/****** 由浅入深* 总结我见过的递归写法、return传数据、函数传参、全局变量*** 我想不到的递归函数设计**/let arr = [2,1,5,8,3,0,4],target = 3;let targetIndex = find(arr,target)console.log(targetIndex);// 4function find1(arr,target){for(let i=0;i<arr.length;i++){if(arr[i]==target){return target;}}return null;}/***** 横向遍历转竖向遍历的思想:* 判断逻辑:* 每次还是判断数组的arr[1],* 遍历控制-变化的量:* 只是变化的不是循环指针i* 而是 数组arr, 每判断一次,就将判断过的元素从数组里消去,自然下一个元素arr[1]就变成了arr[0]* 遍历控制-结束的条件:* 循环: i> arr.length 就结束了* 递归: 由于是传入的数组在变化,在不断的缩小,* 所以遍历的结束条件:传入的arr小无可小* 逻辑结束条件:* 找到 target*/
我理解的递归
:::info
1、竖向的遍历
好处:遍历标记不再是全局变量,而是小块的分量规划;
2、复用逻辑
将一大段数据的处理用迭代的方式是全局变量记录着,统一处理当下的小部分逻辑;
而递归:不需要大遍历的全局变量统筹遍历逻辑,直接复用逻辑,而需要做的就是将大块拆分成小块;
3、多线程同时处理小问题:
也就是分治的思想啦~
如果小问题的处理过程并不依赖于其他小问题,那么完全可以同时进行多个小问题的处理,同时开多个小问题的递归口。
4、逻辑简单:
比如:斐波拉契数列:(所以递归有时又叫做暴力递归)
比如二叉树的遍历,迭代的方式和递归的比较;
5、即竖向又横向的遍历:
回溯;
6、从递归到动态规划
动态规划就是递归方程式的填格子;
:::
递归的初级理解是:竖向的遍历
更透彻的理解:递归是分治的思想,全局分化各个局部,各个局部有着相似的处理逻辑进而也是用相似的递归模板解决即可。
以求最大深度为例子:
遍历思路: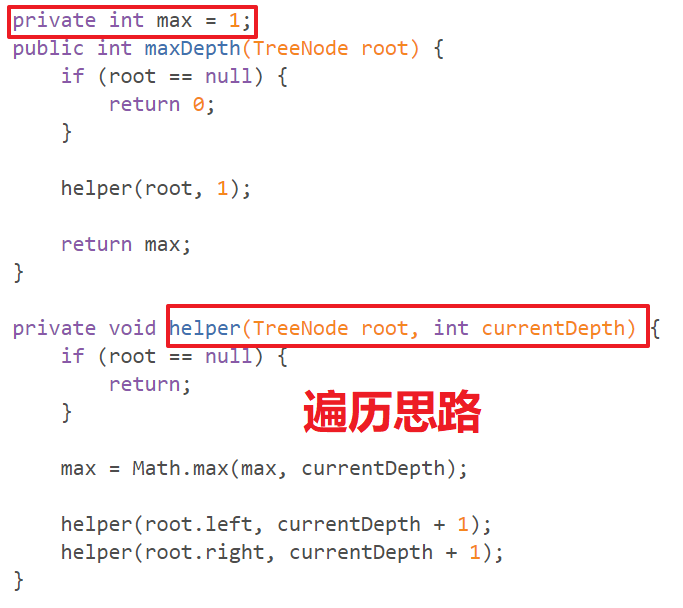
全局变量 max 来记录当前访问过的所有节点中的最大深度,把整个二叉树遍历一遍,每个节点都记录一下当前的深度,然后对比求出最大深度即可
# 分治思想function maxDepth(root){if(root==null) return 0;let lDepth = maxDepth(root.left);// 左子树高度let rDepth = maxDepth(root.right);// 右子树高度return Math.max(lDepth,rDepth)+1;}
竖向的遍历
无序数组返回target
假如给定一个不包含重复元素的无序数组,请在数组里找出值为target ,若存在返回target。(若不存在返回 null )
期望:
let arr = [2,1,5,8,3,0,4],target = 3;
let targetIndex = find(arr,target)
console.log(targetIndex);// 3
1、普通的迭代(循环)法
**
function find(arr,target){
for(let i=0;i<arr.length;i++){
if(arr[i]==target){
return target;
}
}
return null;
}
2、竖向遍历(递归)
/**
横向遍历转竖向遍历的思想:
判断逻辑:
每次还是判断数组的arr[0],
遍历控制-变化的量:
变化的不是循环指针i
而是数组arr, 每判断一次,就将判断过的元素从数组里消去,自然下一个元素就从arr[1]变成了arr[0]
遍历控制-结束的条件:
循环: i> arr.length 就结束了
递归: 由于是传入的数组在变化,在不断的缩小,所以遍历的结束条件:传入的arr“小无可小”
逻辑结束条件:
找到 target
/
function find(arr,target){
// 相当于 循环遍历的i > arr.length了
if(arr.length<1){
return null;
}
if(arr[0]==target){
return target;
}
/***
* let arr1 = [1,2,3]
* console.log(arr1.slice(1));// [2,3]
* 每次传入在原数组基础上去掉第一个元素的新数组
*/
return find(arr.slice(1),target);
}
疑惑:为什么函数可以自己调用自己呢?for循环的执行步骤我是知道的,那么递归的执行步骤是怎样的呢?
