算法40讲:
动态规划就是递推,由递归+记忆化演变而来
状态的定义:
比如:斐波拉契用一维数组表示、背包二维数组
状态转移方程:
当前状态 由什么子状态堆叠而来
最优子结构: 最优子结构 构成 全局子结构,最终值最优求得的同时 子结构的最优其实也是确定了的
dp vs 回溯 vs 贪心
回溯(递归): (特点:需要穷举所有可能,且尽量不存在重复计算
贪心:永远是局部最优
dp:记录局部最优子结构/多种记录值
左神书
搜索化记忆 与 动态规划:
换钱的方法数:
给定数组arr,arr中所有数都是正数且不重复,每个值代表以一种面值,可以使用任意张。给定target表示需要凑成的金额数。求一共有多少种方法。
这道题经典在可以体现:暴力递归、记忆搜索、动态规划之间的关系
暴力递归:
存在大量重复计算。
时间复杂度:一般为指数级别
记忆搜索:
准备好全局变量map,存储已经计算过的递归过程的结果。比如changeCall**(remain,start**);我们就以remain、start建立二维矩阵。即分析递归函数的状态由哪些变量控制。建立起对应维度的记忆矩阵。
时间复杂度:Nlenlen。 dp[I][J]的计算过程即枚举矩阵的值,一共 Nlen个位置,一共要计算len个数据。
动态规划:
记忆化搜索其实就是单纯地对计算过的递归过程进行记录,不关心某个递归过程的路径。
动态规划:规定好每个递归的计算顺序,依次进行计算。后计算的过程严格依赖前面计算过的过程。即动态规划严格规定了计算顺序,可以将*递归计算变成顺序计算。
知乎:
找零兑换最少张数的问题:一个至关重要的启示——  只与
只与  相关。
相关。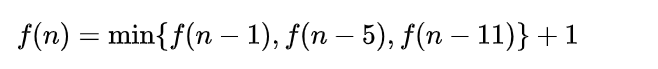
原理:
我们只关心f(w)的值 但是不关心怎么凑出来的。====》 是不是很像函数式?
这就是dp:将一个问题拆成几个子问题,分别求解这些子问题,即可推断出大问题的解。
一些概念:
- 无后效性:“未来与过去无关”,这就是无后效性(**每个当前状态会且仅会决策出下一状态,而不直接对未来的所有状态负责) 也不关心如何得到的。**无后效性,指状态间的转移与如何到达某状态无关
- 最优子结构:大问题的最优解可以由小问题的最优解推出,这个性质叫做“最优子结构性质”
什么问题适合dp?能将大问题拆成几个小问题,且满足无后效性、最优子结构性质。
dp为什么快?==》 dp自带剪枝 + dp是累加结果 充分利用了前面的解
无论是DP还是暴力,我们的算法都是在可能解空间内,寻找最优解。
(在一个困难的嵌套决策链中,决策出最优解)
暴力做法是枚举所有的可能解,这是最大的可能解空间。DP是枚举有希望成为答案的解。这个空间比暴力的小得多。
即dp自带剪枝。
DP舍弃了一大堆不可能成为最优解的答案。譬如:
15 = 5+5+5 被考虑了。
15 = 5+5+1+1+1+1+1 从来没有考虑过,因为这不可能成为最优解。
DP的核心思想:尽量缩小可能解空间
dp**两大关键:1、状态的定义。2、dp的转移方程:可以从两个角度思考。我从哪里来 or 我要到哪里去
实现dp的两种方式:1、按顺序递推 2、记忆化搜索
知乎:
动态规划是对于 某一类问题 的解决方法!!重点在于如何鉴定“某一类问题”是动态规划可解的而不是纠结解决方法是递归还是递推。
计算机本质是一个状态机:当你企图使用计算机解决一个问题是,其实就是在思考如何将这个问题表达成状态(用哪些变量存储哪些数据)以及如何在状态中转移(怎样根据一些变量计算出另一些变量
所以所谓的空间复杂度就是为了支持你的计算所必需存储的状态最多有多少,所谓时间复杂度就是从初始状态到达最终状态中间需要多少步。
理解 阶段 和状态。 阶段:递归的哪一层 or 从开始走到当前步,当前步就是一个当前阶段。一个阶段可以对应多个状态。比如棋盘从左上走到右下,每一步可以往右走或者下走,那么走到第x步的时候,此时对应的棋盘状态是多种的。
好消息是:我们有时并不需要计算所有的状态==》 dp自带剪枝
某个阶段确实可以有多个状态,正如这个问题中走n步可以走到很多位置一样。但是同样n步中,有哪些位置可以让我们在第n+1步中走的最远呢?没错,正是第n步中走的最远的位置
因为 下一步最优是从当前最优得到的。
《《《《《《《《《《《《《《《《《《《分界线》》》》》》》》》》》》》》》》》》》》》》》》》》
一个问题是该用递推、贪心、搜索还是动态规划,完全是由这个问题本身阶段间状态的转移方式决定的。
每个阶段只有一个状态->递推;
==》 斐波拉契数列:F(n) = F(n-1) + F(n-2) 不用关心选择哪些状态
只需要依照固定的模式从旧状态计算出新状态就行。不需要考虑是不是需要更多的状态,也不需要选择哪些旧状态来计算新状态
每个阶段的最优状态都是由上一个阶段的最优状态得到的->贪心;
===》 目光短浅。核心思想是每一步都选的当前步的最优
每个阶段的最优状态是由之前所有阶段的状态的组合得到的->搜索;/ 回溯?
===》 组合:搜索化记忆。
每个阶段的最优状态可以从之前某个阶段的**某个或某些状态直接得到(最优子结构**)而不管之前这个状态是如何得到的**(无后效性)**->动态规划。
分治 、递归、枚举:
分治、可以迭代实现 可以递归实现。 分治是一个思想,递归只是分治法的一种表现形式。
在递归和分治基础上,常常可以使用dp优化,可以看成dp是升级版的递归、或者说是 穷举的优化**。(深得我心**
不是所有的穷举都可以分治,分治是子问题可分的。
也不是所有的分治可以优化成dp,分治出的子问题求解有重叠,使用dp才有意义。且只有子问题具有最优子结构,才能使用dp。
而dp最难的地方就是 状态的定义,一个状态定义好了问题成功了一大半。
而对状态的定义往往是充分理解题目、抓取出变量、状态传递、归根上是 建模的过程。
高度抽象:
动态规划是寻找一种对问题的观察角度,让问题能够以递推(或者说分治)的方式去解决。寻找看问题的角度,才是动态规划中最耀眼的宝石
dp的特征:
1、把原问题拆分成几个相似的子问题
2、所有子问题只需要计算一次。
3、存储子问题的解
dp问题的求解步骤:
1. 状态是什么
2. 状态转移方程是什么
3. 状态的初始值是什么
4. 问题要求的最后答案是什么
**

若有收获,就点个赞吧
0 人点赞
