title: 深入理解Apache NIFI Connection
date: 2020-05-21
categories:
- Apache NIFI
tags: - Apache NIFI
author: 张诚
location: BeiJing
publish: true
sticky: 4
简介
NiFi Connection是在两个已连接的NiFi处理器组件之间临时保存FlowFiles的位置。每个包含排队的NiFi FlowFiles的Connection在JVM堆中都会占一些空间。本文将对Connection进行分析,探究NiFi如何管理在该Connection中排队的FlowFiles和Connection对堆和性能的影响。
正文
首先看一下下面这张说明图
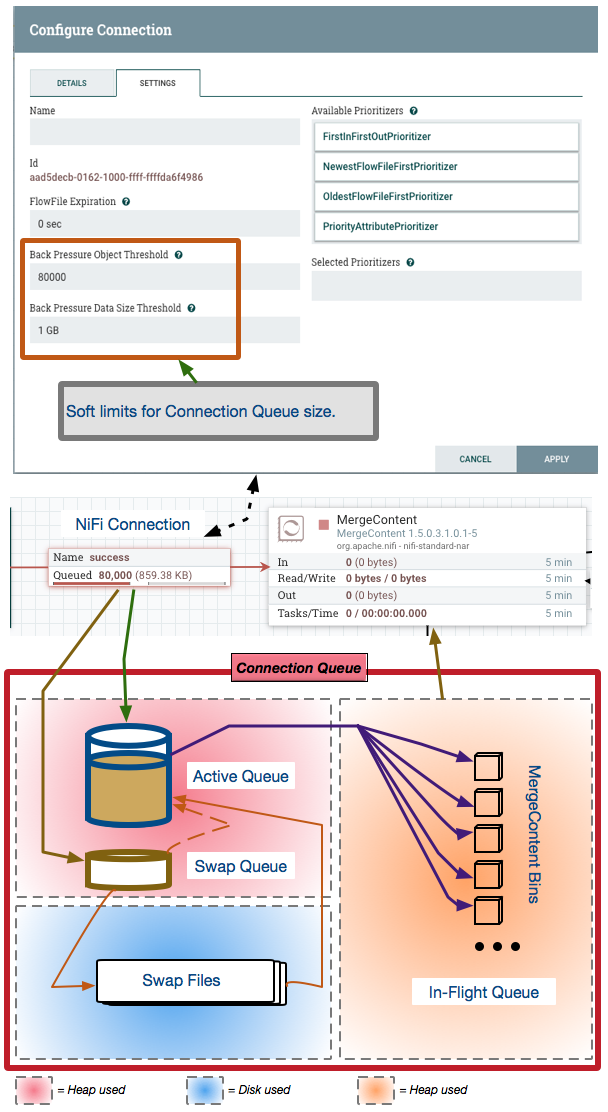
NiFi FlowFiles由FlowFile内容和FlowFile属性/元数据组成。 FlowFile内容永远不会保存在Connection中。Connection仅将FlowFile属性/元数据放置在堆中。
“Connection Queue”
“Connection Queue”保存了Connection中所有排队的FlowFiles的位置。要了解这些排队的FlowFile如何影响性能和堆使用情况,让我们首先关注上图底部的关于”Connection Queue”的剖析。
Connection的整体大小由用户配置的back Pressure Object Threshold和Back Pressure Data Size threshold设置控制。
Back Pressure Object Threshold 和 Back Pressure Data Size Threshold
此处的Back Pressure Object Threshold默认设置为10000。
Back Pressure Data Size Threshold默认为1 GB。
这两个设置都是软限制,这意味着可以超过它们。例如,假设上面的默认设置以及已经包含9500个FlowFiles的连接。由于连接尚未达到或超过对象阈值,因此允许运行该连接的处理器运行。如果此队列上游的处理器在执行时又生成了2000个FlowFiles,则Connection将增长到11500个排队的FlowFiles。然后,直到Connection再次下降到配置的阈值以下,才允许前一个处理器执行。(这就是背压机制)
数据大小阈值也是如此。数据大小基于与每个排队的FlowFile相关联的内容的累积大小。
现在,我们知道如何控制“connection queue”的整体大小,下面将其分解为几个部分:
- ACTIVE QUEUE:FlowFiles进入到一个
Connection中将首先被放置在active队列中。 之后FlowFiles将继续被放入到此active队列,直到该队列达到全局配置的nifi交换阈值为止(swap threshold)。active队列中的所有FlowFiles都保存在堆内存中。从此Connection中使用Flowfile的处理器将始终从active队列中提取FlowFiles。每个连接的活动队列的大小由nifi.properties文件中的以下属性控制