为什么return 函数的值就可以得到 整个问题的解了呢?
==> 递归调用栈的知识。
递归的深入: 参数在不断缩小的变化,调用的一个个函数会入系统维护的函数调用栈;
当达到触底条件: 不再 return 函数,而是return 一个具体的值 或者直接return的时候,
就是我们捡到了山芋往山上跑的过程,期间回来会经过一个个他曾经的入口,就是之前深入的时候调用的那个函数,他会回到那个环境,那个环境有当时的变量。
此时的山芋就是那个函数的返回值,在当层函数处理中,是直接 return 了那个函数,即return 山芋,所以山芋又往上跑。
重回山顶: 调用栈为空,回到了第一层函数。
此时就是直接返回 山芋 即为结果值了
递归结果简单加工
// 计算简单
计算n的阶乘 n!
function getFactorial(n){
if(n<0) return -1;
if(n==0) return 1;
return n*getFactorial(n-1);
}
递归状态变量的记录-单路递归路
状态变量的传递(我称之为 伴随变量 ),我知道的有以下几种方式:
- 入口处新增变量—函数参数
- 全局变量记录
无序数组返回target的下标
刚才的竖向遍历的例子,找到目标元素返回元素这个操作是有点傻,现在我们修改一下需求,找到元素返回元素所在数组的下标,即实现arr.indexOf(target) 的功能
1、横向遍历
function find1(arr,target){
for(let i=0;i<arr.length;i++){
if(arr[i]==target){
return i;
}
}
return -1;
}
2、竖向遍历
**
如下是之前(要求返回target)的需求下写的递归代码,如果我们要返回下标,这就尴尬了,因为我们并不知道下标,在每一层的处理中,并没有保存当前层的下标。
这里,就涉及到了递归过程的数据处理除了结果值以外,还需要其他状态变量,辅助描述这层调用的环境的变量。
而状态变量的传递(我称之为 伴随变量 ),我觉得以下几种方式:
- 入口处新增变量—函数参数
- 全局变量记录
这里我们修改函数参数,多一个记录当前比较元素的下标。由于原函数只能接受两个参数,所以我们需要写一个新的辅助函数,即不再原函数里递归了,我们递归辅助函数,辅助函数的最终返回值就是原函数需要的结果
// 原需求下的递归函数
function find(arr,target){
if(arr.length<1){
return -1;
}
if(arr[0]==target){
return target;
}
return find(arr.slice(1),target);
}
// 新需求的递归函数-函数传参的方式传递状态变量
function find(arr,target){
// 刚开始从0开始
let result = findCall(arr,target,0);
return result;
function findCall(arr,target,index){
if(arr.length<1){
return -1;
}
if(arr[0]==target){
return index;
}
return findCall(arr.slice(1),target,index+1);
}
}
伴随着函数的下标值,相当于横向的i++,只是这是竖向的,转为了函数传参的方式;
// 新需求下的递归函数-改变全局变量的形式记录状态变量
由于需要区分全局变量,所以单独写了新的函数作为递归函数,递归函数的状态变化由每一层的函数可以去修改,代表当前遍历到了哪个位置。
我们的递归函数并没返回什么,因为不需要数据的传递,当递归遇到触底的时候只需要返回即可。
function find(arr,target){
// 刚开始从0开始
let curIndex = -1;
findCall(arr,target);
return curIndex;
function findCall(arr,target){
if(arr.length<1){
// return null;
return;
}
if(arr[0]==target){
// return index;
curIndex++;
return;
}
curIndex++;
findCall(arr.slice(1),target);
}
}
// 新需求下的递归函数-
使用全局变量的方式不好的地方在于 还得重新定义个递归函数,使得全局变量是函数里的全局变量
而 第一种方法的伴随变量,不好的地方在于,重新定义函数的入参,依赖于外部调用的改变。
这里介绍第三种,结合了上面两种的优点
这里纠正一个观点,递归函数里 新定义一个变量并返回一个变量,
你可能会疑问了:递归函数里新定义变量?return的值还依赖于这个变量,那下次递归进入的时候又重新赋值了这样的方式代替伴随变量确定好使吗?
