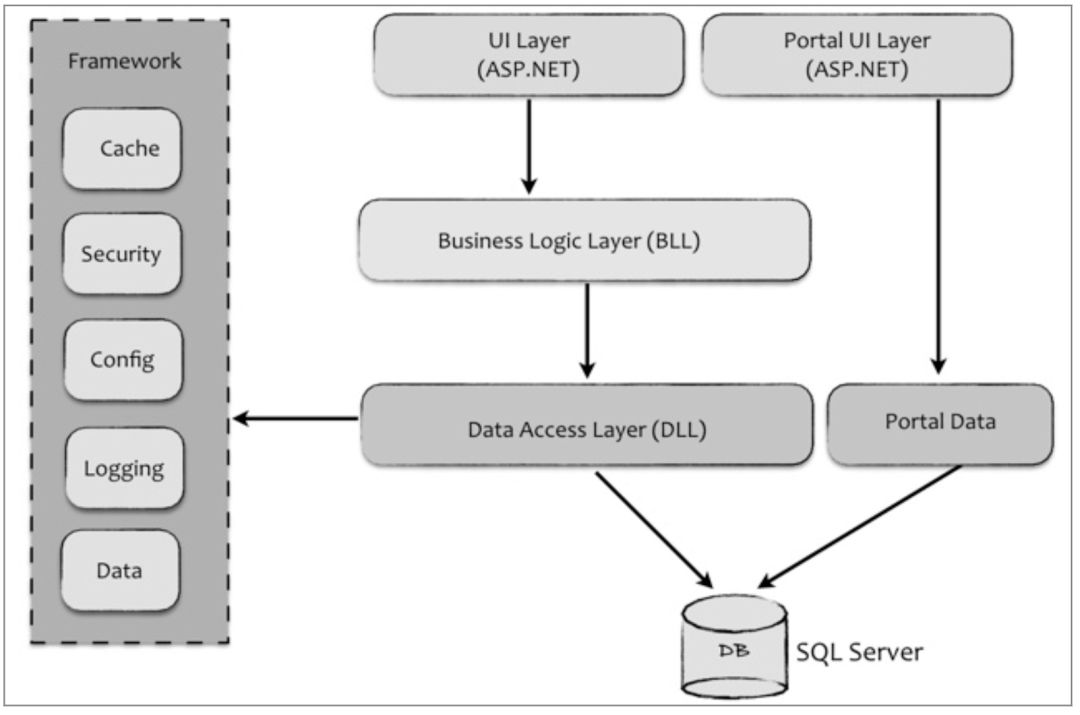 图 4.6
图 4.6
架构师虽然采用了经典的三层分层架构模式对关注点进行分离,却没有很明确地勾勒出各个分层的明确职责,开发人员也没有按照这种分层架构来分配职责,在本来应该是视 图呈现的代码中混入了许多领域逻辑,从而导致 UI 层越来越臃肿。而在领域层,却又不恰当地渗入了对 ASP.NET UI 组件的处理逻辑。该产品代码库存在的另一个问题是缺乏一致性。例如针对数据库的访问,产品竟然提供了如下三种不同的解决方案。
1. Utils 访问方式,其代码如图 4.7 所示。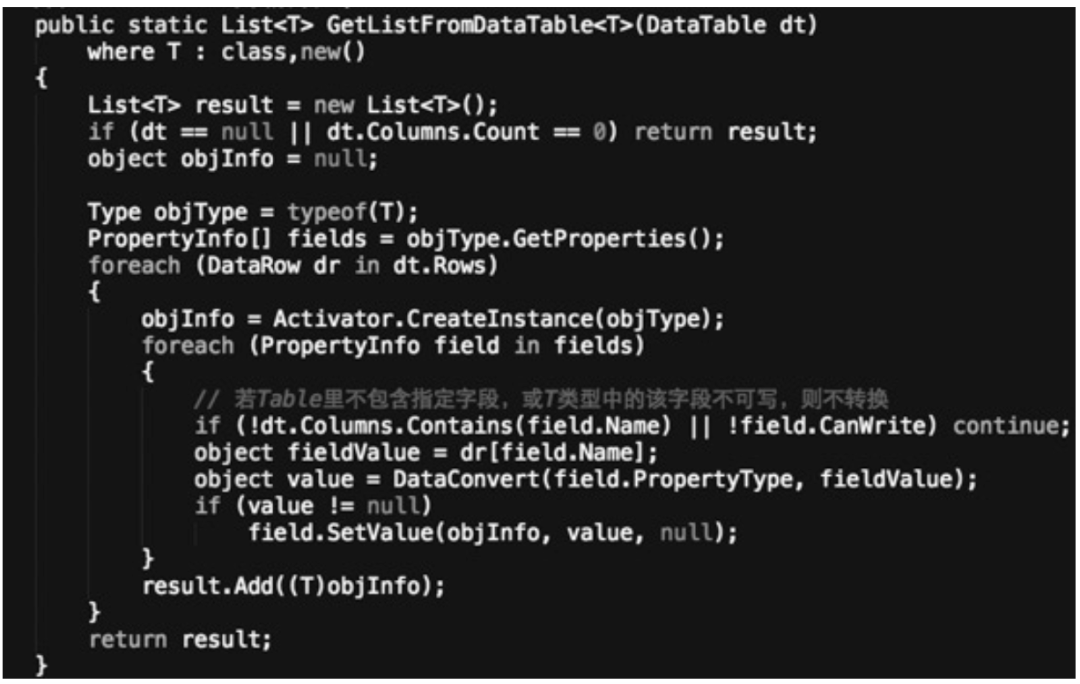 图 4.7
图 4.7
2. DbHelper 访问方式,其代码如图 4.8 所示。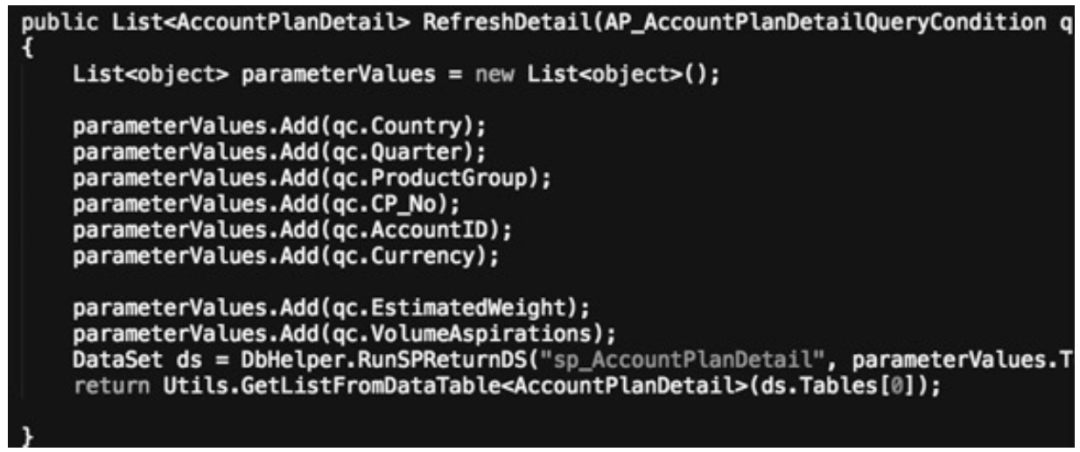
图 4.8