nifi.queue.swap.threshold=20000
交换阈值的增加会增加数据流中每个连接的潜在堆占用空间。
SWAP QUEUE: 根据上述默认设置,一旦
Connection达到20000个FlowFiles,进入连接的新FlowFiles将被放置在swap队列中。swap队列也保存在堆中,并且硬编码为最大10000个FlowFiles。如果活动队列中的空间已释放并且不存在交换文件,则交换队列中的FlowFiles将直接移到活动队列中。SWAP FILES: 每次swap队列达到10000个FlowFiles时,会将包含这些FlowFiles的交换文件写入磁盘上。届时,新的FlowFiles将再次写入交换队列。NIFI可以创建许多交换文件(但设计上建议尽量减少),上面图片的
Connection包含80000个FlowFiles,堆中将有30000个FlowFiles和5个交换文件(active中有两万个,swap中有一万个,剩下的五万在交换文件里)。当活动队列释放10000个FlowFiles,因此最早的交换文件将移至活动队列,直到所有交换文件都消失。交换文件会产生磁盘IO读写,在整个数据流中产生大量交换文件,这一定会影响数据流的吞吐量性能。IN-FLIGHT QUEUE: 与上面的3不同,运行中队列仅在使用此连接的处理器正在运行时才存在。消费处理器将仅从active队列中提取FlowFiles并将它们放置在运行队列中,直到成功处理完并且这些FlowFiles已从消费处理器提交到出站
Connection为止。该运行中队列也保留在堆中。一些处理器一次处理一个FlowFile,另一些处理器处理批量的FlowFile,还有一些处理器可能处理传入连接队列中的每个FlowFile。在最后一种情况下,这可能意味着在处理这些FlowFiles时堆使用率很高。上面的使用MergeContent处理器的示例就可能是最后一种情况,假如MergeContent配置的结果为每次合并90000个FlowFile,那么这80000个FlowFile都会进入到运行队列中。
总结
通过限制连接队列的大小来控制堆的使用(如果可能的话)。 (当然,如果你打算合并40000个FlowFile,则传入连接中必须有40,000个Flowfile。但是,你可以串联使用两个mergeContent处理器,每个处理器合并较小的bundle,并获得相同的最终结果,而总堆使用量较少。)
使用默认的背压对象阈值设置,大多数连接上都不会生成交换文件(记住软限制),这将导致更好的吞吐量性能。
在大多数活动队列大小和性能的情况下,默认配置的交换阈值20000是一个很好的平衡。对于较小的流量,你可以将其推高,对于较大的流量,你可能需要将其设置为较低。只需了解这是为了性能而对堆使用情况进行的权衡。但是,如果你的堆用完了,性能将为零。
额外说一下队列的优先级排序器
优先级排序器仅对active队列中当前的FlowFiles有效。由于此active队列位于JVM堆中,因此基于优先级的重新排序对性能的影响很小。每次新的FlowFile进入连接时,重新评估所有交换的FlowFiles都会影响吞吐量性能。请记住,当在连接上不定义优先级时,将始终获得最佳吞吐量。
公众号
关注公众号 得到第一手文章/文档更新推送。


若有收获,就点个赞吧
0 人点赞