秘诀就在于:会对这个变量进行赋值更新
比如dom的深度优先遍历 记录经过的所有父节点:**
# 伴随变量的方式
let deepTraversal1 = (node, nodeList = []) => {
if (node !== null) {
nodeList.push(node)
let children = node.children
for (let i = 0; i < children.length; i++) {
deepTraversal1(children[i], nodeList)
}
}
return nodeList
}
# 两全其美的方式
let deepTraversal2 = (node) => {
let nodes = []
if (node !== null) {
nodes.push(node)
let children = node.children
for (let i = 0; i < children.length; i++) {
nodes = nodes.concat(deepTraversal2(children[i]))
}
}
return nodes
}
**
二分查找
二分查找的递归写法,关键是理清每次比较的关键步骤,需要哪些必备变量,抓住关键的核心逻辑代码,我们要重复的地方就是被抽取成递归函数的递归主体。
二分查找,返回 查找对象的index:
==> 递归深处就是 arr[mid] ==target ,return mid; 从最深处的最底得到这个数据 再逐渐往上弹递归栈,每一层都是在传递这个值。
function search(arr,target){
if(arr==null || arr.length<1) return -1;
return searchCall(0,arr.length-1);
// 每一层的return值:要么取决于下一层 要么是底层的return触底反弹;
// 期间不需要对return的值进行累加 或者 结合 或者 变形 等加工处理
function searchCall(lIndex,rIndex){
