一、参数分析
对比Bert,TEXTCNN,BILSTM,LSTM,BERT-LightGBM
Bert
Embedding参数
分为:词向量参数,位置向量参数,块向量参数(bert用了2个句子,0和1)
Bert的vocab_size=30522,hidden_size=768,max_position_embeddings=512,token_type_embeddings=2
embedding参数 = (30522+512 + 2)* 768
Transformer
多头注意力
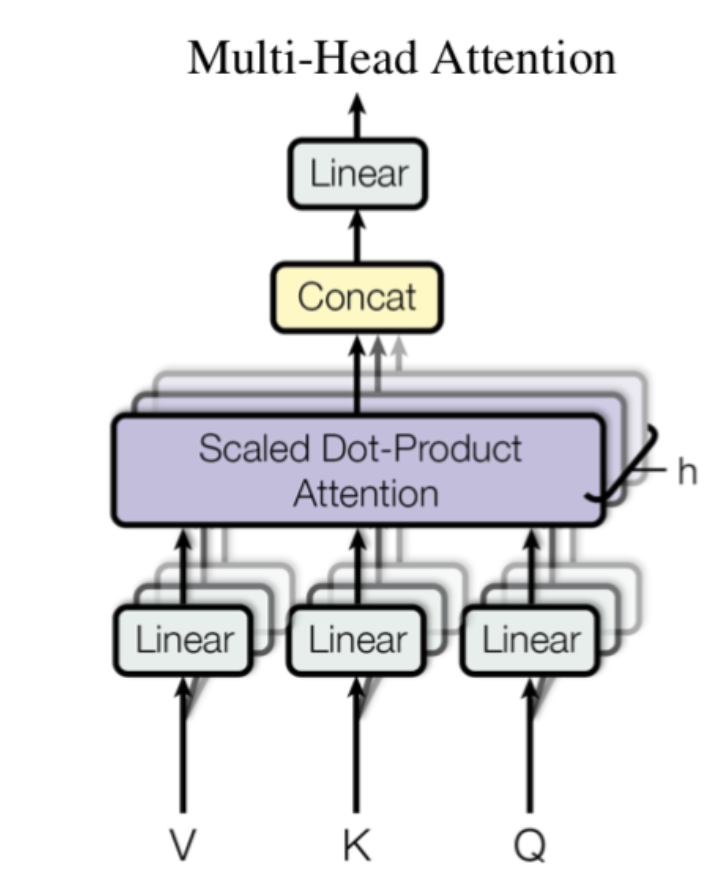
对QKV的向量均进行了不同的线性变换,引入了三个参数,W1,W2,W3。其维度均为:768 x 64
单head的参数:768 768/12 3,而head的数量为h=12,所以多头的参数:768 768/12 3 12
之后将12个头concat后又进行了线性变换,用到了参数Wo,大小为768 768
因此multi-heads的最终参数:768 768/12 3 12 + 768 768
全连接层
用到了两个参数W1和W2,大小为768 3072,2个为 2 768 * 3072。
LayerNorm
词向量层和Transformer中都用了
768 2 + 768 2 2 12
Bert汇总
词向量参数(包括layernorm) + 12 (Multi-Heads参数 + 全连接层参数 + layernorm参数)= (30522+512 + 2) 768 + 768 2 + 12 (768 768 / 12 3 12 + 768 768 + 768 3072 2 + 768 2 2) = 108808704.0 ≈ 110M
TEXTCNN
feature map和max pooling没有可训练参数
主要参数为:
- 卷积核数量*卷积核尺寸
- 最后一层的全连接

LSTM
以输入维度为30522,隐藏层维度为768的模型为例:
RNN有24M个参数:
- 每个输入层神经元与循环网络层神经元全连接,故从输入层到循环网络层有,768x30522=23440896个参数;
- 每个循环网络层中的神经元会把输出转给同层其它神经元,故循环神经元有768x768=589824个参数;
- 每个循环网络层中的神经元会配一个bias,因此还有额外768x1=768个参数;
LSTM有96M个参数:
- 相比于简单的RNN,LSTM每个细胞单元会有3个门:更新门、遗忘门、和输出门;
- 更新门:有一组w(权重)和bias偏移 输出门:有一组w(权重)和bias偏移
- 遗忘门:有一组w(权重)和bias偏移 + tanh的一组(权重)和bias偏移
- 即每个细胞的参数比RNN细胞多了4组参数,因此LSTM的参数要在RNN参数的基础上乘以4.
