K 2021.2.13
0109转录组-1.功能数据库
02:30 转录组分析-Day5——功能分析
基因的功能实际上是基因产物的功能
05:33 GO数据库(重点掌握)Gene Ontology
问题一:一个基因多种功能 TP53
问题二:生物学功能的多种描述
为什么要建立GO
各种水平解决生物学定义混乱的现象,不同生物数据库使用统一的标准语义库
对基因和蛋白质功能从多方面进行限定和描述,并能随研究不断深入更新的语义词汇标准,即基因产物分类标准
GO数据库不是以其自身为中心而是依靠外部数据库,这些外部数据库中收录的基因及其产物都将用GO定义的词汇进行注释。因此GO是与时俱进与相互合作的代表,它致力于统一基因及其产物注释的方式。
本体论:
MF:做什么,描述在个体分子生物学上的活性,如催化活性或结合活性。BP:由分子功能有序地组成的,具有多个步骤的个过程,如细胞周期。CC:指基因产物位于何种细胞器或基因产物组中(如糙面内质网,核糖体,蛋白酶体等),即基因产物在什么地方起作用,(亚细胞定位)
Terms(names for concepts、definitions)注释系统中毎一个结点(term)都是基因或蛋白功能的一种命名及描述
term对应id:”GO:xxxxx”
同义词描述
16:39 GO的结构:语义关系图
有向图:从叶子节点—>根节点
关系:
is_apart_ofregulates
没有闭环
19:51 GO term之间的关系
is_a:具有传递性 is a·is a → is a
part_of:具有传递性 part_of·part_of → part_of
part_of·is a/is a·part_of → part_of
调节控制关系及其推导:
被调节的对象可以是一个过程,如生物通路、酶促反应等,也可以是一个参数值,如细胞大小,pH值等。调节控制关系为充分非必要
regulates:
Regulates·isa → regulates、isa· regulates → regulates以及 regulates· part of → regulates
节点关系并非全部来自实验验证,大量来自计算机预测
IDA注释表明该节点经过实验验证
27:45 KEGG数据库
KEGG, Kyoto Encyclopedia of genes and Genomes
KEGG是系统地分析基因功能、链接基因组信息和功能信息的数据库,旨在揭示生命现象的遗传与化学蓝图。
来源:学术论文+生物学实验,可靠性高
最大特点:包含18个子数据库,应用最多:KEGG PATHWAY数据库
四个类别:系统信息、基因组信息,化学信息和健康信息

KEGG特点
强大的图形功能
37:15 kegg中符号的含义
kegg通路本质是一副线框图,即由点和线构成的基因-代谢物关系图。
两大元素:箭头和节点
点代表通路图中的节点,主要由基因、代谢物和上下游隔壁通路构成。对应三种不同的形状的符号(长方形、圆点和钝角长方形)。<br />线代表通路中分子的互作关系,主要由几类箭头构成。
三类关系:就是点和线构成的分子间的关系类型。
关系类型可以分为
• 蛋白-蛋白互作关系
• 基因表达关系
• 酶-酶关系
43:25 KEGG Identifier
KEGG PATHWAY数据库
特征:prefix + 5个数字
map:通用通路ID,适用于所有物种hsa:物种为人的通路IDko:对于每个功能已知的基因,会把和其同源的基因所有基因都归为一类,就是每一个KO, 并赋予一个K number,用该基因的功能作为这个KO的功能
物种特异性通路:绿色的框框表示专属于这个物种
0109转录组-2功能主释和富集
功能注释
基因表达谱
DEA cut-off
查询感兴趣的基因/基因集合参与哪些可能的生命过程,起到了什么作用