if(lIndex>rIndex) return -1;// 特殊return 底层的更底层
let mid = (lIndex + rIndex)/2>>0;
if(target>arr[mid]){
return searchCall(mid+1,rIndex);
}
else if(target<arr[mid]){
return searchCall(lIndex,mid-1);
}
else{
return mid;
}
}
}
多路递归-同一层2个并行子路
典型特点就是 当层路 对应两种或以上 子路, 且子路都是要走的,不是 互斥的。
表现形式:
- 走完了左边再走右边; 这里的左是逻辑意义的左,把先行的那个递归分量 当成左子树;
典型例题:
- 二叉树的遍历、斐波拉契、括号生成
思路图:
- 针对每种情况细化不同情况,最终形成递归树
括号生成
输入n==3,输出所有所有可能的并且有效的括号组合
[
“((()))”,
“(()())”,
“(())()”,
“()(())”,
“()()()”
]
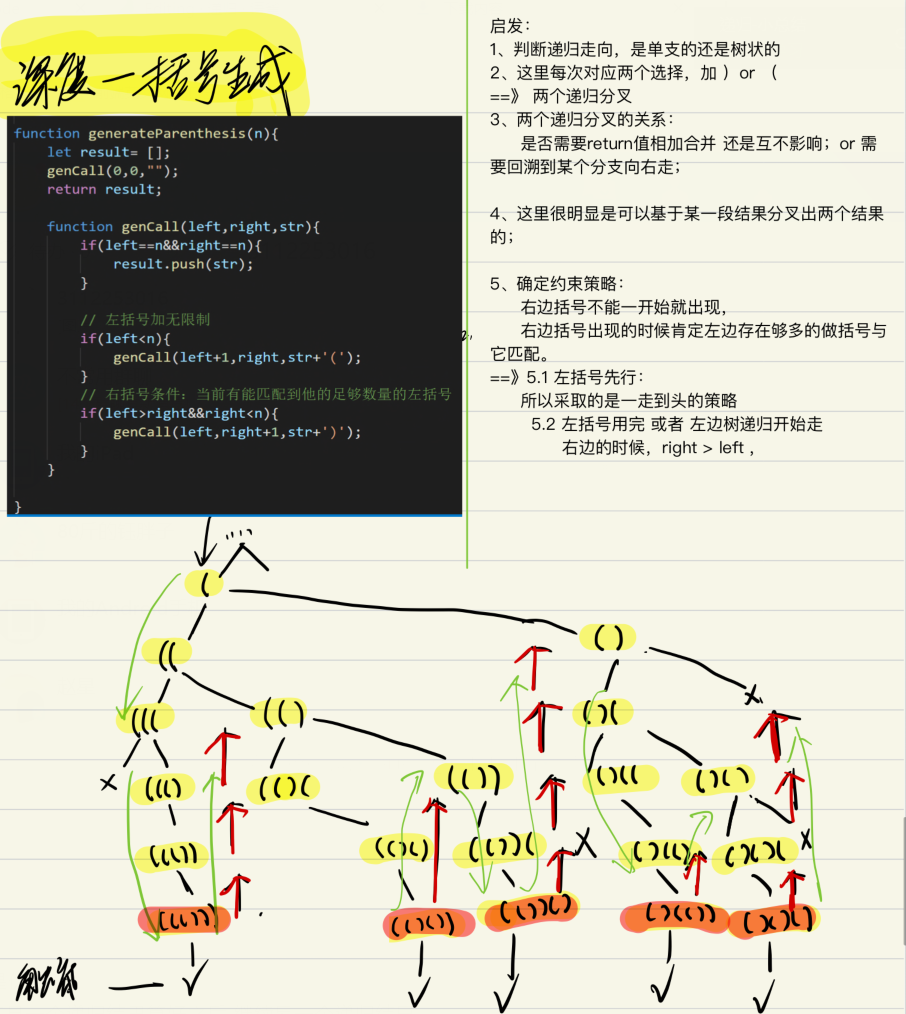
斐波拉契数列
每一层不止一个递归函数,典型代表:
斐波拉契(及其相关的:爬楼梯、奶牛生子、)

多路递归-同一层多个并行子路
其实这个很好理解,竖向的递归在横向遍历里面,之前是两路选择,现在由循环决定出了多路分支;
之前的两路分支在右递归回溯之后 无路可走了所以 弹栈回到上层;
这个循环里的递归结束了,接着继续循环。知道循环完毕才是 弹栈;
常见于回溯算法。
代码表现形式:
- 2个子路时:call() call() 先左后右
- 多个子路时:for循环子路,依次调用递归函数
典型例题:
多叉树的遍历、
解题关键是画出 递归树,每个节点的值不能重复
全排列组合子集系列
常见情况:
| 全排列
包含重复数字
元素只能用一次 | 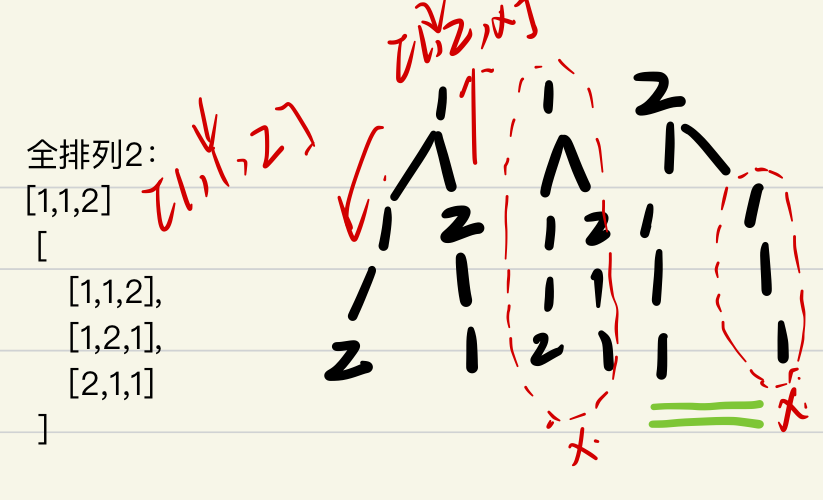 | 元素只能用一次,且排列与顺序有关。
| 元素只能用一次,且排列与顺序有关。
