

选择好的变量名的注意事项

以下代码是基于一项余额和一组开销来计算一位顾客的支付总额,那么你该使用哪个变量来为顾客那组新的花销打印账单呢?

最重要的命名的注意项
为变量命名时最重要的考虑事项是:该名字要完全、准确地描述出该变量所代表的事物。这种名字很容易阅读,因为其中并不包含晦涩的缩写,同时也没有歧义。因为它是对事物的完整描述,因此不会和事物混淆。
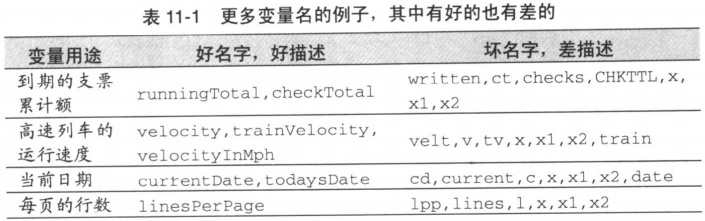
以问题为导向
一个好记的名字反映的通常都是问题,而不是解决方案。一个好的名字通常表达的是”什么”(what),而不是”如何”(how)。一般而言,如果一个名字反映了计算的某些方面而不是问题本身,那么它反映的就是“how”而非“what”了。请避免选取这样的名字,而应该在名字中反映出问题本身。
最适当的名字长度

变量名对作用域的影响
W.J.Hansen所做的一项研究表明,较长的名字适用于很少用到的变量或全局变量,较短的名字则适用于局部变量或循环变量。
对于全局命名空间中的名字加以限定词 如果你在全局命名空间中定义了一些变量(具名常量或类名等),那么请考虑你是否需要采用某种方式对全局命名空间进行划分,避免发生命名冲突。

变量名中的计算值限定词
很多程序都有表示计算记过的变量:总额、平均值、最大值等。如果要用到类似于Total、Sum、Average、Max、Record、String、Pointer这样的限定词来修改某个名字,那么记住把限定词加到名字最后。采用了这一规则,将避免由于同时在程序中使用totalRevenue和revenueTotal而产生歧义。这些名字语义上等价的,上述规则可以避免将他们当作不同的东西使用。总之,一致性可以提高可读性,简化维护工作。
把计算的量放在名字最后的这规则也有例外,那就是Num限定词的位置已经是约定俗成的。把Num放在变量名的开始位置代表一个总数:numCustomers表示的是员工的总数,Num放在变量名的结束位置代表一个下标:customerNum表示的是当前员工序号。这样使用Num会带来麻烦,因此最好的办法是避开这些问题,用Count或Total来代表员工的总数,用Index来指代某个特定的员工。这样customerCount代表员工的总数,customerIndex代表某个特定的员工。
变量名中的常用对仗词
对仗词的命名要准确。通过应用命名规则来提高对仗词使用的一致性,从而提高其可读性。以下是些常用的对仗词: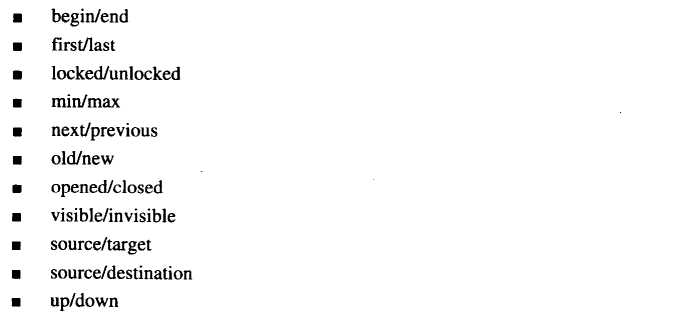
为特定类型的数据命名
为数据命名时,除了通常的考虑事项之外,为一些特定类型的数据命名还要求做出些特殊的考虑。本节将讲述与循环变量、状态变量、临时变量、布尔变量和具名常量有关的考虑事项。
为循环下标命名
如果一个变量只在循环之内使用,那么可以取i、j、k这样简短的名字: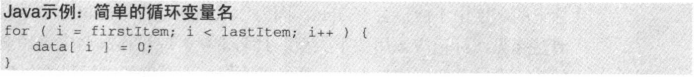
如果一个变量要在循环之外使用,那么就应该为它取个比i、j、k更有意义的名字。举个例子,如果你在从文件中读取距离,并且需要记下所读取记录的数量,那么类似于recordCount这样的名字就很适合:
如果循环不止一行,而是使用了多个嵌套循环,那么就应该给循环变量赋予更长的名字以提高可读性:
为状态变量命名
状态变量用于描述你的程序的状态,下面给出它的命名规则。
为状态变量取个比flag更好的名字 最好是把标记(flag)看做状态变量。标记中的名字不应该有flag,因为你从中丝毫看不出该标记是做什么的。为了清楚起见,标记应该用枚举类型、具名常量,或用作具名常量的全局变量来对其赋值,下面的例子中的标记的命名都很差:
下面是作用相同但更清晰的代码:
下面例子展示了如何使用具名常量和枚举类型来组织例子中的数值:

为临时变量命名
临时变量用于存储计算的中间结果,作为临时占位符,以及存储内务管理值,它们通常被赋予temp、x或者其他一些模糊且缺乏描述性的名字。由于这些变量被正式的赋予一种“临时”状态,因此程序员会倾向于比其他变量更为随意地对待这些变量,从而增加出错的可能。下面是个不好的例子:
下面例子显示了一种更好的做法:
为布尔变量命名

