Apache 3.0 改进了运行时的内存监控,可以帮助用户解决内存使用问题,并且优化 Spark 作业的内存配置。具体情况请参阅 SPARK-23429 和 SPARK-27189。
内存问题
内存是 Spark 作业性能和稳定性的关键。如果没有为 Spark 作业分配足够的内存,则有可能遇到 OOM 错误或者作业性能大幅度降低。Spark 需要内存来高效执行 Dataframe/RDD 操作,提升算法性能,否则作业在处理过程中必须 shuffle 到磁盘。此外,内存还可以用于缓存数据,减少 I/O。在实践过程中,怎么知道一个作业需要多少内存?
基本方法
为 Spark 作业调整内存大小的一个基本方法就是通过 spark.executor.memory 配置内存资源。在 local 模式下,可以使用 spark.driver.memory 进行配置。通过反复试验,用户可以确认所需内存的大概数值。这种方法不是最佳方案,缺点在于繁琐,且不可靠。
改进方法
用户可以根据监控数据来了解 Spark 应用程序使用了多少内存、哪些作业请求更多内存以及使用哪些内存区域。这种方法有助于深入解决 OOM 问题,也有助于更加精确地为 Spark 应用程序分配内存。
Spark 如何使用内存?
executor 内存配置
spark.executor.memory 是配置 executor 内存的主要参数,通过增加内存开销以覆盖额外内存使用,例如操作系统、冗余计算和文件缓存,计算公式为 。memory-overhead-factor 默认值为 0.1,当 Spark 运行在 Kubernetes 上时,可以通过
spark.kubernetes.memoryOverheadFactor 配置。在使用 PySpark 时,额外内存可以通过 spark.executor.pyspark.memory 配置。堆外内存可以用 spark.memory.offHeap.size=<size> 和 spark.memory.offHeap.enable=true 配置,这样的配置对 YARN 有效。K8s 的配置方式参阅 SPARK-32661。
还有 driver 内存分配参数:spark.driver.memory 、spark.driver.memoryOverhead。
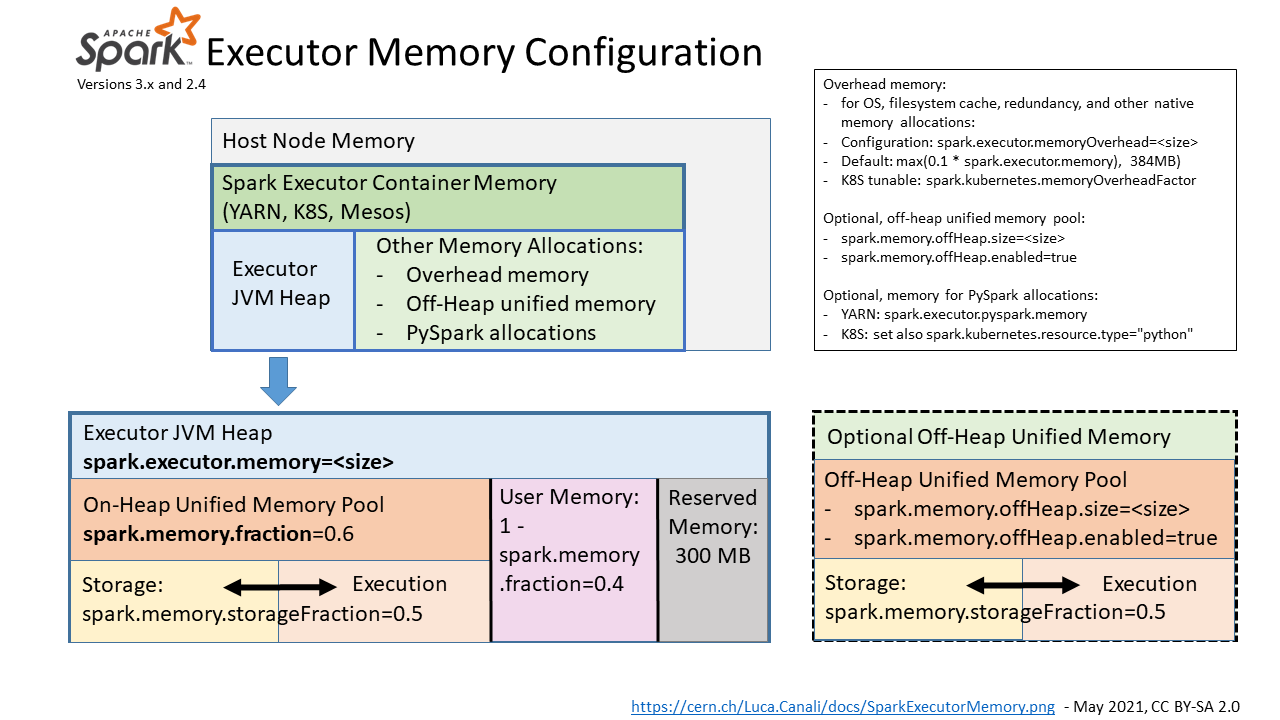
spark 统一内存池
Spark 任务使用的内存由 Spark 内存管理系统统一管理,从 executor 的 JVM 堆中分配。Unified memory 默认占用 60% JVM 堆大小。系统可以通过 spark.memory.fraction 配置。剩余 40% 的内存用于用户数据结构、Spark 内部元数据、防止 OOM 错误。
Spark 通过统一内存池管理执行、存储内存请求。执行和存储可以相互占用对方剩余内存资源。执行/存储的内存资源大小可以通过 spark.memory.storageFraction(默认为 0.5)调整,这就意味着执行内存资源占比默认为 。统一内存池也可以由堆外内存配置,相关配置参数为
spark.memory.offHeap、spark.memory.offHeap.enabled。
