1.事务:
在Mysql数据库中事务这个概念属于Innodb存储引擎中,事务可以简单的理解为,有一组操作,要么同时成功,要么同时失败。事务有4个特性,分别是 ACID
- A 代表原子性,所谓原子性就是整个事务是不可分割的,再一次执行中要么所有操作都成功,所有操作都失败;
- C 代表一致性,一致性可以理解为体现在原子性中的,举一个转账的例子,转账的这个过程的钱总量应该是不便的,所以我们如果在一个操作中出现了问题,那么如果不进行回滚,钱的总数就会莫名的消失,可以类比能量守恒定律
- I 代表隔离性,在多个并发事务的情况下,事务与事务之间的数据修改不会互相干扰,每个事务都有自己的独立的数据空间
- D 代表持久性,持久性是指一个事务一旦commit 那么表中的数据就会彻底发生改变了,是无法roolback的
2.并发下事务可能出现的问题
- 脏读 脏读是指在并发的事务下,一个事务在为提交事务前对数据的修改的数据,可以被其他的事务读到
- 修改丢失 当2个数组都读取到了一个数据,并且A对数据进行了修改,B也对数据进行修改,那么因为 A B 都拿到了一个数据,如果A 先提交,那么A的结果就会被B给覆盖掉!
- 不可重复读 意思就是一个事务不能够重复的读取到之前的数据,当一个事务对数据修改并提交之后,另一个事务对相同数据进行操作的时候,会发现自己两次读取的数据是不相同的!
- 幻影读 和不可重复读是差不多的,只是它侧重与数据的增添或者减少,可能一个事务执行后新增了几条数据,导致另一个事务在两次查表后发现数据记录的条数不一致
3.事务的隔离级别
为了应对可能出现的事务问题,有事务的4个隔离级别
- 读取未提交,顾名思义,就是脏读产生的原因了,事务之间可以任意的访问对方的暂时修改的数据,可以说是完全没有隔离性
- 读取已提交,在这种隔离级别下,可以避免掉脏读的产生,但是我们仍然不能够进行重复读,因为ABA的这种情况依然是不可避免的
- 可重复读,可以避免了不可重复读,形成了良好的隔离环境,但是缺点在于不能够满足幻影读,但在Mysql的可重复读中,对幻影读做了优化,后面仔细聊
- 可串行化,这是最严格的隔离级别,完全满足 ACID 简单理解就是每一个事务都要排队执行,这样就不会互相干扰,成单线程了;
mysql 中默认的事务隔离级别是可重复读
4.Mysql的可重复读是怎么实现的(MVCC)
回头看吧,全错了;
5.索引
Mysql中底层的索引实现的数据结构是 B+Tree 索引的类型,大致上可以分为2类:1.主键索引 2.辅助索引
索引的这颗B+Tree具备这二叉搜索树的特点,我们可以通过当前树上结点的大小来判定接下来我们要寻找结点的路径,而B+Tree为了能够可以实现范围查找,不在非叶子结点上储存数据结点,即k-v ,把所有的结点存储到叶子结点上,并且把他们做成双向循环链表,这样不仅可以单个查找,也兼顾了范围查找。
而一般来说,主键索引就是以主键来建立了索引,并且这个主键索引最后跟着B+Tree最后走到的位置的K也就是我们的主键,而V则是我们要找的数据记录!
对于辅助索引来说,查找数据记录的方式是一样的,但是我们在查找到辅助索引所设置的K后,其V并不是我们需要的data ,而是存放了我们主键,紧接着辅助索引需要借助主键来再一次通过主键索引来查找我们需要的data;
对于辅助索引,我们往往还采取联合索引,就是说将多个表的字段联合起来建立索引,这时在B+Tree上进行路径判断的时候,遵循最左前缀原则,也就是说,我们先看写在最左边的索引来判断方向,如果说最左边字段的索引是一致的,则会继续向下进行匹配,知道找到最终的路径,或者结点 !
