Prometheus主要两个组件,prometheus server和alertmanager
一、准备工作
./prometheus —version
prometheus, version 2.25.2 (branch: HEAD, revision: bda05a23ada314a0b9806a362da39b7a1a4e04c3) build user: root@de38ec01ef10 build date: 20210316-18:07:52 go version: go1.15.10 platform: linux/amd64
安装包github自行下载即可
二、Prometheus server 部署
1.prometheus server的supervisor配置文件
[program:prometheus]command=/data/server/prometheus/prometheus --config.file=/data/server/prometheus/prometheus.yml --storage.tsdb.path=/data/prometheus_data --web.listen-address="0.0.0.0:9090" --storage.tsdb.min-block-duration=2h --storage.tsdb.max-block-duration=2h --storage.tsdb.retention.time=7d --web.enable-lifecycleuser=rootstderr_logfile = /var/log/supervisor/prometheus_err.logstdout_logfile = /var/log/supervisor/prometheus_stdout.logdirectory = /data/server/prometheusautostart=trueautorestart=truestartsecs=5
2.prometheus server配置文件
vim prometheus.yml
global:external_labels: #打一个额外的labelscrapeReplica: 2scrape_interval: 1s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 1s # Evaluate rules every 15 seconds. The default is every 1 minute.alerting:alertmanagers:- static_configs:- targets: ['localhost:9093'] #填写alertmanager的IP和端口rule_files:- "/data/server/prometheus-2.25.2.linux-amd64/rules/alert.yml" #填写报警规则,触发后发给alertmanagerscrape_configs:- job_name: 'prometheus'static_configs:- targets: ['localhost:9090'] #静态配置,此处为收集本机prometheus的指标- job_name: 'web'consul_sd_configs: #基于consul的服务发现- server: '192.168.13.29:8500' #consul节点的机器和端口services: ["web"] #需要监听的consul的哪个services- job_name: 'NodeExporter'static_configs:- targets: ['localhost:9100']
3.rule_files文件配置
此处示例一个简单的内存报警配置规则
groups:- name: node_healthrules:- alert: HighMemoryUsage #报警名字expr: node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes < 0.9 #什么情况下会报警for: 1m #持续一分钟后才会触发报警labels:severity: warning #自定义报警级别annotations:summary: High memory usage #自己写报警信息
