1. Bert
1.1 整体结构
随着大数据和高性能硬件的发展,大规模预训练模型已经取得了巨大成功。预训练模型的突出优势在于,能够从海量未标注的数据上学习语言本身的知识,而后在少量带标签的数据上微调,从而使下游任务能够更好地学习到语言本身的特征和特定任务的知识。其中最典型的模型是Devlin等人在2018年提出的基于深层Transformer的预训练语言模型:Bert。Bert不仅充分利用了大规模无标注文本来挖掘其中丰富的语义信息,同时还进一步加深了自然语言处理模型的深度。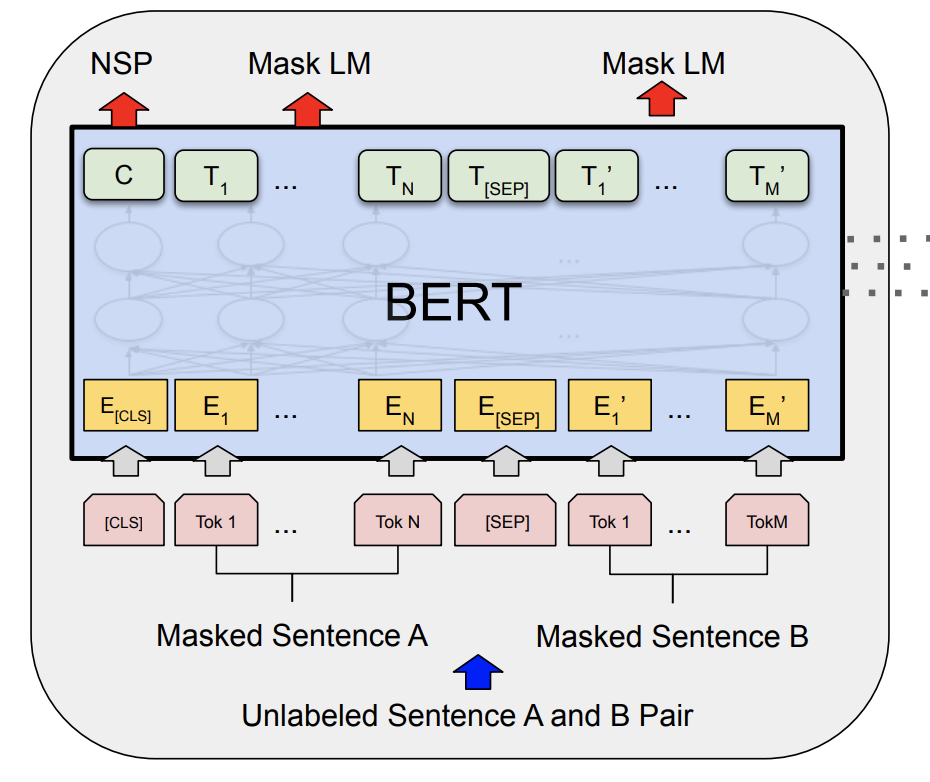
Bert的基本模型结构由多层Transformer构成,包含两个预训练任务:掩码语言模型(Masked Language Model,MLM)和下一个句子预测(Next Sentence Prediction,NSP)。模型的输入由两端文本拼接组成,然后通过Bert建模得到上下文语义表示,最终学习掩码语言模型和下一个句子预测。
1.2 输入表示
Bert的输入表示由词向量(Token Embeddings)、块向量(Segment Embedding)和位置向量(Position Embedding)之和组成。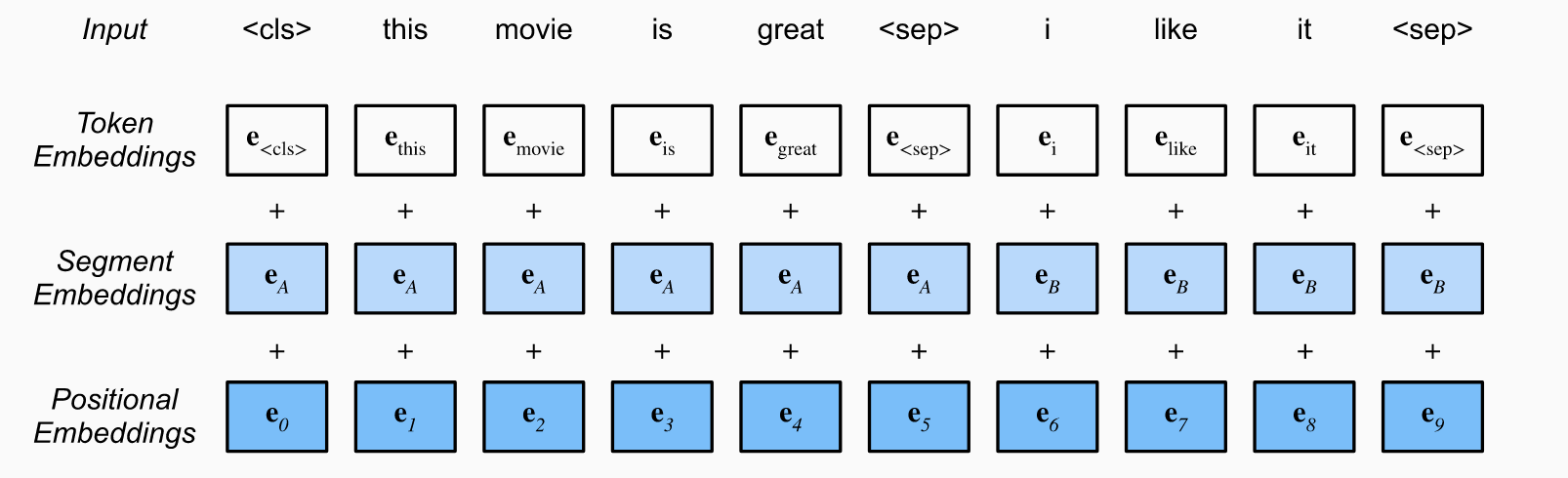