所以,用start记录下个开始的字符位置不妥
因为2还要用[1,1,2] 2之前的元素1来排列形成新解
那么标记剩下的可选条件的手段:
- 记录当前用过的元素usedArr
评判元素重复有两个维度:
- 本层新加的元素;比如[2]=>[2,1]就不能形成[2,2]
- 与之前的元素开篇冲突,比如[1,xx]与[1,xx];图中树的第二列可解释
结果记录:
- 结果记录在pathArr上,是状态变量,随着递归不断丰富;
递归结束条件:
- 数据收集全了==> pathArr.length==[1,1,2].length
|
| —- | —- | —- |
| 组合求和
元素不重复,
值可以重复用 |
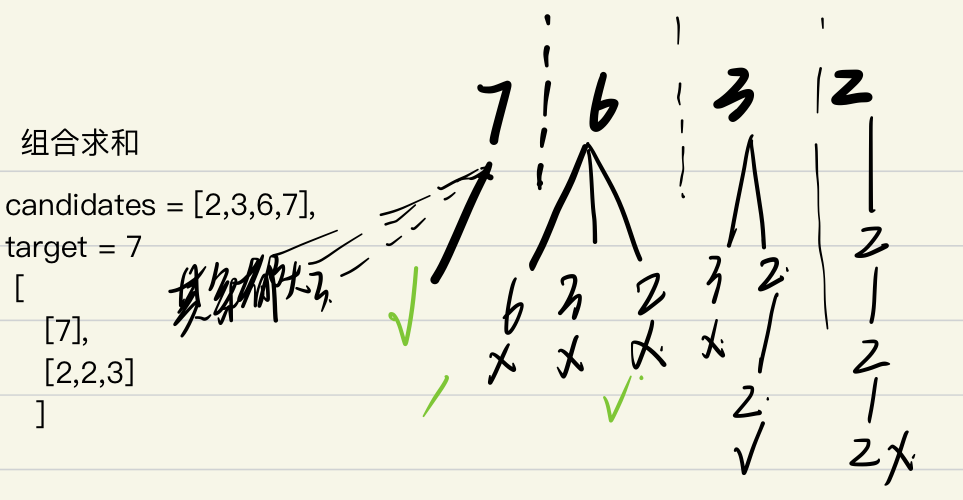 | 标记剩下的可选条件:
| 标记剩下的可选条件:
- 记录当层最多需要和 remain
- 与顺序无关,且有很明显的只遍历当前元素及其以后的,所以start记录下层开始的字符位置
结果记录:
- pathArr
递归结束条件:
- 判断remain
|
| 组合求和2
元素重复,
元素只能用一次 |
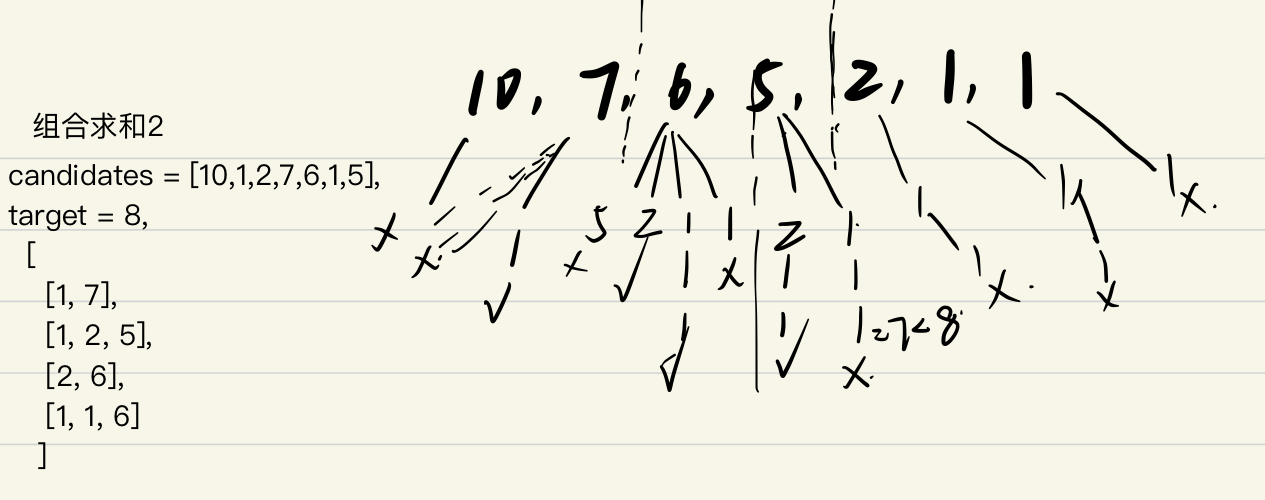 | 一旦所给值有重复,就要对重复枝进行裁剪;
| 一旦所给值有重复,就要对重复枝进行裁剪;
标记剩下的可选条件:
- remain
- start记录下层开始的字符位置
判重:(与顺序无关)
- 竖向的重复:之前用过的不会再用,因为有start开始标记
- 横向重复:nums[i-1]==nums[i]
结果记录:pathArr
递归结束条件:remain |
| 子集
不含重复元素 |
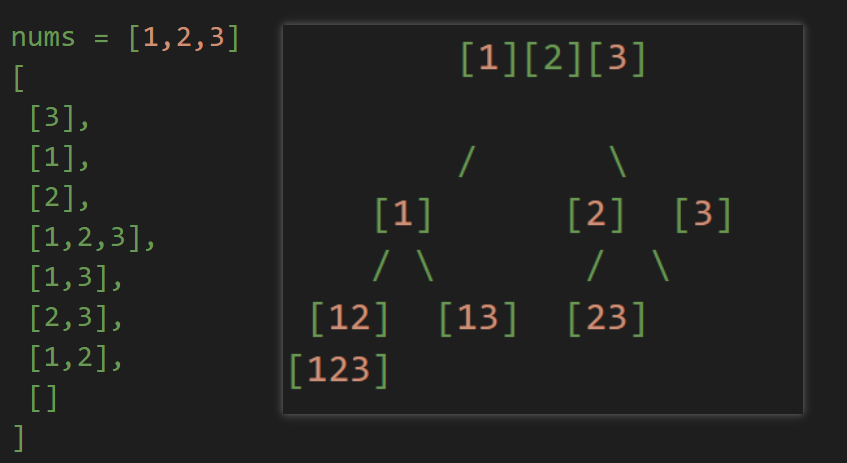 | 与顺序无关,所以每次只看当前元素之后的
| 与顺序无关,所以每次只看当前元素之后的
标记剩下的可选条件:
- start
结果记录:pathArr
路径arr不是触底了才是结果,过程产生的每个值就是一个结果分量;
递归结束条件:
