Apache Spark: Reading Data | JSON Files
Preparing for Databricks Certified Associate Developer for Apache Spark 2.4 with Python 3
Notice: This is a personal learning note of DB105.
Reading Data - JSON Files
Technical Accomplishments:
Read data from:
- JSON without a Schema
- JSON with a Schema
JSON Lines
Much like the CSV reader, the JSON reader also assumes…
- That there is one JSON object per line and…
- That it’s delineated by a new-line.
This format is referred to as JSON Lines or newline-delimited JSON
More information about this format can be found at http://jsonlines.org.
Note: Spark 2.2 was released on July 11th 2016. With that comes File IO improvements for CSV & JSON, but more importantly, Support for parsing multi-line JSON and CSV files. You can read more about that (and other features in Spark 2.2) in the Databricks Blog.
Take a look at the data.
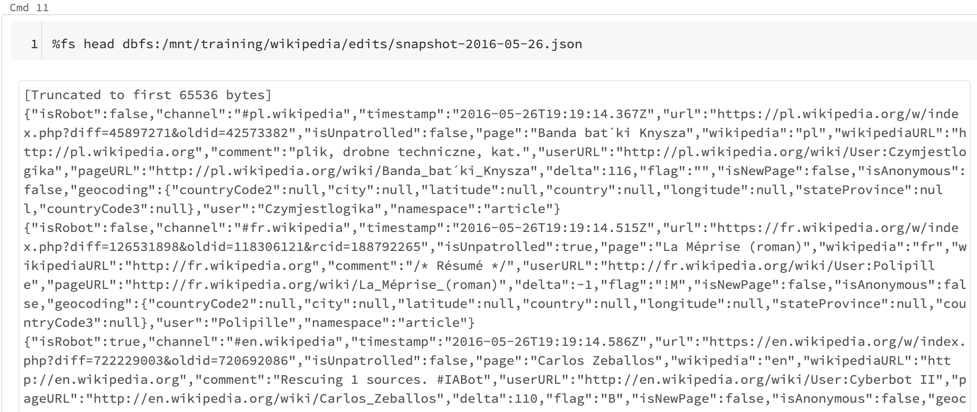

With our DataFrame created, we can now take a peak at the data.
But to demonstrate a unique aspect of JSON data (or any data with embedded fields), we will first create a temporary view and then view the data via SQL:
wikiEditsDF.createOrReplaceTempView("wiki_edits")
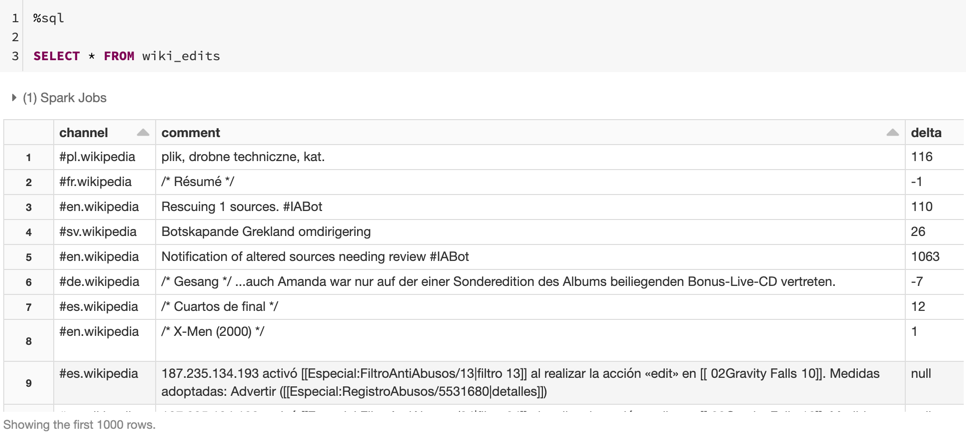
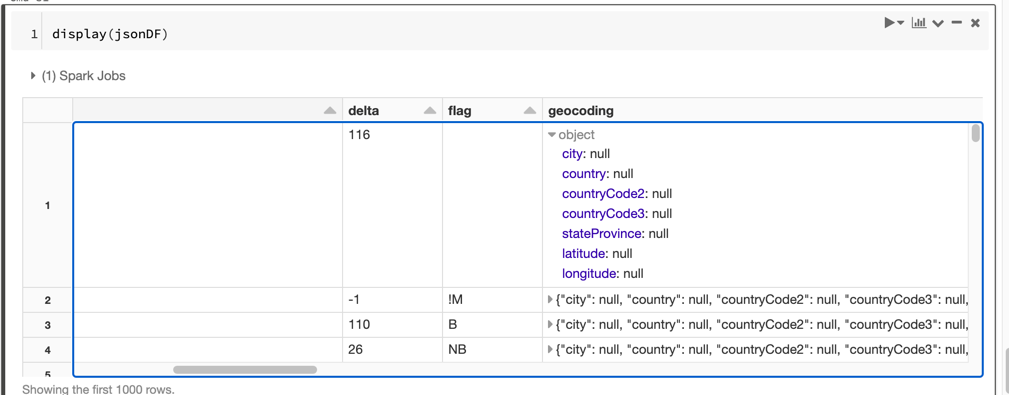
Notice the geocoding column has embedded data.