- 词向量:与传统神经网络模型类似,Bert中的词向量是通过词向量矩阵将输入文本转换成实值向量表示.
- 块向量:用来编码当前词属于哪一个块(segment)。当输入序列是单个块时(如单句文本分类),所有词的块编码均为0;当输入序列是两个块时(如句对分类),第一个句子中每个词对应的块编码为0,第二个句子中的每个词对应的块编码为1.
位置向量:用来编码每个词的绝对位置。由于Transformer结构并未建模词的顺序,因此需要位置编码。google给出的位置编码公式如下:
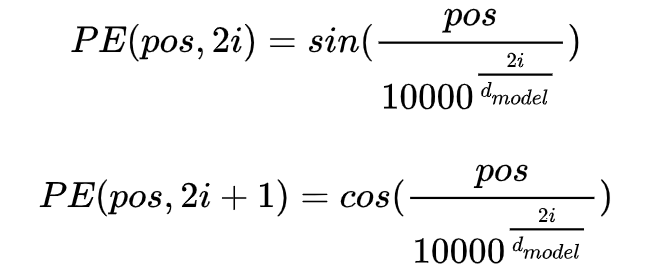 ,其中pos表示单词的位置,i表示单词的维度,d_model=768,如此设计,根据三角函数公式,位置k+p的位置向量可以表示为位置k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利.
,其中pos表示单词的位置,i表示单词的维度,d_model=768,如此设计,根据三角函数公式,位置k+p的位置向量可以表示为位置k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利.
