表驱动法就是一种编程模式(scheme)——从表里面查找信息而不使用逻辑语句(if 和case)。事实上,凡是能通过逻辑语句来选择的事物,都可以通过查表来选择。对简单的情况而言,使用逻辑语句更为容易和直白。但随着逻辑链的越来越复杂,查表法也就愈发显得更具吸引力。
18.1 表驱动法使用总则
在适当的情况下,采用表驱动法,所生成的代码会比复杂的代码逻辑更简单、更容易修改,而且效率更高。
使用表驱动法的两个问题
- 怎样从表中查询条目
可以用一些数据来直接访问表,比如创建一个月份表,可以直接用一个下标从1到12的数组实现它
另外一些数据很难直接用于查表。例如,假设你希望按照社会安全号码来做数据分类,那么除非你可以承受在表里存放999-99-9999条记录。否则就不能使用社会安全号码直接查询表。你会被迫采用一种更复杂的方法,下面是从表里查询记录的方法- 直接访问
- 索引访问
- 阶梯访问
- 你应该在表里面存什么东西
- 查询出来的结果是数据
如果是这种情况,我们就可以直接将数据存储在表中。 - 查询出来的结果是动作
在这种情况下,你可以保存一个描述该动作的代码,或者,在有些语言里,你可以保存对实现该动作的子程序的引用。
- 查询出来的结果是数据
18.2 直接访问表
和所有的查询表一样,直接访问表代替了更为复杂的逻辑控制结构。之所以说它们是“直接访问”的,是因为你无需绕很多复杂的圈子就能够直接在表里找到你想要的信息
比如一个很简单的例子,今天星期几
// if-else实现const day = new Date().getDay()let day_zh = ''if (day === 0) {day_zh = '星期天'} else if (day === 1) {day_zh = '星期一'} else if (day === 2) {day_zh = '星期二'}...else {day_zh = '星期六'}// 或者用switch-caseswitch (day) {case 0:day_zh = '星期天'break;case 1:day_zh = '星期一'break;case 2:day_zh = '星期二'break;...default:day_zh = '星期六'}
实现同样功能的一种更简单、更容易修改的方法是将这些数据存到一张表里面
const week_zh_cn = ['星期天','星期一','星期二'...,'星期六']const day = new Date().getDay()const day_zh = week_zh_cn[day]
现在你无须再写那条长的 if 语句,只需要一条简单的数组访问语句就可以获取今天星期几。
构造查询键值
另外一个例子,计算医疗保险费率,这些费率是根据年龄来控制的。小于18岁的是200,18-65岁是300,65岁以上是500。
方法一:复制信息从而能直接使用键值
如果按照直接访问数组下标的方法来获取费率,假设最大年龄是100岁
const rateTable = [200, 200, 200, ..., 300, 300, ..., 500,...]const rate = rateTable[age]
优点:表自身结构非常简单,访问表的操作也很简单
缺点:复制生成的冗余信息会浪费空间,并且表中存在错误的可能性也增加了——真希望缺点仅仅是表中的冗余信息占用了空间。
方法二: 转换键值以使其能够直接使用
用一个函数将age转换成另一个数值,从而使其能像键值那样使用,在这个例子中,该函数必须把所有介于0-17之间的年龄转换成另外一个键值,比如17,同时把所有超过66的转换成另外一个键值,比如66。
const ageKey = max( min (66, age), 17)const rateTable = {17: 0.2, 30: 0.4, 66: 0.4}const rate = rateTable[ageKey]