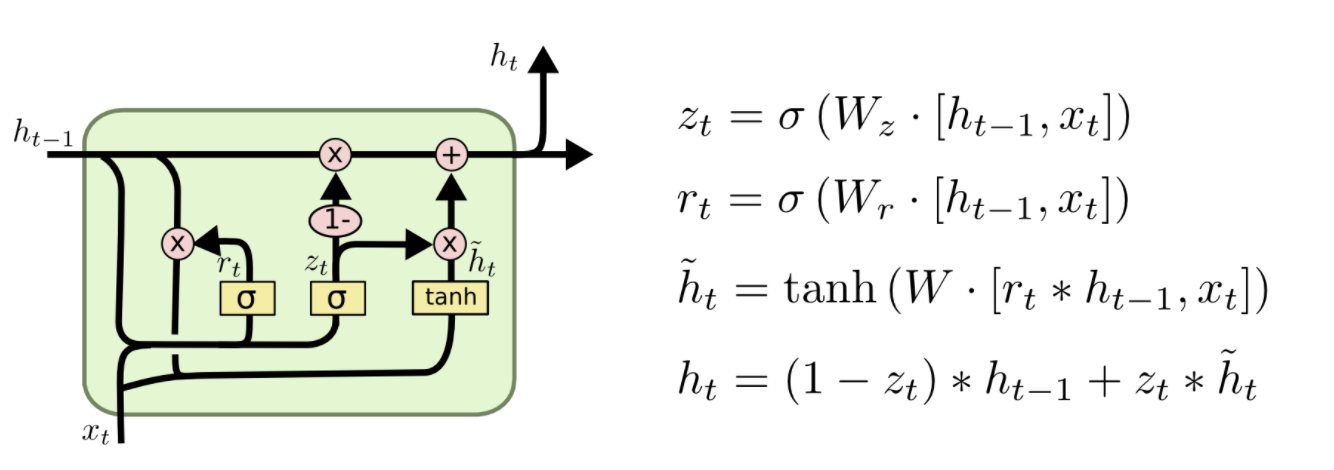
Bi-LSTM
以输入维度为30522,隐藏层维度为768的模型为例,正向96M,反向96M,且隐藏层拼接后全连接输出参数:768*768/2+1
一共为192M个
BERT-LightGBM
LightGBM是一种树模型,采用启发式算法,根据数据的统计信息进行分裂建树,并无可学习的参数。
所以Bert-LightGBM的参数和Bert一致。
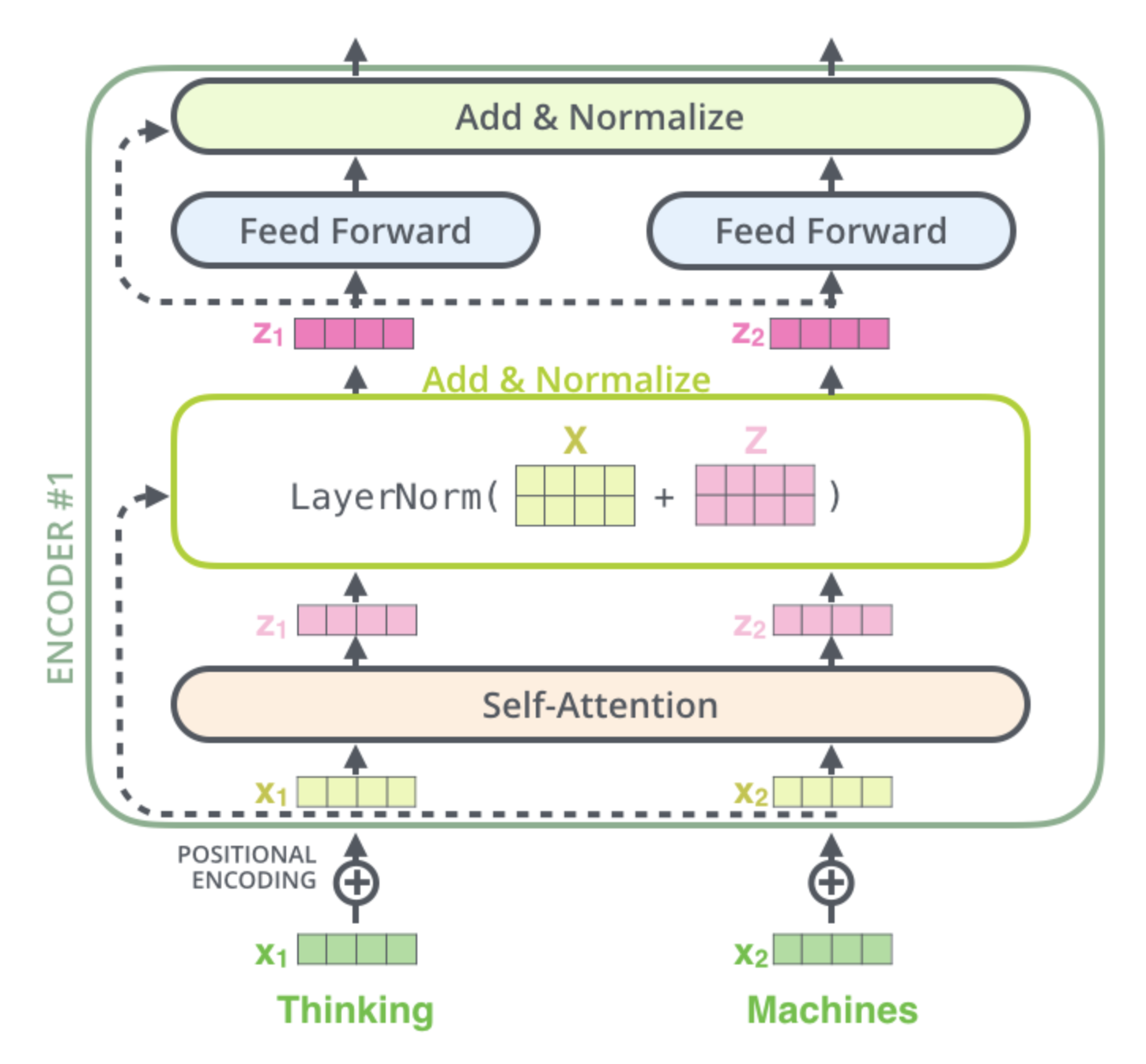
二、Bert编码句子流程
输入表示
对于一个句子,首先对其做分词(可以使用bert自带的tokenizer),得到一个token的list
然后根据vocab将tokens转化为token embeddings向量。