2. Bert表征的问题
2.1 Bert的各向异性问题
将句子输入训练好的大型预训练模型,取[CLS]或对句子序列做MeanPooling可以获得表征句子语义的特征向量。然而这种方法存在很严重的问题:Anisotropy(各向异性),具体表现为bert学到的句子embedding存在坍塌问题,其在向量空间中呈狭窄的锥形分布,蕴含的信息熵较小,即使是完全不相关的句子,embeddings之间的相似度也很高。从奇异谱的角度看,理想情况下,所有句子的embedding呈球面均匀分布,sentence embedding矩阵的各奇异值相同,而实际上,bert输出的sentence embedding矩阵的奇
异值除了少数几个起主导作用的奇异值外,其它绝大多数接近零,这严重限制了向量的表征能力。2.2 什么是好的表征
如何评价模型对句子表征空间的质量呢,Wang and Isola (2020)提出两个指标:alignment和uniformity

给定正例的分布 ,alignment表示:相似实例的表征是否接近
,alignment表示:相似实例的表征是否接近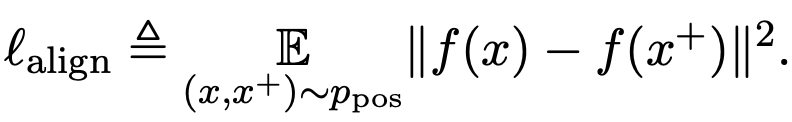
给定数据分布 ,uniformity表示:全体实例的表征是否均匀分布
,uniformity表示:全体实例的表征是否均匀分布
2.3 解决各向异性
目前的解决方法有:
· 线性变换:bert-flow 或 bert-whitening,无论是在bert中增加flow层还是对得到句子向量矩阵进行白化其本质都是通过一个线性变换来缓解Anisotropy。
· 对比学习:通过对比学习的in-batch loss,拉近正样本对的embeddings,同时拉远与负样本的embeddings。在英文STS基准任务上,无监督simcse和有监督simcse均取得了sota表现,胜过包含sbert在内的所有有监督模型。3. SimCSE