联合索引的生效问题:1,使用联合索引的全部字段 2,使用最左边的字段 3,用or不能生效 4,不用最左边的不能生效
索引的真正面目
以Innodb为例子,索引主要有4种,他们分别是主键索引,单列索引,唯一索引,联合索引
show index from table名称 //查看某一个table中的索引的情况。create index index的名字 on table名(字段A ,字段B);//可以用来创建联合索引,或者唯一索引如果说是创建唯一索引就在index前面加上的unique关键字
主键索引,在Innodb中主键索引其实是默认创建的
单列索引,那就是说我们为某一个字段创建了索引
唯一索引,它的出现是可以允许索引中出现空值,但是只允许有一个。
复合索引,复合索引可以将多个字段联合起来创建索引,在查询索引的时候,要保证最左匹配原则。(有优化)
覆盖索引是指,当我们进行数据查询的时候,一般情况下如果不是主键索引都会走回表操作,所以,当我们进行发现select的字段 和 我们的建立索引上的字段恰好匹配的情况下,那么就不必回表了,直接取索引值就好了。
图解 B+Tree
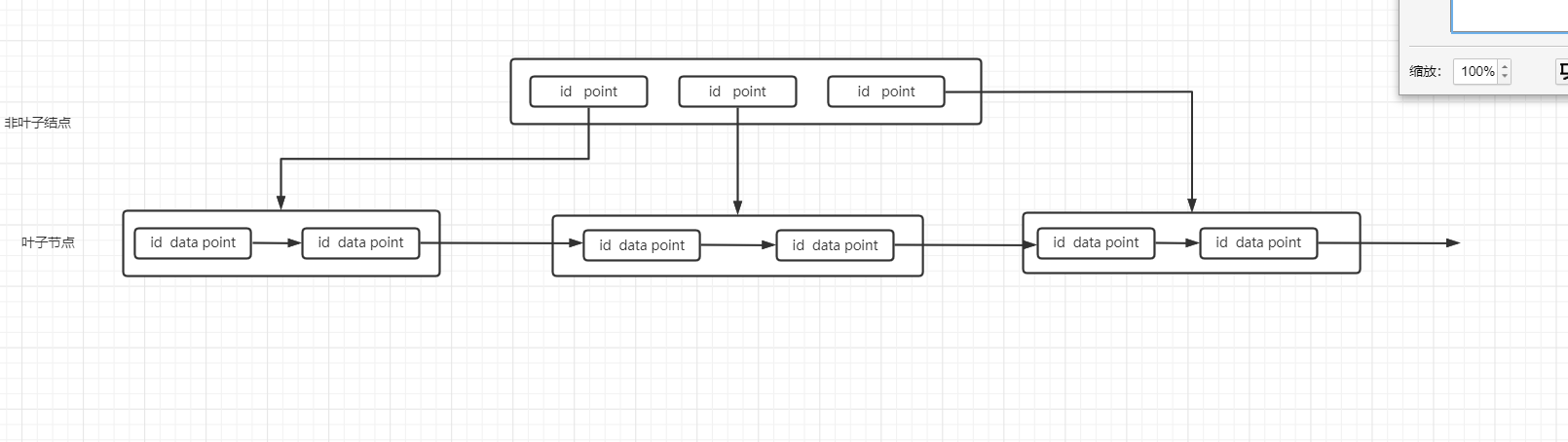 B+Tree的结构简单来说就是一棵叶子节点上布满了数据记录,非叶子结点记录着叶子结点对应着的指针的一课树形结构,每一个页面的默认的大小是16KB ,所以说一般来说 2-3 层就可以存储非常多的数据。
B+Tree的结构简单来说就是一棵叶子节点上布满了数据记录,非叶子结点记录着叶子结点对应着的指针的一课树形结构,每一个页面的默认的大小是16KB ,所以说一般来说 2-3 层就可以存储非常多的数据。
聚簇索引
聚簇索引是Innodb存储引擎的B+Tree的结构,就是把索引和数据记录存储到了同一个文件中,使用主键索引的到达叶子节点后,就可以取到数据记录了,非聚簇索引是说当我们使用非主键索引的时候,查到叶子结点后,得到的并不是数据记录本身,而是一个主键值,这时候需要会到主键索引去二次查询到数据记录。
比如所 Mylsam 就全部是非聚簇索引,因为它的主键索引的最终结果存储的是当前数据记录所在磁盘中的地址。
6.Innodb & Mylsam
7.三范式

若有收获,就点个赞吧
0 人点赞