3. ORM 访问方式,其代码如图 4.9 所示。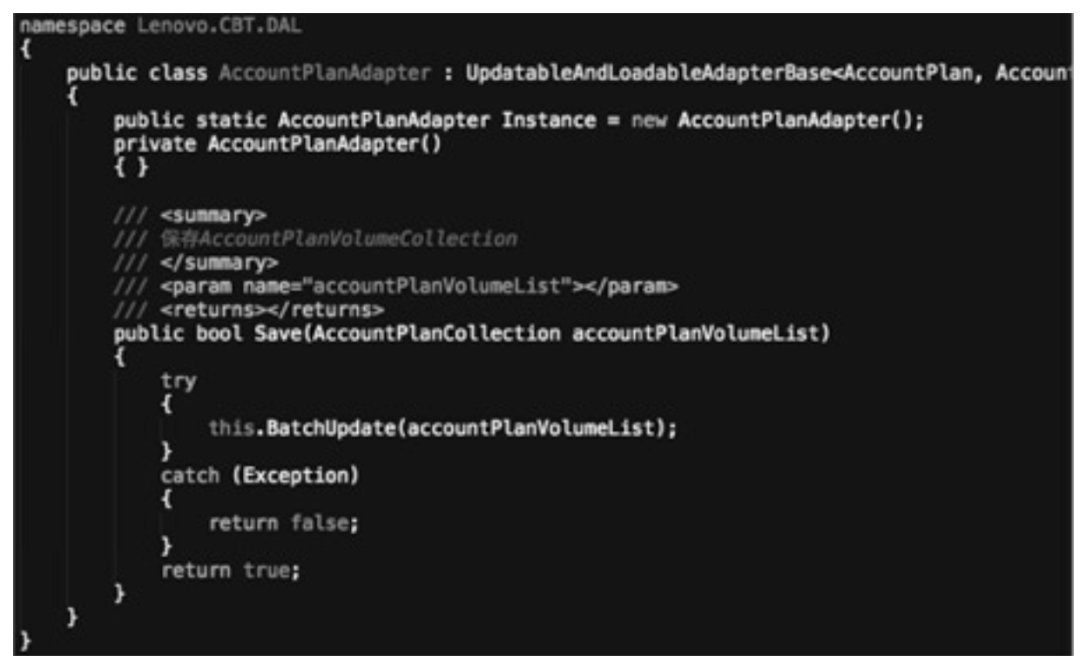
图 4.9
显然,选择这三种迥然不同的访问方式并非出于技术原因,又或者受到某个质量属性的约束,而是在设计时没有做到统一的规划,开发人员率性而为,内心会自然而然地选择自己最熟悉、实现成本最低的技术方案,从而导致访问数据库的解决方案不一致。
1.3变化
我们之所以不能预测未来,是因为未来总会出现不可预测的变化。这种不可预测性带来的复杂度使得我们产生畏惧,因为不知道何时会发生变化,变化的方向又会走向哪里, 所以导致心里滋生一种仿若失重一般的感觉。变化让事物失去控制,受到事物牵扯的我们便会感到惶恐不安。
在设计软件系统时,变化让我们患得患失,不知道如何把握系统设计的度。若拒绝对变化做出理智的预测,那么系统的设计会变得僵化,一旦变化发生,修改的成本就会非常大;若过于看重变化产生的影响,渴望涵盖一切变化的可能,则一旦预期的变化不曾发生, 我们之前为变化付出的成本就再也补偿不回来了。
从需求的角度讲,变化可能来自业务需求,也可能来自质量属性,而以对系统架构的 影响而言,尤以后者为甚,因为它可能牵涉整个基础架构的变更。George Fairbanks 在《恰如其分的软件架构》一书中介绍了邮件托管服务公司 RackSpace 的日志架构变迁,虽然业务功能没有任何变化,但是邮件数量却持续增长,为了满足性能需求,架构经历了三个完全不同的系统变迁:从最初的本地日志文件,到中央数据库,再到基于 HDFS 的分布式存储,整个系统几乎发生了颠覆性的变化。这并非 RackSpace 的架构设计师欠缺设计能力, 而是在公司草创之初,他们没有能够高瞻远瞩地预见到客户数量的增长,导致日志数据增多,以至于超出了已有系统支持的能力范围。
俗话说“事后诸葛亮”,当对一个软件系统的架构设计进行复盘时,总会发现许多设计决策是如此愚昧。殊不知这并非愚昧,而是在设计之初,我们手中掌握的筹码不足以让自己赢下这场面对未来的战争罢了。这就是变化之殇!(未完待续)

若有收获,就点个赞吧
0 人点赞

{kind=link}