3.1 模型简介
无监督SimCSE:将一个句子通过分别两次dropout得到的新句子作为正样本对,取batch内的其他句子对作为负样本。
- 有监督SimCSE:每个句子都对应一个相似句子和一个hard neg句子,在一个batch中,取相似句子作为正样本,取hard neg句子和batch内其它句子作为负样本。

3.2 有监督SimCSE
3.2.1 模型架构
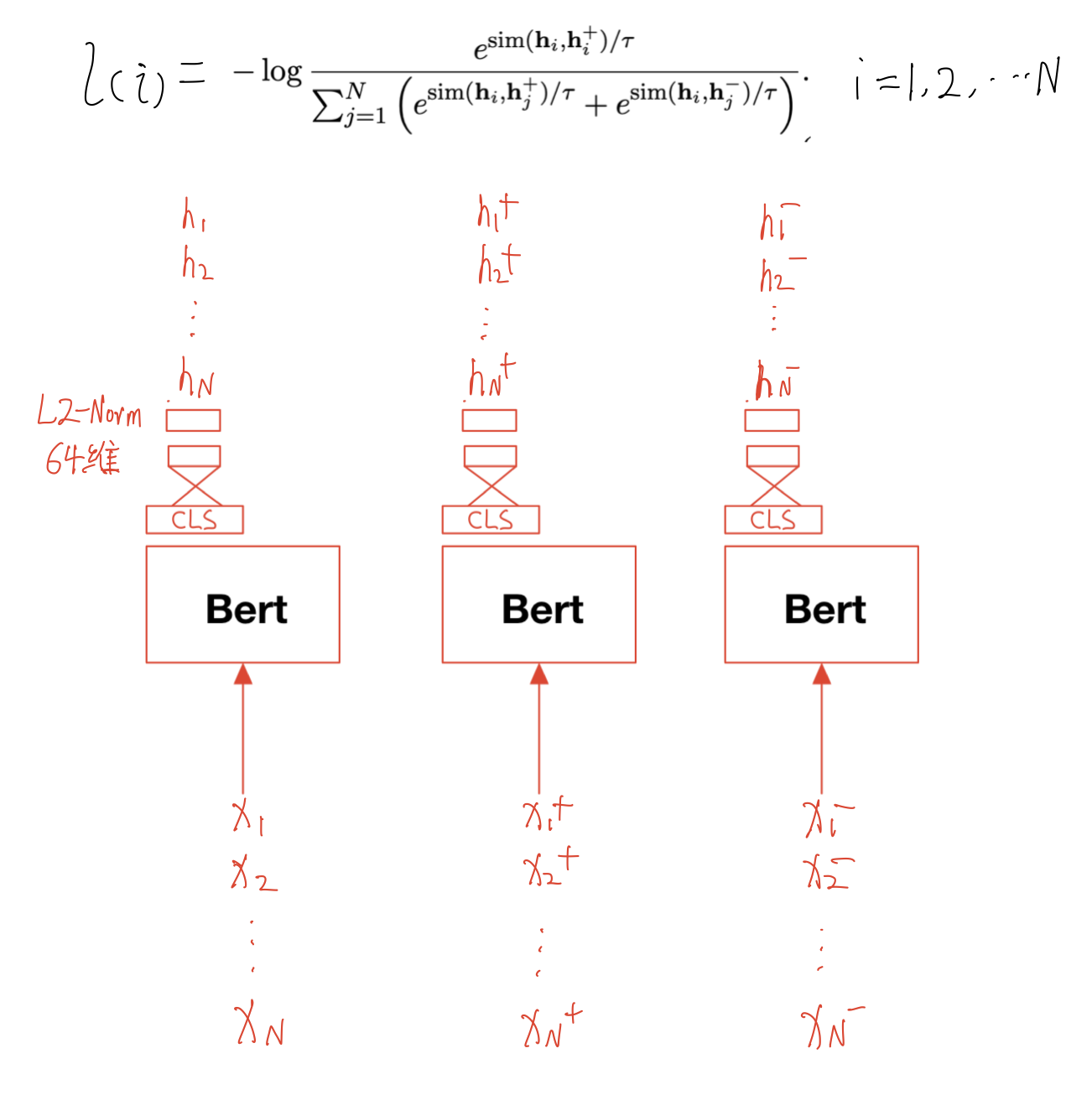
首先对符号做一个声明:
- N:batch size
 :第i个句子
:第i个句子 :第i个句子对应的正例
:第i个句子对应的正例 :第i个句子对应的hard负例
:第i个句子对应的hard负例 :第i个句子及其正负例对应的embeddings
:第i个句子及其正负例对应的embeddings :温度超参,一般设置为0.01-0.1之间
:温度超参,一般设置为0.01-0.1之间 函数:点积
函数:点积
forward流程:
- 喂模型一个大小N的batch,句子三元组(
 )分别输入Bert(共享参数),取CLS层作为输出
)分别输入Bert(共享参数),取CLS层作为输出 - 通过全连接(共享参数)投影至64维向量
- 向量经L2-Norm得到句子表征
3.2.2 模型原理
simcse是如何同时关注alignment和uniformity的呢?这得益于它的损失函数:
在一个容量为N的batch内,样本i处的损失函数定义为:
其中:
· 分子部分体现了alignment:因为它期望正例在表征空间越近越好
· 分母部分体现了uniformity:通过强迫样本和众多负例在向量球面相互推开,以实现分布的均匀性,避免空间坍塌