通常提取键值数据不一定是像这个例子中的这么简单,所以需要将键值转换提取成独立的子程序,这样做可以避免在不同位置执行不同的转换,也使得转换操作修改起来更加容易。
18.3 索引访问表
有的时候,只用一个简单的数学运算还无法把 age 这样的数据转换成表键值。这类情况中的一部分可以通过索引访问的方法加以解决。
当你使用索引的时候,先用一个基本类型的数据从一张索引表中查出一个键值,然后再拿这个键值查出主数据。
例子:
假设有一家商店有100种商品,每种商品都有一个四位数字的编号,范围是0000-9999。
这种情况下,如果使用编号键值直接查询一张描述商品信息的表,那么就要生成10000条记录的索引数组。该数组中除了与你商店中的货物标志相对应的100条记录外,其余记录都是空的。这些记录指向一个商品描述表。
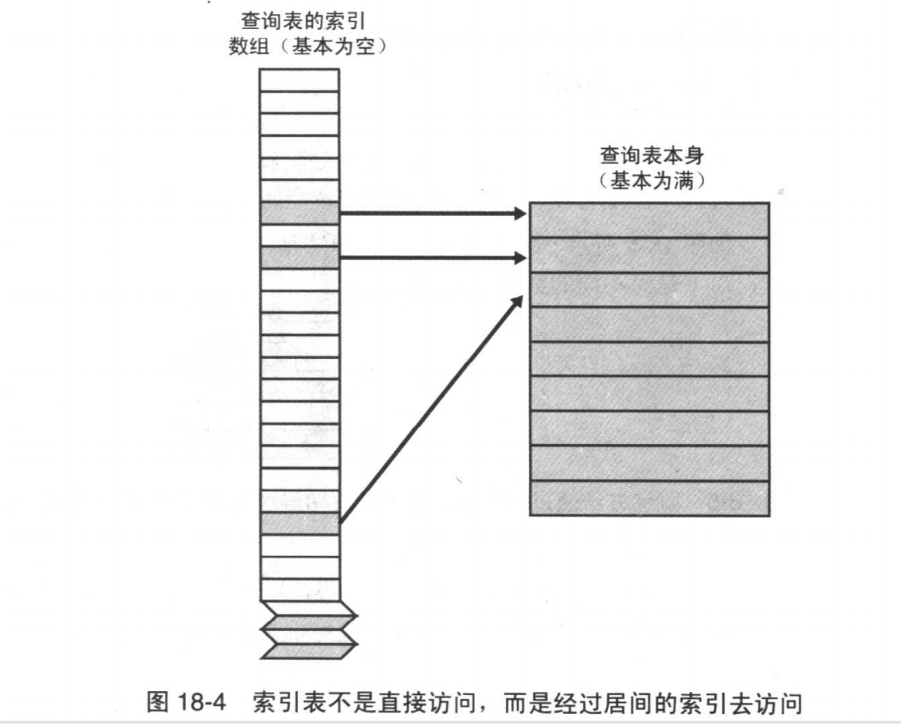
优点:
- 节省空间
如果主查询表中的每一条记录都很大,那么创建一个浪费了很多空间的索引数组所用的空间,就要比创建一个浪费了很多空间的主查询表所用的空间小很多。 - 灵活,根据不同的字段生成不同的索引表
即使使用了索引没有节省内存空间,操作位于索引中的记录有时也要比操作位于主表中的记录更方便更廉价。 - 可维护性
编写到表里面的数据比嵌入代码的数据更容易维护。
为了使这种灵活性最大化,可以把借助索引访问数据的代码提取成单独的子程序,然后在希望通过物品编号获取表键值的时候调用该子程序。
当需要修改表时,可以考虑更换这种索引访问技术,或者换用另外一种表查询的技术。
18.4 阶梯访问
这种访问方法不像索引结构那样直接,但是它要比索引访问方法节省空间。
阶梯结构的基本想法是,表中的记录对于不同的数据范围有效,而不是对不同的数据点有效。
例子:
简单的例子就是等级评定
按照考试分数分等级
简单的做法
let level = '优'if (score < 60 ) {level = '差'} else if (score < 80) {level = '中'} else if (score < 90) {level = '良'}
如果需要添加等级 60-70 之间,就需要改逻辑,逻辑简单的还好
let level = '优'if (score < 60 ) {level = '差'} else if (score < 70) {lebel = '一般'} else if (score < 80) {level = '中'} else if (score < 90) {level = '良'}
这时用阶梯查询就比较方便,而且扩展性也好
const levelTable = ['差', '中', '良', '优']const scoreCeilTable = [60, 80, 90, 100]function getLevel(score) {const levelIndex = scoreCeilTable.findIndex(scoreItem => {return score < scoreItem})return levelTable[levelIndex]}
优点:
- 非常灵活并容易修改
如果等级有变化,直接修改levelTable或scoreCeilTable中的数据就好,无须修改其他逻辑。
需要注意的细节
- 留心端点
确认你已经考虑到每一个阶梯区间的上界
注意不要把 < 误用为 <=。确认循环能够在找出最高一级的区间之后恰当的终止,同时确保正确的处理了区间的边界。 - 考虑用二分查找取代顺序查找
如果这个列表很大,顺序查找可能会成为效率的一种制约。 - 考虑用索引访问来取代阶梯技术
阶梯查找方法可能会比较耗时,如果执行速度很重要,你也许会愿意使用索引访问法来取代阶梯法,即以牺牲储存空间来换取速度

本章脑图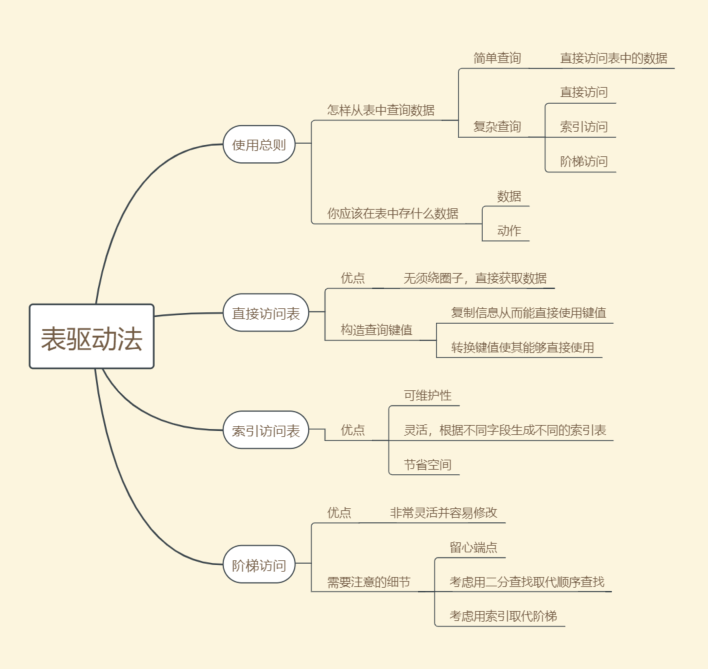

若有收获,就点个赞吧
0 人点赞