例子1:查看单个疾病风险基因注释到哪些通路
1956 blue
例子2:查看多个疾病风险基因注释到哪些通路(适用于复杂疾病) 列表
19 red368 red
多基因列表存放在 /code-down/data/DEG_limma_voom_all-2.txt
23:25 功能富集分析的原因
直接注释的结果得到大量的功能结点
功能具有概念上的交叠现象
富集分析方法通常是 分析一组基因在某个功能结点上是否过出现(overpresentation)。
显著注释的功能节点:强调统计学上的显著性
功能富集分析的统计方法
- 超几何分布及累积超几何分布 Y叔 cluster-profile R包
- 二项分布及累积二项分布
- 卡方检验或Fisher精确检验
- …
功能富集分析-结果可视化
barplotdotplot
由于KEGG数据库只存储了约8k的基因集,在取交集时差异基因与背景基因会减少
genea/genep 为一常数
enrich_factor值越大,注释到通路的基因越多
0109转录组-GSEA&GSVA
如果没有筛选到差异表达基因怎么办?
GSEA原理介绍
解释全基因组的表达谱
预先定义的基因集 一致性的差异
预先定义的基因集:一个基因集合,包含的感兴趣的基因两个生物学状态:即实验组和对照组,可以是癌症和正常,男和女一致性差异:某个通 路/GO条目中的基因集在实验组和对照组中呈现出一 致的上调或者下调趋势
04:00 GSEA步骤
- 所有基因的表达谱,样品分为两类,以1/2定义
- 基因按照表达与分类的相关性排序
- 计算富集打分(ES)忽略
- 评估ES的显著性(p值)
- 多重检验校正(FDR值)
08:52 GSEA预定义基因集合MSigDB
从位置,功能,代谢途径,靶标结合等多种角度出发,构建出了许多的基因集合,并将其保存在MSigDB
关注C2:包含了已知数据库,文献和专家支持的基因集信息,包含5529 gene sets
13:48 GSEA实例数据
非必须:Gene sets和Chip annotations
Expression dataset file gct文件——.gctPhenotype labels file cls文件——.clsGene sets file gmt文件 ——.gmt 列不相等
GSEA软件使用
高级参数:针对芯片数据,选择策略
可存储为svg矢量图
结果解读
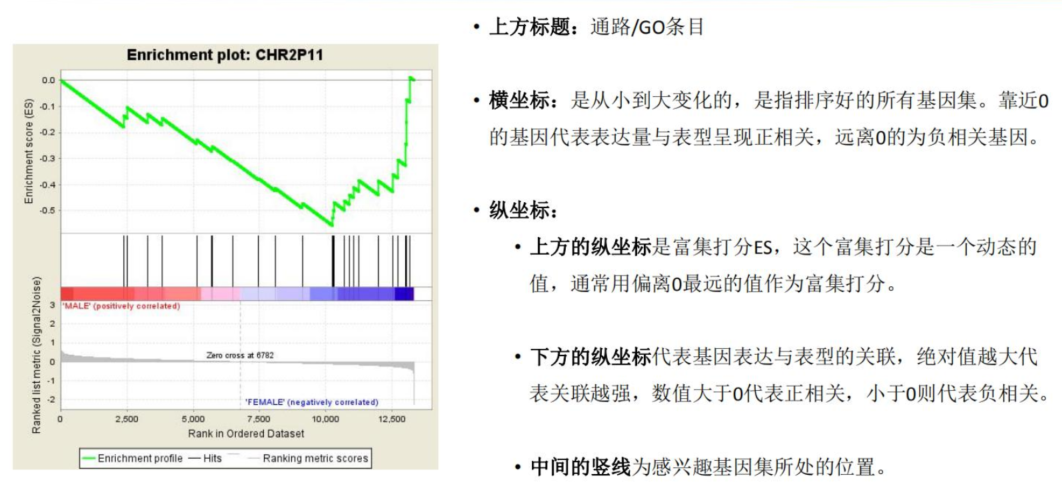
最重要:中间的竖线为感兴趣基因集所处的位置
size:通路所包含基因数(过滤掉表达谱中未出现的基因)
ES:打分
代码分析版本:依赖于R包 GSEABase,优点是比较灵活
通过enrichplot实现可视化
山峦图
参考:《R进行基因富集分析——clusterProfiler系列分析GSEA》
基因集变异分析(Gene Set Variation Analysis,GSVA),一种以非监督方式对一个简单群体评估通路活性变异的GSE方法
49:20 转录组分析—总结


若有收获,就点个赞吧
0 人点赞