没有很明显的递归结束符,每一层遍历完了就是结束; |
| 子集
包含重复元素 |
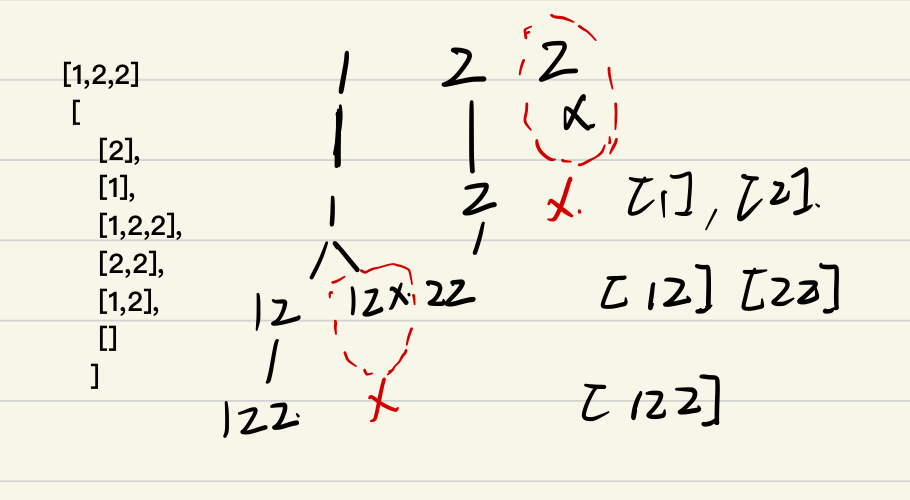 | 预处理:排序
| 预处理:排序
与顺序无关:start标记
递归结束:每层遍历完就是结束
去重:与组合求和2 一致 |
分割回文串
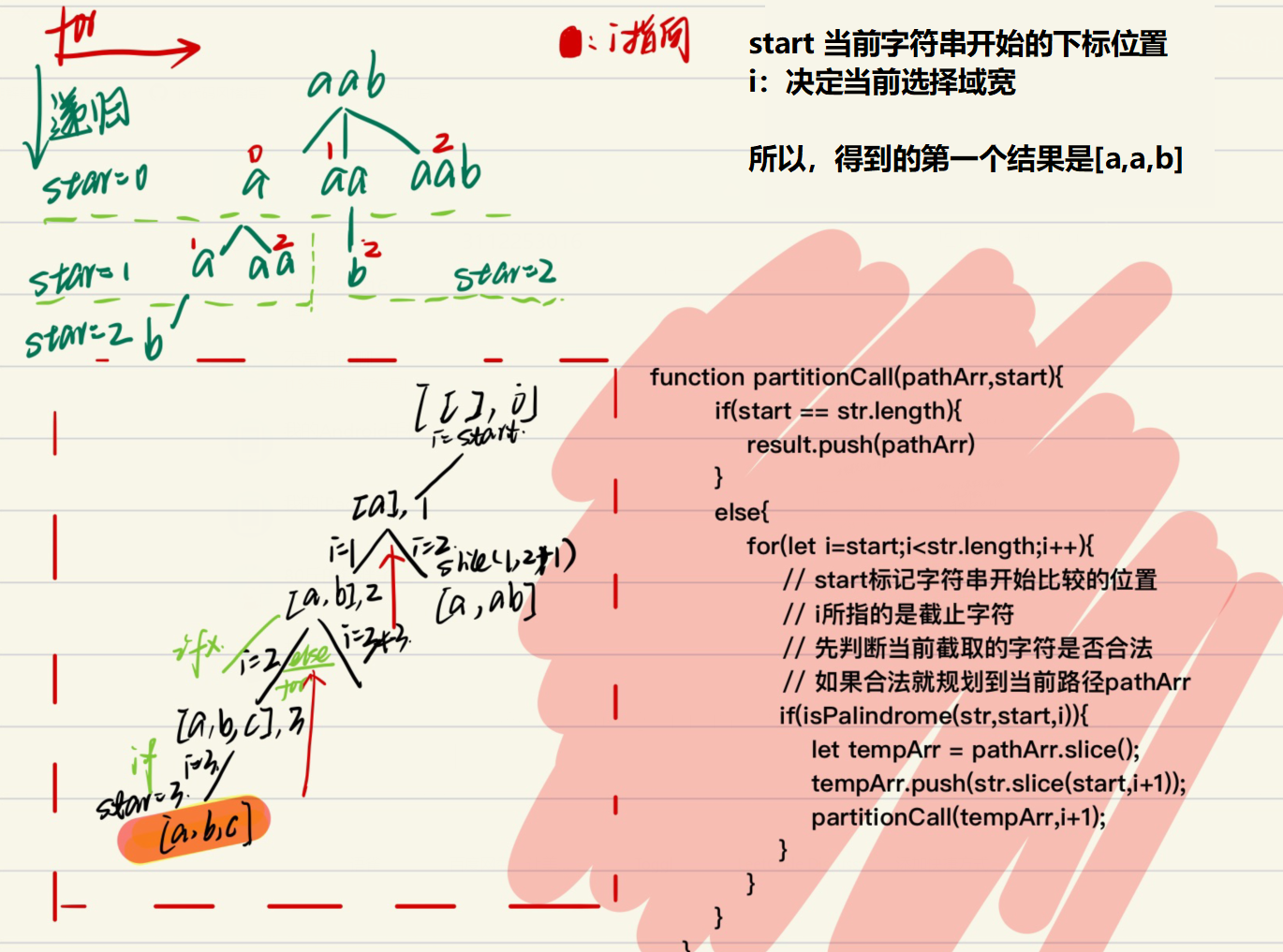
递归A套递归A+其他递归
递归函数一般是:自己调用自己
这里的递归则是:FuncA() = subFuncA() + FuncB(); FuncB = subFuncB
函数A调用两个递归函数,其中一个是调用自己,另一个是调用其他递归函数
典型例题:
二叉树路径和-非必须根节点及叶节点
树的子结构
二叉树路径和-非必须根节点及叶节点
每个结点都存放着一个整数值,找出路径和等于给定数值的路径总数。
路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
// 10
// / \
// 5 -3
// / \ \
// 3 2 11
// / \ \
// 3 -2 1
// sum = 8
// 三条路径
// 1. 5 -> 3
// 2. 5 -> 2 -> 1
// 3. -3 -> 11
function pathSum(root,sum) {
if (!root) return 0;
// 选root + 不选root:左子树 and 右子树
return pathSumOnlyStart(root, sum) + pathSum(root.left, sum) + pathSum(root.right, sum);
// 选root
function pathSumOnlyStart(root,sum) {
if (!root) return 0;
const self = root.val == sum ? 1 : 0;
// 只有root的情况 + 选了root之后:左子树 + 右子树