给布尔变量赋值隐含“真/假”含义的名字 像done和success这样就是很不错的布尔变量名,因为其状态要么是true要么是false。另一方面,像status和sourceFile这样的名字就是比较糟糕的布尔变量名,因为他们没有明确的true或false。为了取得更好的效果,应该把status替换类似于error或者statusOk这样的名字,同时把sourceFile替换为sourceFileAvailable、sourceFileFound或者其他能体现该变量所代表含义的名字。
有些程序员喜欢在写的布尔变量名前加上Is。这样变量名就变成了一个问题:isDone? isError? isFound? isProcessingComplete? 用true或false回答问题也就给该变量给出了取值。但它的缺点之一就是降低了简单逻辑表达式的可读性:if(isFound)可读性要略差于if(found)
使用肯定的布尔变量名 否定的名字如notFound、notDone以及notSuccessful比较难阅读,特别是如果它们被求反:
if (notFound)
这样的名字应该替换为found、done或者processingComplete,然后再用适当的运算符求反。如果找到了想找的结果,那么就可以用found而不必些双重否定的notFound
为枚举类型命名
在使用枚举类型时,可以通过使用组前缀,如Color,Planet或者
Month_来明确表示该类型的成员都属于同一组。下面举一些通过前缀来雀帝你个枚举类型元素的例子:
为常量命名

命名规则的力量
要有规则

采用任何一项规则都要好于没有规则。规则可能是武断的,命名规则的威力并非来源于你所采取的某个特定规则,而是来源于以下事实:规则的存在为你的代码增加了结构,减少了你需要考虑的事情。
何时采用命名规则

正式程度

非正式命名规则
与语言无关的命名规则的指导原则
区分变量名和子程序名字 本书所采用的命名规则要求变量名和对象名以小写字母开始,子程序名以大写字母开始:variableName对RoutineName()
区分类和对象 类名字与对象名字——或者类型与该类型的变量——之间的关系比较棘手。有很多标准的方案可用,如下例所示:
每一种可选方案都不是十全十美的。本书代码采用的是第五种方案,因为当不要求代码的阅读者熟悉一种不太直观的命名规则时,这种规则则做是最容易理解的。


与语言相关的命名规则的指导原则



命名规则示例

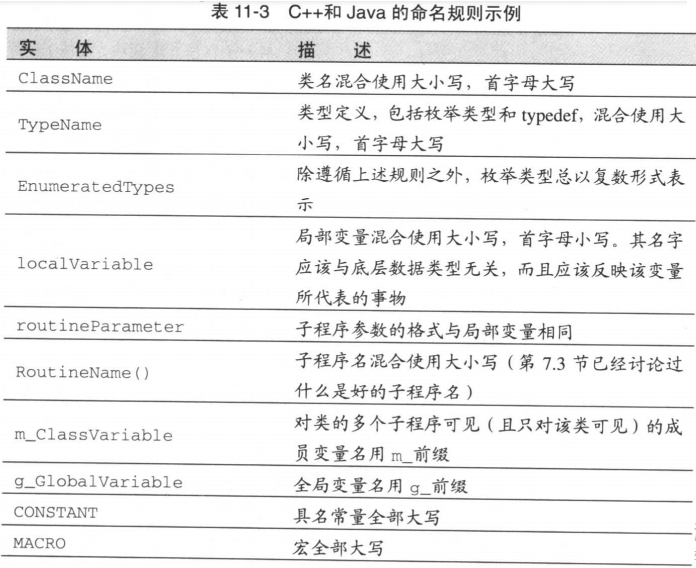
标准前缀
用户自定义类型
UDT缩写可以标识命名对象或变量的数据类型。UDT缩写可以被用于表示像窗体、区域屏幕以及字体一类的实体。UDT缩写通常不会表示任何由编程语言所提供的静置数据类型。下面表11-6列出一份UDT示例,你可能在开发文字处理程序的时候用的到它们。

语义前缀


标准前缀的优点

创建具备可读性的短名字

缩写的一般指导原则
下面是几项用于缩写的指导原则。其中的一些原则彼此冲突,所以不要试图同时应用所以规则。
语音缩写
有关缩写的评论
在创建缩写的时候,会有很多的陷阱在等着你。下面是一些能够用来避免犯错的规则。

应该避免使用的名字
下面就那些变量名应该避免给出指导原则。
避免使用令人误解的名字或缩写 要确保名字的含义是明确的。例如,常用FALSE当作TRUE的反义词,如果用它做“Fig and Almond Season”的缩写就很糟糕了。
避免使用具有相似含义的名字 如果能够交换两个变量的名字而不会妨碍对程序的理解吗,那么你就需要给这两个变量重新命名了。例如,input和inputValue, record和numRecords在语义上非常相似,如果把它们用在同一段代码中,就容易混淆它们,并且极有可能发生错误。
避免使用具有不同含义但却有相似名字的变量 如果你有两个名字相似但含义不同变量,那么试着给其中一个变量重新命名,或者修改缩写。例如,clientRecs和clientReps这样的名字,只有一字之差,并且这字母很难被注意到。clientRecords和clientReports就比原来的名字好。
避免使用发音相似的名字 比如wrap和rap 当你试图和别人讨论代码的时候,同音异义字就产生麻烦。
避免在名字中使用数字 如果名字中的数字真的非常重要,就请使用数组来代替一组单个的变量。如果数组不合适,那么数字就更不适合。
避免在名字中拼错单词
避免使用英语中常常常常拼错的单词
不要仅靠大小写来区分变量名
避免使用多种自然语言
避免使用标准类型、变量和子程序的名字
不要使用与变量含义完全无关的名字
避免在名字包含易混淆的字符
核对表




要点


若有收获,就点个赞吧
0 人点赞