Bert的输入表示由词向量(Token Embeddings)、块向量(Segment Embedding)和位置向量(Position Embedding)之和组成。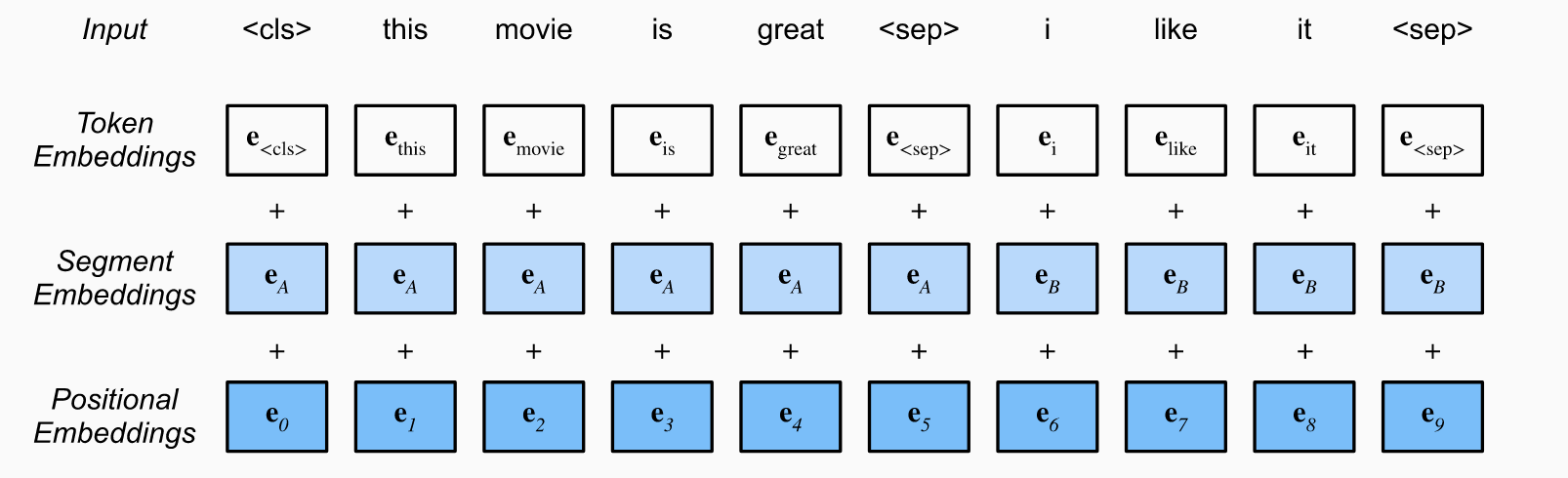
- 词向量:与传统神经网络模型类似,Bert中的词向量是通过词向量矩阵将输入文本转换成实值向量表示。
- 块向量:用来编码当前词属于哪一个块(segment)。当输入序列是单个块时(如单句文本分类),所有词的块编码均为0;当输入序列是两个块时(如句对分类),第一个句子中每个词对应的块编码为0,第二个句子中国呢每个词对应的块编码为1.
- 位置向量:用来编码每个词的绝对位置。由于Transformer结构并未建模词的顺序,因此需要位置编码。google给出的位置编码公式如下:
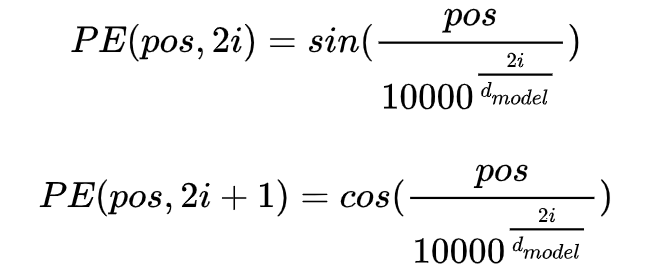 ,其中pos表示单词的位置,i表示单词的维度,d_model=768,如此设计,根据三角函数公式,位置k+p的位置向量可以表示为位置k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
,其中pos表示单词的位置,i表示单词的维度,d_model=768,如此设计,根据三角函数公式,位置k+p的位置向量可以表示为位置k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
Transformer结构
多头注意力
Transformer结构主要包括多头自注意力,Add&Layer Normalize
首先介绍自注意力(self-attention):
在self-attention中,对于输入向量X,其中每个token向量对应3个不同的向量:Query向量(Q ),Key向量(K )和Value向量( V),长度均是64。它们是通输入向量X乘以三个不同的投影矩阵得到的。
接着计算Q和K之间的Score,经过Softmax归一化后对V做加权得到输出。
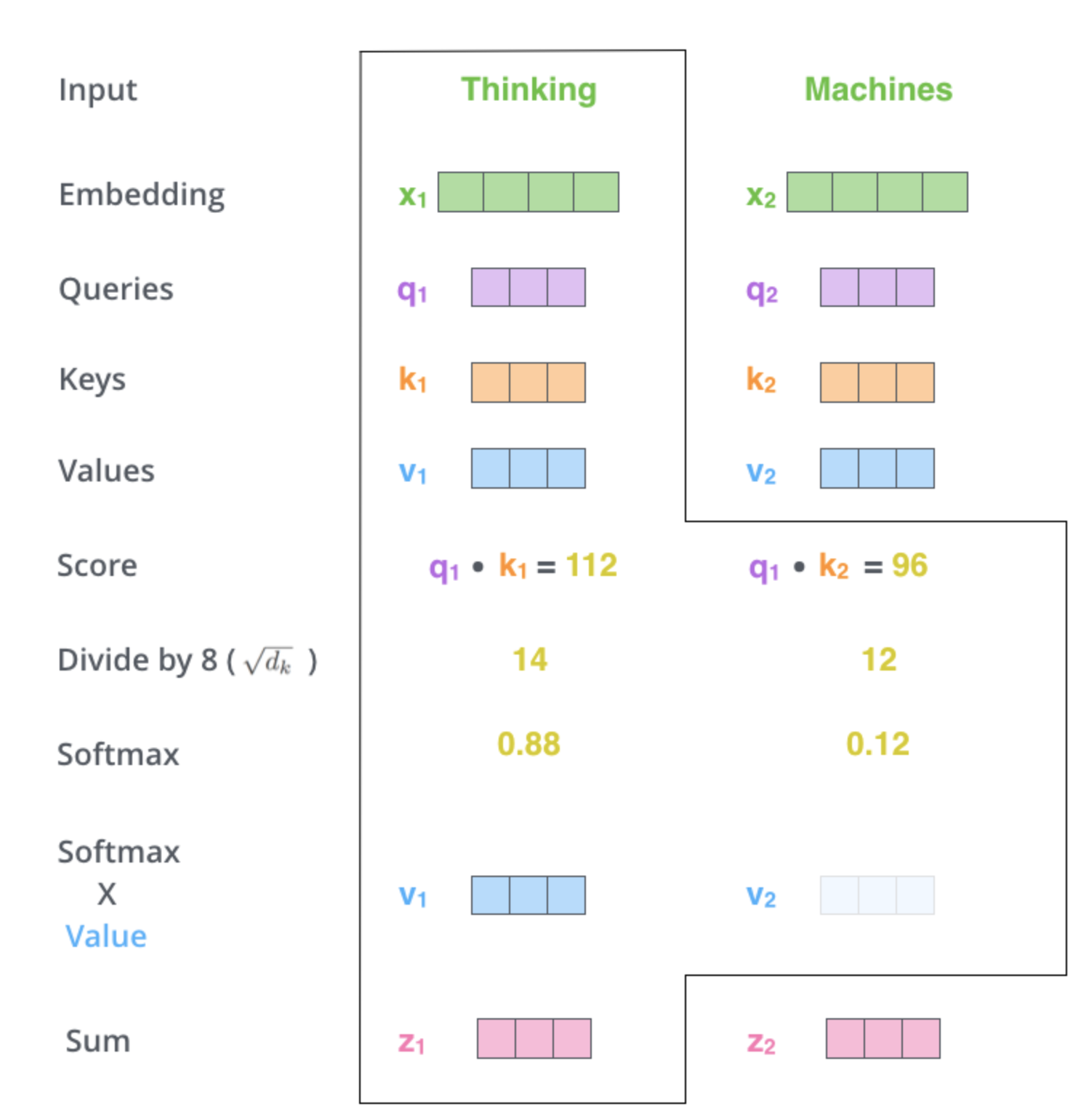

多头注意力模型通过引入多组(原生bert为12组)投影矩阵,分别做自注意力,得到的多组输出拼接在一起,然后通过一个投影矩阵映射到与输入相同的纬度。
为什么要使用多头注意力呢?其实这可以类比CNN中同时使用多个滤波器的作用,直观上讲,多头的注意力形成多个子空间,可以让模型去关注不同方面的信息,有助于网络捕捉到更丰富的特征。
Add&Layer Normal
句子表征
句子输入通过词向量层编码与12层transfomer后,得到了512个768维向量,如何表征句子呢?有以下几种方式
- 取CLS向量(768维)作为句子表征
- 取512个向量的均值作为句子表征
- 取最后两层transfomer的输出的平均值作为句子表征
- ….

若有收获,就点个赞吧
0 人点赞