return self + pathSumOnlyStart(root.left, sum - root.val) + pathSumOnlyStart(root.right, sum - root.val)
}
}
树的子结构
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
// A:
// 3
// / \
// 4 5
// / \
// 1 2
// B:
// 4
// /
// 1
// return true
function isSubStructure(A, B) {
if (A == null || B == null) return false;
return DFS(A,B) || isSubStructure(A.left, B) || isSubStructure(A.right, B);
function DFS(A,B) {
if (B == null) return true;
if (!B && A == null) return false;
return A.val === B.val && DFS(A.left, B.left) && DFS(A.right,B.right);
}
}
其他
以上是从递归函数的整体代码结构上思考的问题,
我们在看看在递归函数内部,需要注意的细节点
- 一行代码 写在 递归函数之前 和 之后的变化
(递归之后的 node是当前层的,res确实最新的)、递归函数之后的代码是回溯阶段做的事(比如反转链表)
再一个关于递归触底,回溯的典型例子:归并排序
可以分三步走:分解 -> 解决 -> 合并
- 分解原问题为结构相同的子问题。
- 分解到某个容易求解的边界之后,进行第归求解。
- 将子问题的解合并成原问题的解。
void merge_sort(一个数组) { if (可以很容易处理) return; merge_sort(左半个数组); merge_sort(右半个数组); merge(左半个数组, 右半个数组); }
分解 -> 解决(触底) -> 合并(回溯) 啊,先左右分解,再处理合并,回溯就是在退栈
怎么更好的设计递归结构、递归代码的优化
