连接池
概述
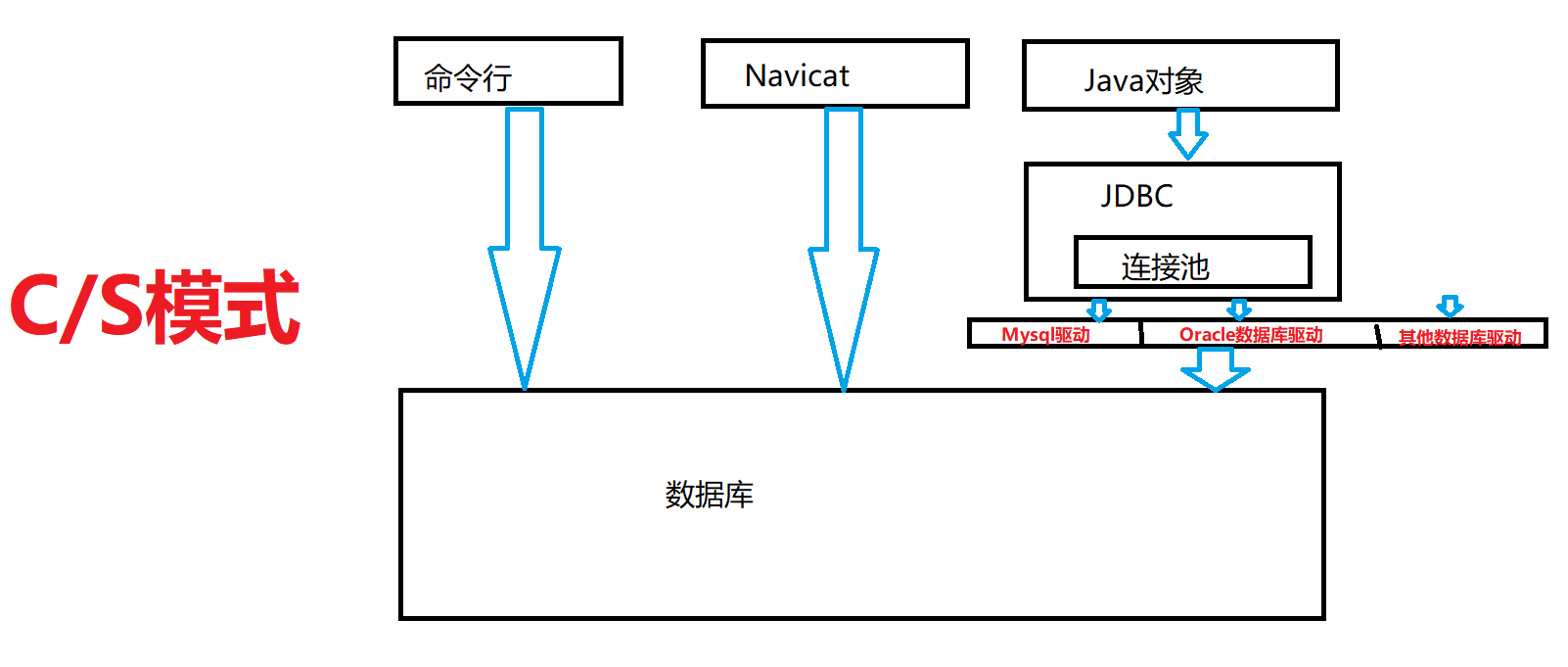
数据库连接池主要就是在JDBC编程的第一个和最后一个步骤,即开关数据库连接。由于每次使用完数据库连接之后都要关闭连接,而再使用时需要创建连接,假如频繁地使用数据库连接,那么就会造成资源的浪费。于是,数据库连接池应运而生。数据库连接池就是将连接使用完之后,将连接放入资源池中,下次使用的时候直接从池中拿取即可。所有的池化技术,都是为了节约资源。
简单使用
以下使用伪代码,来简述连接池的使用:
// 是我自己的一个连接池对象// 头进尾出public class MyConnectionPool {static LinkedList<Connection> connectionPool;// 对这个连接池进行初始化static {addCapacity(10);}// 扩容的方法public static void addCapacity(Integer num) {if (connectionPool == null) {// 底层数据结构是链表connectionPool = new LinkedList<Connection>();}// 给数据库连接池里面放连接for (int i = 0; i < num; i++) {connectionPool.addFirst(JDBCUtils.getConnection());}}// 获取连接public Connection getConnection(){if (connectionPool.size() < 5) {addCapacity(10);}Connection connection = connectionPool.removeLast();return connection;}// 释放连接public void releaseConnection(Connection connection){connectionPool.addFirst(connection);}}
使用
@Testpublic void testSelectUserById() throws SQLException {// 获取数据库连接池MyConnectionPool myConnectionPool = new MyConnectionPool();// 通过这个连接池获取连接Connection connection = myConnectionPool.getConnection();// 我们去操作数据库PreparedStatement preparedStatement = connection.prepareStatement("select * from user where id = ?");preparedStatement.setInt(1,9992333);ResultSet resultSet = preparedStatement.executeQuery();User user = new User();if (resultSet.next()) {user.setId(resultSet.getInt("id"));user.setUsername(resultSet.getString("username"));user.setPassword(resultSet.getString("password"));user.setAge(resultSet.getInt("age"));}System.out.println("user:" + user);// 释放资源JDBCUtils.closeSource( null, preparedStatement,resultSet);// 放回连接myConnectionPool.releaseConnection(connection);}