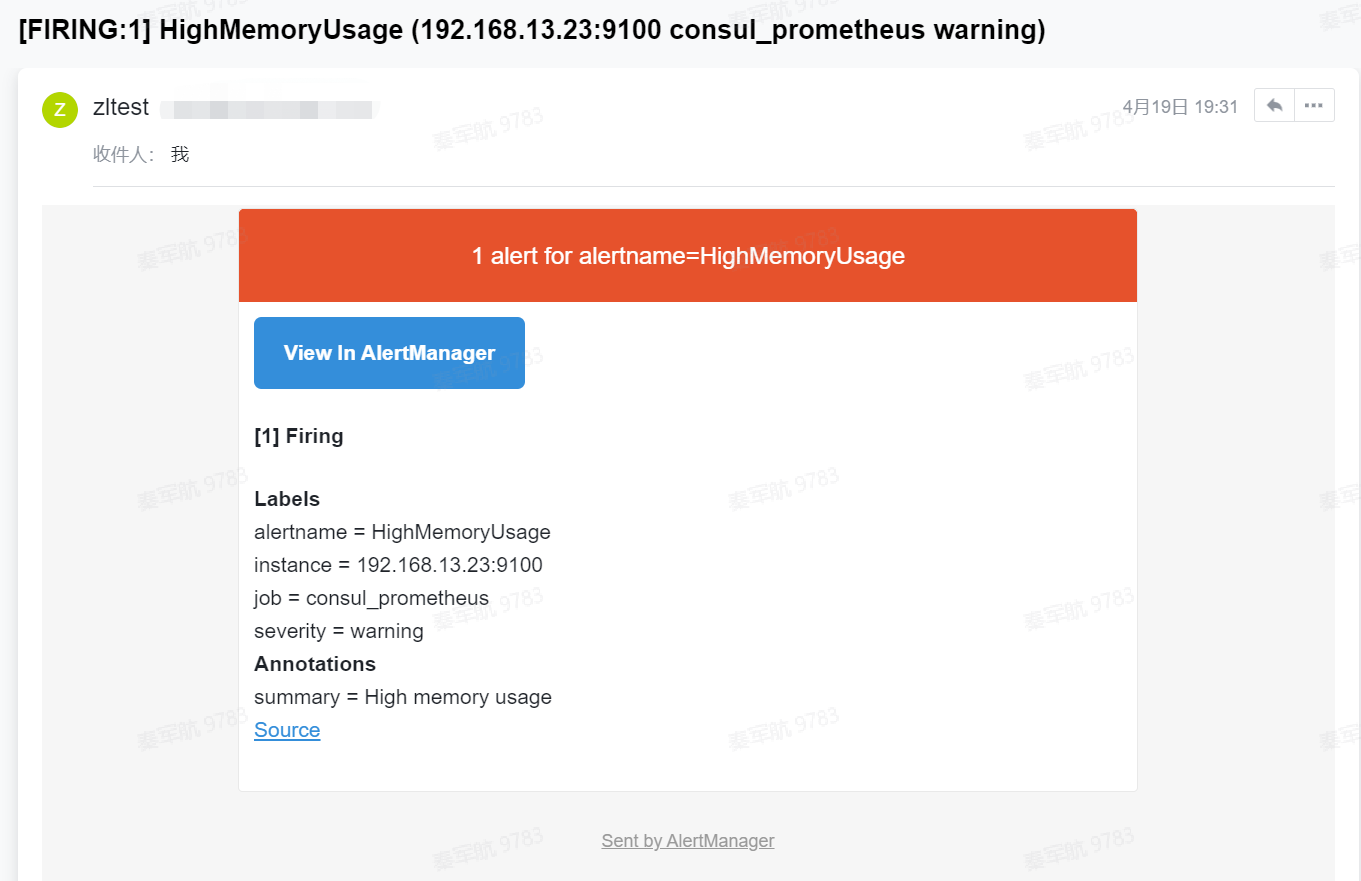
出发报警后的发送的邮件信息
三、alertmanager报警
1.alertmanager以supervisor启动
[program:alertmanager]command=/data/server/alertmanager/alertmanager --config.file=/data/server/alertmanager/alertmanager.ymluser=rootstderr_logfile = /var/log/supervisor/alertmanager_err.logstdout_logfile = /var/log/supervisor/alertmanager_stdout.logdirectory = /data/server/alertmanagerautostart=trueautorestart=truestartsecs=5
2.alertmanager配置文件
vim alertmanager.yml
global:resolve_timeout: 5m #在配置的超时时间内没有收到上次告警就会发出恢复邮件,恢复也是按分组发出; 分组会包涵恢复和告警信息smtp_smarthost: 'smtp.feishu.cn:465'smtp_from: 'zltest@xiaoniangao.com' #用这个邮箱去发送报警信息smtp_auth_username: 'zltest@xiaoniangao.com'smtp_auth_password: 'xxxxxxxxxxxx'smtp_require_tls: falseroute:group_by: ['alertname', 'cluster', 'service'] #满足group_by中定义的标签,那么这些报警将会合并为一个报警通知发送给receivergroup_wait: 10s #为了一次收集更多的信息,如果在等待的时间内收到了新的报警,这些报警会合并成一个通知发送给receivergroup_interval: 10s #定义相同group之间发送告警的时间间隔repeat_interval: 5m #报警周期,发送一次报警后,下次5分钟后再发送一次报警receiver: 'mail' #报警发送使用mail这个规则receivers:- name: 'mail'email_configs:- to: 'qinjunhang@xiaoniangao.com' #报警接收人邮箱
至此prometheus的组件已经部署完成,但是怎么去收集监控数据呢,此时需要一个exporter去收集机器上的信息(就类比zabbix上的一个脚本,去采集机器指标),下面来部署一个主机监控的exporter
四、NodeExporter部署
1.NodeExporter以supervisor启动
[program:node-exporter]command=/data/server/node_exporter/node_exporter--web.disable-exporter-metrics--collector.processes--collector.filesystem.ignored-mount-points='^/(dev|run|proc|sys|var/lib/docker/.+)($|/)'stderr_logfile = /var/log/supervisor/node-exporter_err.logstdout_logfile = /var/log/supervisor/node-exporter_stdout.logdirectory = /data/server/node_exporteruser=rootautostart=trueautorestart=truestartsecs=5

若有收获,就点个赞吧
0 人点赞