1、只有一个伴随变量-且return的值就是函数的结果值:使用return伴随变量 代替全局变量
如反向打印链表
2、伴随变量需要多个,需要清楚地知道每一层递归后伴随变量的变化: 此时肯定全局变量不靠谱啦
=》return {} 对象
如:完全二叉树节点个数 的O(h^2)解法
# 反向打印链表
function reversePrint(head) {
if (!head) return [];
let arr = [];
reversePrintCall(head);
return arr;
function reversePrintCall(head) {
if (!head) return;
head.next && reversePrintCall(head.next);
arr.push(head.val);
}
}
// 优化
function reversePrint(head) {
if (!head) return [];
let res = reversePrint(head.next);
res.push(head.val);
return res;
}
# 完全二叉树的个数
function countNodes(root) {
if (!root) return 0;
const {depth, isfull} = checkFullTree(root);
if (isfull) return 2**depth-1;
return 1 + countNodes(root.left) + countNodes(root.right);
function checkFullTree(root) {
let p1 = root;
let p2 = root;
let rHeight = 0;
while(p2) {
p1 = p1.left;
p2 = p2.right;
rHeight += 1;
}
return {
depth: rHeight,
isfull: p1 ? false : true
};
}
}

若有收获,就点个赞吧
0 人点赞