You can expand the fields by clicking the right triangle in each row.
But we can also reference the sub-fields directly as we see in the following SQL statement:
SELECT channel, page, geocoding.city, geocoding.latitude, geocoding.longitudeFROM wiki_editsWHERE geocoding.city IS NOT NULL
Review: Reading from JSON w/ InferSchema
While there are similarities between reading in CSV & JSON there are some key differences:
- We only need one job even when inferring the schema.
- There is no header which is why there isn’t a second job in this case - the column names are extracted from the JSON object’s attributes.
- Unlike CSV which reads in 100% of the data, the JSON reader only samples the data.
Note: In Spark 2.2 the behavior was changed to read in the entire JSON file.
 Reading from JSON w/ User-Defined Schema
Reading from JSON w/ User-Defined Schema
To avoid the extra job, we can (just like we did with CSV) specify the schema for the DataFrame.
Step #1 - Create the Schema
Compared to our CSV example, the structure of this data is a little more complex.
Note that we can support complex data types as seen in the field geocoding.
# Required for StructField, StringType, IntegerType, etc.from pyspark.sql.types import *jsonSchema = StructType([StructField("channel", StringType(), True),StructField("comment", StringType(), True),StructField("delta", IntegerType(), True),StructField("flag", StringType(), True),StructField("geocoding", StructType([StructField("city", StringType(), True),StructField("country", StringType(), True),StructField("countryCode2", StringType(), True),StructField("countryCode3", StringType(), True),StructField("stateProvince", StringType(), True),StructField("latitude", DoubleType(), True),StructField("longitude", DoubleType(), True)]), True),StructField("isAnonymous", BooleanType(), True),StructField("isNewPage", BooleanType(), True),StructField("isRobot", BooleanType(), True),StructField("isUnpatrolled", BooleanType(), True),StructField("namespace", StringType(), True),StructField("page", StringType(), True),StructField("pageURL", StringType(), True),StructField("timestamp", StringType(), True),StructField("url", StringType(), True),StructField("user", StringType(), True),StructField("userURL", StringType(), True),StructField("wikipediaURL", StringType(), True),StructField("wikipedia", StringType(), True)])
That was a lot of typing to get our schema!
For a small file, manually creating the schema may not be worth the effort.
However, for a large file, the time to manually create the schema may be worth the trade off of a really long infer-schema process.
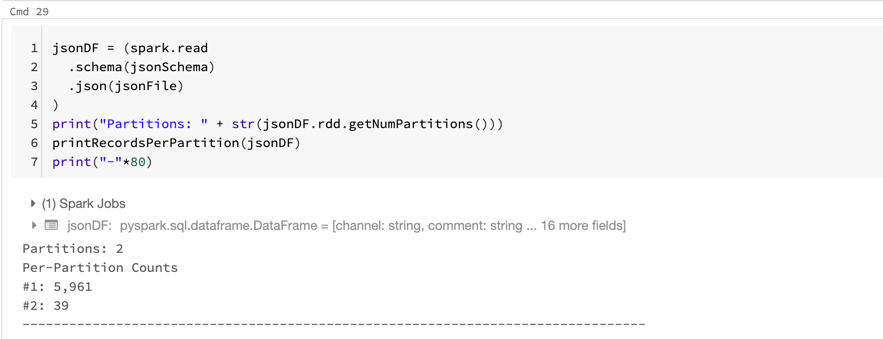
Step #2 - Read in the JSON
Next, we will read in the JSON file and once again print its schema.
(spark.read.schema(jsonSchema).json(jsonFile).printSchema())
Review: Reading from JSON w/ User-Defined Schema
- Just like CSV, providing the schema avoids the extra jobs.
- The schema allows us to rename columns and specify alternate data types.
- Can get arbitrarily complex in its structure.!

若有收获,就点个赞吧
0 人点赞