Spark 3.0 的内存监控
Spark 3.0 有两个关于内存监控的主要改进点:
- SPARK-23429:将 executor 内存指标添加到心跳并用 REST API 暴露
- SPARK-27189:将 executor 指标和内存使用检测添加到指标系统
使用 REST API 获取内存使用情况和峰值
REST API:https://spark.apache.org/docs/latest/monitoring.html#rest-api
WebUI URL + /api/v1/applications/
executor 内存指标如下所示:
"peakMemoryMetrics" : {"JVMHeapMemory" : 29487812552,"JVMOffHeapMemory" : 149957200,"OnHeapExecutionMemory" : 12458956272,"OffHeapExecutionMemory" : 0,"OnHeapStorageMemory" : 83578970,"OffHeapStorageMemory" : 0,"OnHeapUnifiedMemory" : 12540212490,"OffHeapUnifiedMemory" : 0,"DirectPoolMemory" : 66809076,"MappedPoolMemory" : 0,"ProcessTreeJVMVMemory" : 38084534272,"ProcessTreeJVMRSSMemory" : 36998328320,"ProcessTreePythonVMemory" : 0,"ProcessTreePythonRSSMemory" : 0,"ProcessTreeOtherVMemory" : 0,"ProcessTreeOtherRSSMemory" : 0,"MinorGCCount" : 561,"MinorGCTime" : 49918,"MajorGCCount" : 0,"MajorGCTime" : 0},
Spark 作业性能数据大盘
Spark 指标系统为 Spark 数据大盘提供数据源。Grafana 对数据源进行可视化,优点如下:
- 可以实时查看指标值的变化,并将它们与工作负载的其他关键指标进行比较;
- 可以聚合指标进行检查或者深入 executor 级别的指标,可以帮助用户了解是否存在异常值;
- 例如,可以研究指标随时间的演变,了解工作负载的哪一部分在给定指标中产生了某些峰值。
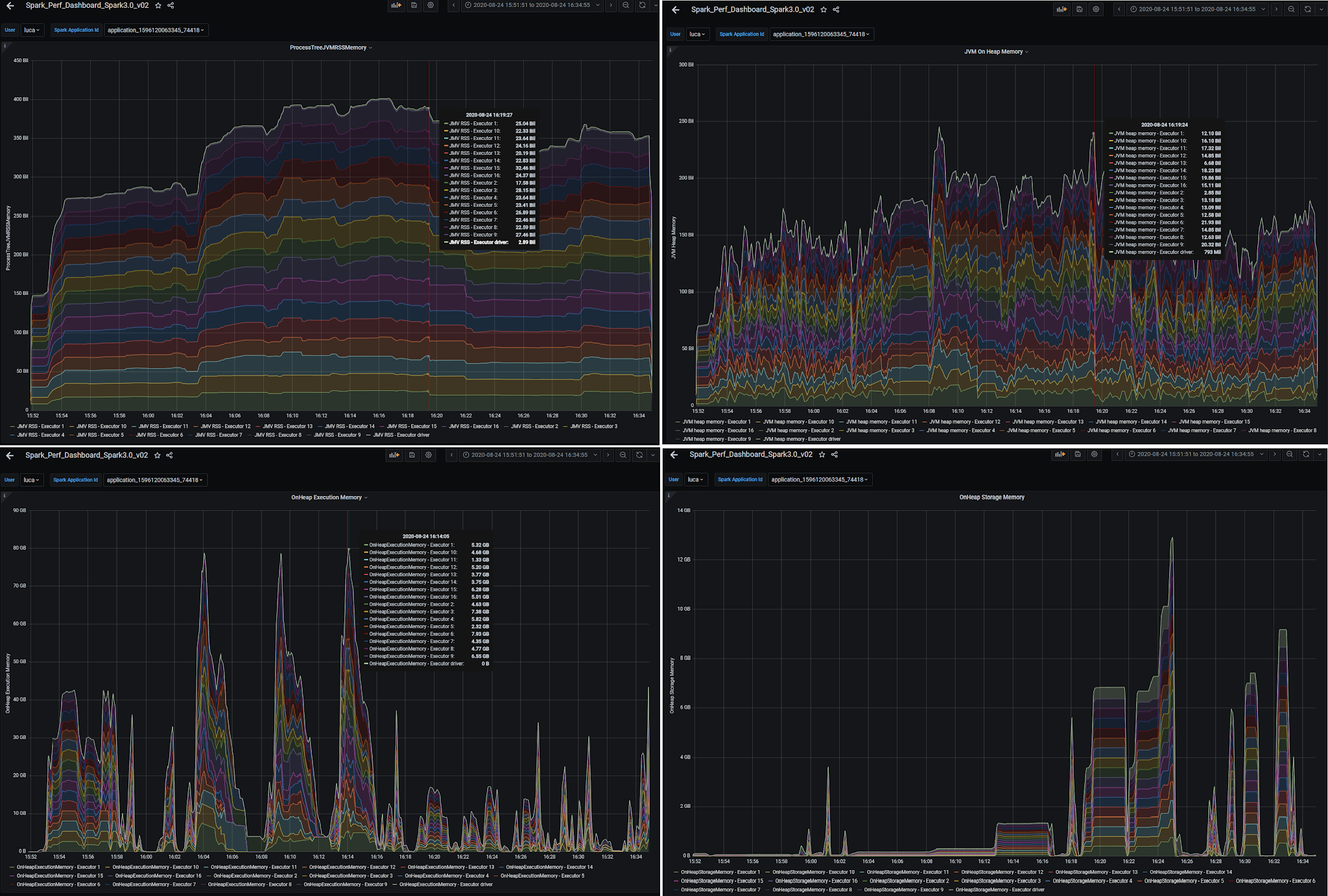
实验
- 使用 Spark 3.0 on YARN/Kubernetes
- Spark 性能数据大盘:配置、安装方式请参阅 https://github.com/cerndb/spark-dashboard
- 提交作业:TPCDS benchmark