分类
我们自己写的数据库连接池有诸多局限,比如不够灵活、功能过于简单。于是我们可以借助第三方数据库连接池去完成这个功能。常见的数据库连接池包括DBCP、C3P0、Druid,这些数据库连接池也可叫做数据源DataSource,数据源头。实现方式大同小异。
使用这些数据源的步骤通常是:
- 导入jar包
- 写一个工具类
- 使用
DBUtils
其实连接池主要就是解决与数据库连接相关的问题而做的一个优化。而对于sql语句执行方面做的优化,就是DBUtils接口,这个接口包含DBUtils类、QueryRunner接口和ResultSetHandler接口。顾名思义,DBUtils类就是对于一些资源的整合,比如如何开关、什么时候开关等;而QueryRunner接口就是告知如何查询、以什么方式接受从数据库传来的数据,Map还是List,集合还是值;ResultSetHandler接口就是对查询结果做进一步处理。数据库索引
简述
数据库索引就是定义数据库应该采用什么数据结构去存储数据。根据数据结构的特性,有二叉树、红黑树、哈希表、B树、B+树几种数据结构作为候选。对于相同数量的数据而言,二叉树和红黑树都是因为树太深的缘故,导致查询十分缓慢;而哈希表的查询和修改数据效率挺好的,但是它不能进行范围查询,比如要查找比特定数据大的数据,就显得很麻烦;B+树是在B树的基础上,克服了不能范围查找的缺点,这是因为B+树的叶子节点冗余了父节点的数据,因此某个特定数据的指针就是直接指向其后继节点,或者说是比它大的数据。数据库组成结构
数据库是由连接器、优化器、执行器和数据库引擎等组成的。连接器是通过JDBC传来的数据库驱动名、用户名、密码架起Java数据库之间的连接;优化器就是根据sql语句的不同,选择什么样的数据库引擎应对;执行器就是实现了数据库引擎提供的接口执行sql语句;数据库引擎就是数据库索引结构。
数据库引擎分为InnoDB和MYISUM,InnoDB是一种聚集索引,这是指B+树的叶子节点不仅存储数据,还存储表索引,即其他数据;而MyISUM是一种非聚集索引,是指B+树的叶子节点只存储数据和维护一个指针,这个指针指向另一个文件的地址,这个文件存储了表的其他数据。简言之,就是InnoDB将数据和索引放一起存储,MyISUM将数据和索引分开存储。除此之外,InnoDB和MyISUM的区别还有:InnoDB的文件为frm和idb,而MyISUM的文件为frm、MYI、MYD;InnoDB支持数据库事务,而MyISUM不支持事务;InnoDB支持行锁、表锁和外键,MyISUM支持表锁、不支持行锁和外键。
一般来讲,数据库索引不只有单索引,还有联合索引,联合索引是为了防止回表,即一条sql先查了某个非索引字段,后面又查询了主键索引字段,就导致查询了重复的字段,拖累查询效率。一般来讲,联合索引的数量最好不要超过3个,即便所有字段都设置了索引,但是如果要修改数据,就意味着每个索引字段都会发生改变,非常不利,当然也是根据业务需求选择合适数量的索引。索引失效的情况
回表是一种不好的现象,有很多情况都会导致回表,具体来讲有以下情况:

若有收获,就点个赞吧
0 人点赞