下面从奇异谱角度证明对比学习的uniformity能力:
首先将损失函数写成一般形式: ,第一项即原分子部分,第二项是原分母部分。
,第一项即原分子部分,第二项是原分母部分。
若 在有限样本{
在有限样本{ }上均匀分布,又由Jensen不等式:
}上均匀分布,又由Jensen不等式:
记W为句子embeddings矩阵,W的第i行即为 ,
,
由于 是L2-Norm处理后的向量,所以
是L2-Norm处理后的向量,所以 ,根据Merikoski (1984),若
,根据Merikoski (1984),若 的所有元素都是正值(实际实验中句子对之间的相似度大部分为正值),那么
的所有元素都是正值(实际实验中句子对之间的相似度大部分为正值),那么 是
是 的最大特征值的上限。
的最大特征值的上限。
所以在最小化uniformity相关的Loss时,句子向量空间的最大奇异值的上限降低,奇异谱逐渐平滑,从而缓解空间坍塌问题。
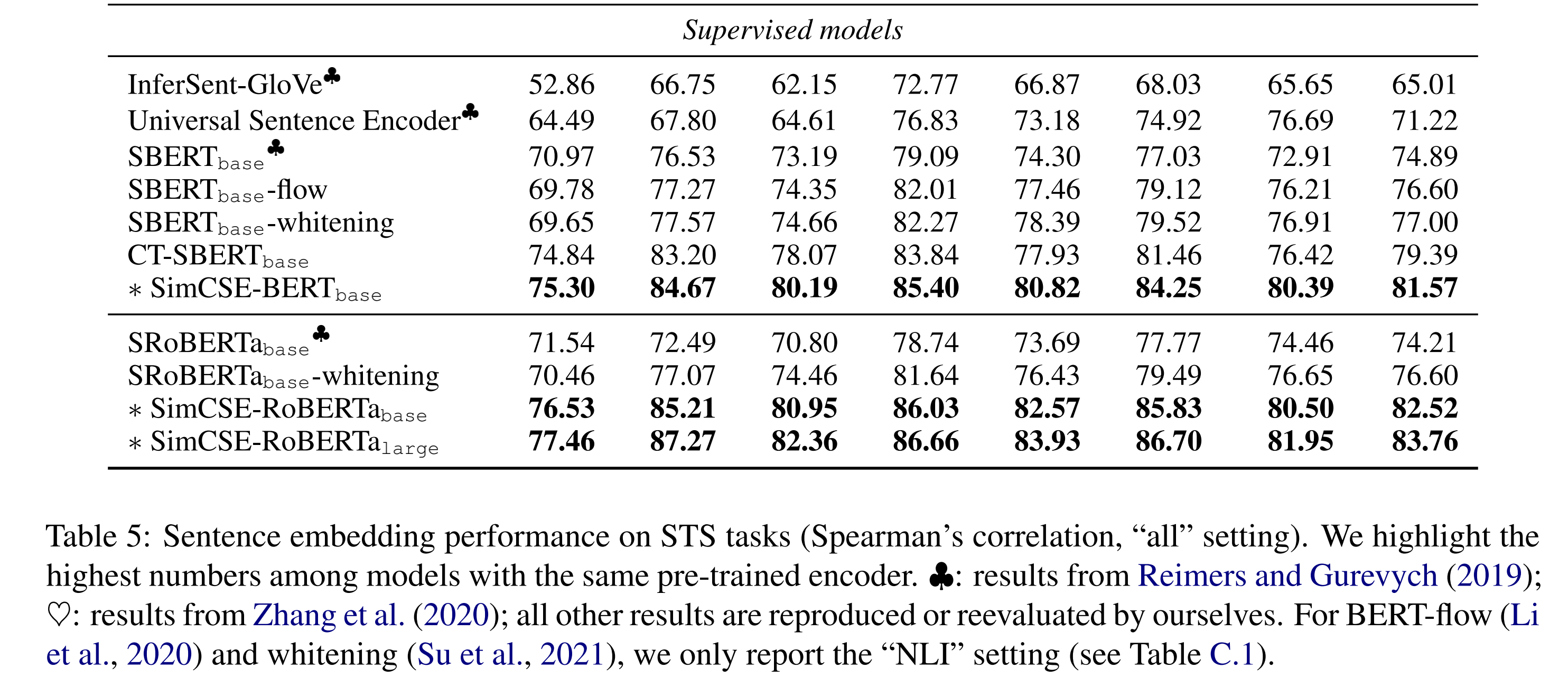
3.3 实验结果

- 从上图中可以看出直接通过BERT模型来做无监督语义相似度效果会比较差,主要原因是任意两个句子的BERT句向量相似度比较高,BERT句向量并没有均匀的分布在向量空间中,对应的信息熵也比较低。
- 针对这个问题,BERT-flow通过normalizing flow把向量分布映射到规整的高斯分布中,有效的提升了uniformity。BERT-whitening对向量分布进行了PCA降维消除了冗余信息,进一步提升了uniformity,但是alignment有一定降低。
- 而SimCSE则提出了一种更高效的方案,使得alignment保持在较好效果上还能大幅度提升uniformity,达到了当前的SOTA效果
具体指标:

若有收获,就点个赞吧
0 人点赞