bin/spark-shell --master yarn --num-executors 16 --executor-cores 8 \--driver-memory 4g --executor-memory 32g \--jars /home/luca/spark-sql-perf/target/scala-2.12/spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar \--conf spark.eventLog.enabled=false \--conf spark.sql.shuffle.partitions=512 \--conf spark.sql.autoBroadcastJoinThreshold=100000000 \--conf spark.executor.processTreeMetrics.enabled=true
import com.databricks.spark.sql.perf.tpcds.TPCDSTablesval tables = new TPCDSTables(spark.sqlContext, "/home/luca/tpcds-kit/tools","1500")tables.createTemporaryTables("/project/spark/TPCDS/tpcds_1500_parquet_1.10.1", "parquet")val tpcds = new com.databricks.spark.sql.perf.tpcds.TPCDS(spark.sqlContext)val experiment = tpcds.runExperiment(tpcds.tpcds2_4Queries)
总结
正确调整 Spark 作业内存配置大小很重要,提高了多租户环境中性能、稳定性和资源利用率。Spark 3.0 对内存监控有重要改进,分析峰值内存使用情况为解决 OOM 错误和 Spark 作业内存大小调整提供了重要依据。
参考资料
Talks:
- Metrics-Driven Tuning of Apache Spark at Scale, Spark Summit 2018.
- Performance Troubleshooting Using Apache Spark Metrics, Spark Summit 2019
- Tuning Apache Spark for Large-Scale Workloads, Spark summit 2017
- Deep Dive: Apache Spark Memory Management, Spark Summit 2016.
- Understanding Memory Management In Spark For Fun And Profit, Spark Summit 2016.
Spark 文档和博客:
- Monitoring guide: REST API, Executor Task Metrics. Executor Metrics, Spark Metrics System
- Tuning guide: Memory Management Overview
- Apache Spark and off-heap memory
- A Performance Dashboard for Apache Spark
JIRAs:
Spark Code:

若有收获,就点个赞吧
0 人点赞
