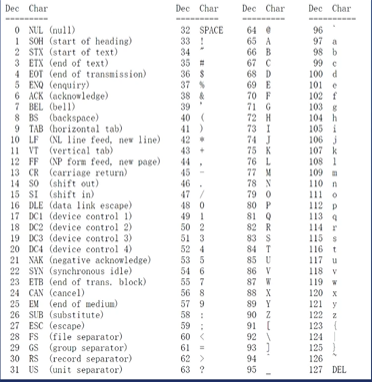
1.最开始使用7位二进制数就可以储存127个所有符号,后来的编码方法都兼容这些字符。
- 48(0)~57表示数字
- 65(A)~90表示大写字母
- 97(a)~122表示小写字母
2.中文加入,使用四个16进制数进行中文编码(GB2312),即16位,2个字节,最多可以收录65536个字符,但是只收录了6000多个汉字(常用),日文等。为了收录更多的中日韩等字符,微软规定了GBK(国标扩),含21886个汉字和图形符号,完全兼容GB2312。
3.后来,更多的文字加入,对字符编码提出了更高的需求,提出了万国码(Unicode),希望对所有文字进行编码,万国码已经收录了超过13万个字符,2个字节已经不够储存的需求,因此使用Unicode进行编码,会导致存储量的增大。
4.为了降低Unicode的存储量,提出了UTF-8(最少可以使用8 位存储)。对前128个字符使用8位存储,汉字使用3字节进行存储,并在存储中提示分节信息(不然不知道哪个是中文哪个是字母),这样可以有效减小无效的存储(前128个字符也要用三字节)。

若有收获,就点个赞吧
0 人点赞
